I and countless others have spent the last several years referring to the National Institute of Standards and Technology’s Face Recognition Vendor Test, or FRVT. I guess some people have spent almost a quarter century referring to FRVT, because the term has been in use since 1999.
Starting now, you’re not supposed to use the FRVT acronym any more.
To bring clarity to our testing scope and goals, what was formerly known as FRVT has been rebranded and split into FRTE (Face Recognition Technology Evaluation) and FATE (Face Analysis Technology Evaluation). Tracks that involve the processing and analysis of images will run under the FATE activity, and tracks that pertain to identity verification will run under FRTE. All existing participation and submission procedures remain unchanged.
The change actually makes sense, since tasks such as age estimation and presentation attack detection (liveness detection) do not directly relate to the identification of individuals.
Us old folks just have to get used to the change.
I just hope that the new “FATE” acronym doesn’t mean that some algorithms are destined to perform better than others.
What’s more, these results change on a monthly basis, so it’s quite possible that the #1 vendor in some category in February 2022 was no longer than #1 vendor in March 2022. (And if your company markets years-old FRVT results, stop it!)
This is the August 15, 2023 peek at three ways to slice and dice the NIST FRVT results.
And a bunch of vendors will be mad at me because I didn’t choose THEIR preferred slicing and dicing, or their ways to exclude results (not including Chinese algorithms, not including algorithms used in surveillance, etc.). The mad vendors can write their own blog posts (or ask Bredemarket to ghostwrite them on their behalf).
NIST FRVT 1:1, VISABORDER
The phrase “NIST FRVT 1:1, VISABORDER” is shorthand for the NIST one-to-one version of the Face Recognition Vendor Test, using the VISABORDER probe and gallery data. This happens to be the default way in which NIST sorts the 1:1 accuracy results, but of course you can sort them against any other probe/gallery combination, and get a different #1 vendor.
As of August 15, the top two accuracy algorithms for VISABORDER came from Cloudwalk. Here are all of the top ten.
But NIST doesn’t just measure accuracy for a bunch of different probe-target combinations. It also measures performance, since the most accurate algorithm in the world won’t do you any good if it takes forever to compare the face templates.
One caveat regarding these measures is that NIST conducts the tests on a standardized set of equipment, so that results between vendors can be compared. This is important to note, because a comparison that takes 103 milliseconds on NIST’s equipment will yield a different time on a customer’s equipment.
One of the many performance measures is “Comparison Time (Mate).” There is also a performance measure for “Comparison Time (Non-mate).”
So in this test, the fastest vendor algorithm comes from Trueface. Again, here are the top 10.
Now I know what some of you are saying. “John,” you say, “the 1:1 test only measures a comparison against one face against one other face, or what NIST calls verification. What if you’re searching against a database of faces, or identification?”
Well, NIST has a 1:N test to measure that particular use case. Or use cases, because again you can slice and dice the results in so many different ways.
When looking at accuracy, the default NIST 1:N sort is by:
Probe images from the BORDER database.
Gallery images from a 1,600,000 record VISA database.
Cloudwalk happens to be the #1 vendor in this slicing and dicing of the test. Here are the top ten.
The usual cautions apply that everyone, including NIST, emphasizes that these test results do not guarantee similar results in an operational environment. Even if the algorithm author ported its algorithm to an operational system with absolutely no changes, the operational system will have a different hardware configuration and will have different data.
For example, none of the NIST 1:N tests use databases with more than 12 million records. Even 20 years ago, Behnam Bavarian correctly noted that biometric databases would eventually surpass hundreds of millions of records, or even billions of records. There is no way that NIST could assemble a test database that large.
Does your firm fight crooks who try to fraudulently use synthetic identities? If so, how do you communicate your solution?
This post explains what synthetic identities are (with examples), tells four ways to detect synthetic identities, and closes by providing an answer to the communication question.
While this post is primarily intended for identity firms who can use Bredemarket’s marketing and writing services, anyone else who is interested in synthetic identities can read along.
What are synthetic identities?
To explain what synthetic identities are, let me start by telling you about Jason Brown.
Jason Brown wasn’t Jason Brown
You may not have heard of him unless you lived in Atlanta, Georgia in 2019 and lived near the apartment he rented.
Jason Brown’s renting of an apartment isn’t all that unusual.
If you were to visit Brown’s apartment in February 2019, you would find credit cards and financial information for Adam M. Lopez and Carlos Rivera.
Now that’s a little unusual, especially since Lopez and Rivera never existed.
For that matter, Jason Brown never existed either.
A Georgia man was sentenced Sept. 1 (2022) to more than seven years in federal prison for participating in a nationwide fraud ring that used stolen social security numbers, including those belonging to children, to create synthetic identities used to open lines of credit, create shell companies, and steal nearly $2 million from financial institutions….
Cato joined conspiracies to defraud banks and illegally possess credit cards. Cato and his co-conspirators created “synthetic identities” by combining false personal information such as fake names and dates of birth with the information of real people, such as their social security numbers. Cato and others then used the synthetic identities and fake ID documents to open bank and credit card accounts at financial institutions. Cato and his co-conspirators used the unlawfully obtained credit cards to fund their lifestyles.
Talking about synthetic identity at Victoria Gardens
Here’s a video that I created on Saturday that describes, at a very high level, how synthetic identities can be used fraudulently. People who live near Rancho Cucamonga, California will recognize the Victoria Gardens shopping center, proof that synthetic identity theft can occur far away from Georgia.
Note that synthetic identity theft different from stealing someone else’s existing identity. In this case, a new identity is created.
So how do you catch these fraudsters?
Catching the identity synthesizers
If you’re renting out an apartment, and Jason Brown shows you his driver’s license and provides his Social Security Number, how can you detect if Brown is a crook? There are four methods to verify that Jason Brown exists, and that he’s the person renting your apartment.
Method One: Private Databases
One way to check Jason Brown’s story is to perform credit checks and other data investigations using financial databases.
Did Jason Brown just spring into existence within the past year, with no earlier credit record? That seems suspicious.
Does Jason Brown’s credit record appear TOO clean? That seems suspicious.
Does Jason Brown share information such as a common social security number with other people? Are any of those other identities also fraudulent? That is DEFINITELY suspicious.
This is one way that many firms detect synthetic identities, and for some firms it is the ONLY way they detect synthetic identities. And these firms have to tell their story to their prospects.
If your firm offers a tool to verify identities via private databases, how do you let your prospects know the benefits of your tool, and why your solution is better than all other solutions?
Method Two: Check That Driver’s License (or other government document)
What about that driver’s license that Brown presented? There are a wide variety of software tools that can check the authenticity of driver’s licenses, passports, and other government-issued documents. Some of these tools existed back in 2019 when “Brown” was renting his apartment, and a number of them exist today.
Maybe your firm has created such a tool, or uses a tool from a third party.
If your firm offers this capability, how can your prospects learn about its benefits, and why your solution excels?
Method Three: Check Government Databases
Checking the authenticity of a government-issued document may not be enough, since the document itself may be legitimate, but the implied credentials may no longer be legitimate. For example, if my California driver’s license expires in 2025, but I move to Minnesota in 2023 and get a new license, my California driver’s license is no longer valid, even though I have it in my possession.
Why not check the database of the Department of Motor Vehicles (or the equivalent in your state) to see if there is still an active driver’s license for that person?
The American Association of Motor Vehicle Administrators (AAMVA) maintains a Driver’s License Data Verification (DLDV) Service in which participating jurisdictions allow other entities to verify the license data for individuals. Your firm may be able to access the DLDV data for selected jurisdictions, providing an extra identity verification tool.
If your firm offers this capability, how can your prospects learn where it is available, what its benefits are, and why it is an important part of your solution?
Method Four: Conduct the “Who You Are” Test
There is one more way to confirm that a person is real, and that is to check the person. Literally.
If someone on a smartphone or videoconference says that they are Jason Brown, how do you know that it’s the real Jason Brown and not Jim Smith, or a previous recording or simulation of Jason Brown?
This is where tools such as facial recognition and liveness detection come to play.
You can ensure that the live face matches any face on record.
You can also confirm that the face is truly a live face.
In addition to these two tests, you can compare the face against the face on the presented driver’s license or passport to offer additional confirmation of true identity.
Now some companies offer facial recognition, others offer liveness detection, others match the live face to a face on a government ID, and many companies offer two or three of these capabilities.
One more time: if your firm offers these capabilities—either your own or someone else’s—what are the benefits of your algorithms? (For example, are they more accurate than competing algorithms? And under what conditions?) And why is your solution better than the others?
This is for the firms who fight synthetic identities
While most of this post is of general interest to anyone dealing with synthetic identities, this part of this post is specifically addressed to identity and biometric firms who provide synthetic identity-fighting solutions.
When you communicate about your solutions, your communicator needs to have certain types of experience.
Industry experience. Perhaps you sell your identity solution to financial institutions, or educational institutions , or a host of other industries (gambling/gaming, healthcare, hospitality, retailers, or sport/concert venues, or others). You need someone with this industry experience.
Solution experience. Perhaps your communications require someone with 29 years of experience in identity, biometrics, and technology marketing, including experience with all five factors of authentication (and verification).
Communication experience. Perhaps you need to effectively communicate with your prospects in a customer focused, benefits-oriented way. (Content that is all about you and your features won’t win business.)
If you haven’t read a Bredemarket blog post before, or even if you have, you may not realize that this post is jam-packed with additional information well beyond the post itself. This post alone links to the following Bredemarket posts and other content. You may want to follow one or more of the 13 links below if you need additional information on a particular topic:
Here’s my latest brochure for the Bredemarket 400 Short Writing Service, my standard package to create your 400 to 600 word blog posts and LinkedIn articles. Be sure to check the Bredemarket 400 Short Writing Service page for updates.
Basically, I had gone through great trouble to document that Bredemarket would NOT take identity work, so I had to reverse a lot of pages to say that Bredemarket WOULD take identity work.
I may have found a few additional pages after June 1, but eventually I reached the point where everything on the Bredemarket website was completely and totally updated, and I wouldn’t have to perform any other changes.
You can predict where this is going.
Who I…was
Today it occurred to me that some of the readers of the LinkedIn Bredemarket page may not know the person behind Bredemarket, so I took the opportunity to share Bredemarket’s “Who I Am” web page on the LinkedIn page.
So yes, this biometric content marketing expert/identity content marketing expert IS available for your content marketing needs. If you’re interested in receiving my help with your identity written content, contact me.
I know that I’m the guy who likes to say that it’s all semantics. After all, I’m the person who has referred to five-page long documents as “battlecards.”
But sometimes the semantics are critically important. Take the terms “factors” and “modalities.” On the surface they sound similar, but in practice there is an extremely important difference between factors of authentication and modalities of authentication. Let’s discuss.
What is a factor?
To answer the question “what is a factor,” let me steal from something I wrote back in 2021 called “The five authentication factors.”
Something You Know. Think “password.” And no, passwords aren’t dead. But the use of your mother’s maiden name as an authentication factor is hopefully decreasing.
Something You Have. I’ve spent much of the last ten years working with this factor, primarily in the form of driver’s licenses. (Yes, MorphoTrak proposed driver’s license systems. No, they eventually stopped doing so. But obviously IDEMIA North America, the former MorphoTrust, has implemented a number of driver’s license systems.) But there are other examples, such as hardware or software tokens.
Something You Are. I’ve spent…a long time with this factor, since this is the factor that includes biometrics modalities (finger, face, iris, DNA, voice, vein, etc.). It also includes behavioral biometrics, provided that they are truly behavioral and relatively static.
Something You Do. The Cybersecurity Man chose to explain this in a non-behavioral fashion, such as using swiping patterns to unlock a device. This is different from something such as gait recognition, which supposedly remains constant and is thus classified as behavioral biometrics.
Somewhere You Are. This is an emerging factor, as smartphones become more and more prevalent and locations are therefore easier to capture. Even then, however, precision isn’t always as good as we want it to be. For example, when you and a few hundred of your closest friends have illegally entered the U.S. Capitol, you can’t use geolocation alone to determine who exactly is in Speaker Pelosi’s office.
(By the way, if you search the series of tubes for reading material on authentication factors, you’ll find a lot of references to only three authentication factors, including references from some very respectable sources. Those sources are only 60% right, since they leave off the final two factors I listed above. It’s five factors of authentication, folks. Maybe.)
The one striking thing about the five factors is that while they can all be used to authenticate (and verify) identities, they are inherently different from one another. The ridges of my fingerprint bear no relation to my 16 character password, nor do they bear any relation to my driver’s license. These differences are critical, as we shall see.
What is a modality?
In identity usage, a modality refers to different variations of the same factor. This is most commonly used with the “something you are” (biometric) factor, but it doesn’t have to be.
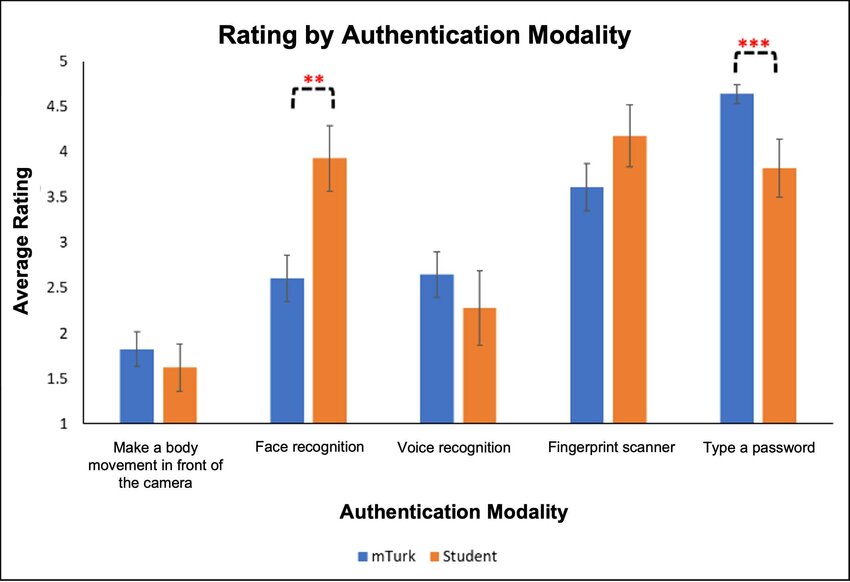
[M]any businesses and individuals (are adopting) biometric authentication as it been established as the most secure authentication method surpassing passwords and pins. There are many modalities of biometric authentication to pick from, but which method is the best?
After looking at fingerprints, faces, voices, and irises, Aware basically answered its “best” question by concluding “it depends.” Different modalities have their own strengths and weaknesses, depending upon the use case. (If you wear thick gloves as part of your daily work, forget about fingerprints.)
ID R&D goes a step further and argues that it’s best to use multimodal biometrics, in which the two biometrics are face and voice. (By an amazing coincidence, ID R&D offers face and voice solutions.)
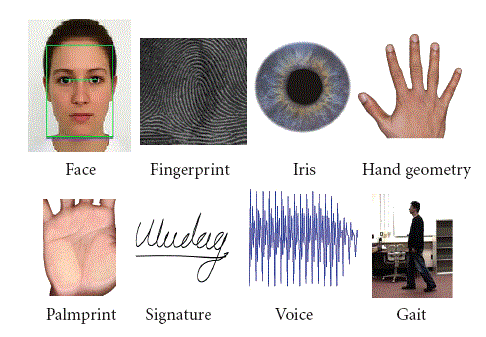
The three modalities in the middle—face, voice, and fingerprint—are all clearly biometric “something you are” modalities.
But the modality on the left, “Make a body movement in front of the camera,” is not a biometric modality (despite its reference to the body), but is an example of “something you do.”
Passwords, of course, are “something you know.”
In fact, each authentication factor has multiple modalities.
For example, a few of the modalities associated with “something you have” include driver’s licenses, passports, hardware tokens, and even smartphones.
Why multifactor is (usually) more robust than multimodal
Modalities within a single authentication factor are more closely related than modalities within multiple authentication factors. As I mentioned above when talking about factors, there is no relationship between my fingerprint, my password, and my driver’s license. However, there is SOME relationship between my driver’s license and my passport, since the two share some common information such as my legal name and my date of birth.
What does this mean?
If I’ve fraudulently created a fake driver’s license in your name, I already have some of the information that I need to create a fake passport in your name.
If I’ve fraudulently created a fake iris, there’s a chance that I might already have some of the information that I need to create a fake face.
However, if I’ve bought your Coinbase password on the dark web, that doesn’t necessarily mean that I was able to also buy your passport information on the dark web (although it is possible).
Can an identity content marketing expert help you navigate these issues?
As you can see, you need to be very careful when writing about modalities and factors.
You need a biometric content marketing expert who has worked with many of these modalities.
Actually, you need an identity content marketing expert who has worked with many of these factors.
So if you are with an identity company and need to write a blog post, LinkedIn article, white paper, or other piece of content that touches on multifactor and multimodal issues, why not engage with Bredemarket to help you out?
If you’re interested in receiving my help with your identity written content, contact me.
I didn’t either. Frankly, I didn’t even work in biometrics professionally until I was in my 30s.
If you have a mad adult desire to become a biometric content marketing expert, here are five topics that I (a self-styled biometric content marketing expert) think you need to understand.
Topic One: Biometrics
Sorry to be Captain Obvious, but if you’re going to talk about biometrics you need to know what you’re talking about.
The days in which an expert could confine themselves to a single biometric modality are long past. Why? Because once you declare yourself an iris expert, someone is bound to ask, “How does iris recognition compare to facial recognition?”
And there are a number of biometric modalities. In addition to face and iris, the Biometrics Institute has cataloged a list of other biometric modalities, including fingerprints/palmprints, voice, DNA, vein, finger/hand geometry, and some more esoteric ones such as gait, keystrokes, and odor. (I wouldn’t want to manage the NIST independent testing for odor.)
As far as I’m concerned, the point isn’t to select the best biometric and ignore all the others. I’m a huge fan of multimodal biometrics, in which a person’s identity is verified or authenticated by multiple biometric types. It’s harder to spoof multiple biometrics than it is to spoof a single one. And even if you spoof two of them, what if the system checks for odor and you haven’t spoofed that one yet?
Topic Two: All the other factors
In the same way that I don’t care for people who select one biometric and ignore the others, I don’t care for some in the “passwords are dead” crowd who go further and say, “Passwords are dead. Use biometrics instead.”
Although I admire the rhyming nature of the phrase.
If you want a robust identity system, you need to use multiple factors in identity verification and authentication.
Something you know.
Something you have.
Something you are (i.e. biometrics).
Something you do.
Somewhere you are.
Again, use of multiple factors protects against spoofing. Maybe someone can create a gummy fingerprint, but can they also create a fake passport AND spoof the city in which you are physically located?
It’s not enough to understand the technical ins and outs of biometric capture, matching, and review. You need to know how biometrics are used.
One-to-one vs. one-to-many. Is the biometric that you acquire only compared to a single biometric samples, or to a database of hundreds, thousands, millions, or billions of other biometric samples?
Markets. When I started in biometrics, I only participated in two markets: law enforcement (catch bad people) and benefits (get benefit payments to the right people). There are many other markets. Just recently I have written about financial identity and educational identity. I’ve worked with about a dozen other markets personally, and there are many more.
Use cases. Related to markets, you need to understand the use cases that biometrics can address. Taking the benefits example, there’s a use case in which a person enrolls for benefits, and the government agency wants to make sure that the person isn’t already enrolled under another name. And there’s a use cases when benefits are paid to make sure that the authorized recipient receives their benefits, and no one else receives their benefits.
Legal and privacy issues. It is imperative that you understand the legal ramifications that affect your chosen biometric use case in your locality. For example, if your house has a doorbell camera that uses “familiar face detection” to identify the faces of people that come to your door, and the people that come to your door are residents of the state of Illinois, you have a BIG BIPA (Biometric Information Privacy Act) problem.
Any identity content marketing expert or biometric content marketing expert worth their salt will understand these and related issues.
Topic Four: Content marketing
This is another Captain Obvious point. If you want to present yourself as a biometric contet marketing expert or identity content marketing expert, you have to have a feel for content marketing.
The definition of content marketing is simple: It’s the process of publishing written and visual material online with the purpose of attracting more leads to your business. These can include blog posts, pages, ebooks, infographics, videos, and more.
But content marketers need to be comfortable with creating at least one type of content.
Topic Five: How L-1 Identity Solutions came to be
Yes, an identity content marketing expert needs to thoroughly understand how L-1 Identity Solutions came to be.
I’m only half joking.
Back in the late 1990s and early 2000s (I’ll ignore FpVTE results for a moment), the fingerprint world in which I worked recognized four major vendors: Cogent, NEC, Printrak (later part of Motorola), and Sagem Morpho.
And then there were all these teeny tiny vendors that offered biometric and non-biometric solutions, including the fierce competitors Identix and Digital Biometrics, the fierce competitors Viisage and Visionics, and a bunch of other companies like Iridian.
Wel, there WERE all these teeny tiny vendors.
Until Bob LaPenta bought them all up and combined them into a single company, L-1 Identity Solutions. (LaPenta was one of the “Ls” in L-3, so he chose the name L-1 when he started his own company.)
So around 2008 the Big Four (including a post-FpVTE Motorola) became the Big Five, since L-1 Identity Solutions was now at the table with the big boys.
But then several things happened:
Motorola started selling off parts of itself. One of those parts, its Biometric Business Unit, was purchased by Safran (the company formed after Sagem and Snecma merged). This affected me because I, a Motorola employee, became an employee of MorphoTrak, the subsidiary formed when Sagem Morpho de facto acquired “Printrak” (Motorola’s Biometric Business Unit). So now the Big Five were the Big Four.
Make that the Big Three, because Safran also bought L-1 Identity Solutions, which became MorphoTrust. MorphoTrak and MorphoTrust were separate entities, and in fact competed against each other, so maybe we should say that the Big Four still existed.
Oh, and by the way, the independent company Cogent was acquired by 3M (although NEC considered buying it).
A few years later, 3M sold bits of itself (including the Cogent bit) to Gemalto.
Then in 2017, Advent International (which owned Oberthur) acquired bits of Safran (the “Morpho” part) and merged them with Oberthur to form IDEMIA. As a consequence of this, MorphoTrust de facto acquired MorphoTrak, ending the competition but requiring me to have two separate computers to access the still-separate MorphoTrust and MorphoTrak computer networks. (In passing, I have heard from two sources, but have not confirmed myself, that the possible sale of IDEMIA is on hold.)
Why do I mention all this? Because all these mergers and acquisitions have resulted in identity practitioners working for a dizzying number of firms.
As of August 2023, I myself have worked for five identity firms, but in reality four of the five are the same firm because the original Printrak International kept on getting acquired (Motorola, Safran, IDEMIA).
And that’s nothing. One of my former Printrak coworkers (R.M.) has also worked for Digital Biometrics (now part of IDEMIA), Cross Match Technologies (now part of ASSA ABLOY), Iridian (now part of IDEMIA), Datastrip, Creative Information Technology, AGNITiO, iTouch Biometrics, NDI Recognition Systems, iProov, and a few other firms here and there.
The point is that everybody knows everybody because everybody has worked with (and against) everybody. And with all the job shifts, it’s a regular Peyton Place.
Not sure which one is me, which one is R.M., and who the other people are.
Do you need an identity content marketing expert today?
Do you need someone who not only knows biometrics and content marketing, but also all the other factors, their uses, and even knows the tangled history of L-1?
Whether a student is attending a preschool, a graduate school, or something in between, the educational institution needs to know who is accessing their services. This post discusses the types of identity verification and authentication that educational institutions may employ.
Why do educational institutions need to verify and authenticate identities?
Whether little Johnny is taking his blanket to preschool, or Johnny’s mother is taking her research notes to the local university, educational institutions such as schools, colleges, and universities need to know who the attendees are. It doesn’t matter whether the institution has a physical campus, like Chaffey High School’s campus in the video above, or if the institution has a virtual campus in which people attend via their computers, tablets, or phones.
Access boils down to two questions:
Who is allowed within the educational institution?
Who is blocked from the educational institution?
Who is allowed within the educational institution?
Regardless of the type of institution, there are certain people who are allowed within the physical and/or virtual campus.
Students.
Instructors, including teachers, teaching assistants/aides, and professors.
Administrators.
Staff.
Parents of minor students (but see below).
Others.
All of these people are entitled to access to at least portions of the campus, with different people having access to different portions of the campus. (Students usually can’t enter the teacher’s lounge, and hardly anybody has full access to the computer system where grades are kept.)
Before anyone is granted campus privileges, they have to complete identity verification. This may be really rigorous, but in some cases it can’t be THAT rigorous (how many preschoolers have a government ID?). Often, it’s not rigorous at all (“Can you show me a water bill? Is this your kid? OK then.”).
Once an authorized individual’s identity is verified, they need to be authenticated when they try to enter the campus. This is a relatively new phenomenon, in response to security threats at schools. Again, this could be really rigorous. For example, when students at a University of Rhode Island dining hall want to purchase food from the cafeteria, many of then consent to have their fingerprints scanned.
But some authentiation is much less rigorous. In these cases, people merely show an ID (hopefully not a fake ID) to authenticate themselves, or a security guard says “I know Johnny.”
(Again, all this is new. Many years ago, I accompanied a former college classmate to a class at his new college, the College of Marin. If I had kept my mouth shut, the professor wouldn’t have known that an unauthenticated student was in his class.)
Who is blocked from the educational institution?
At the same time, there are people who are clearly NOT allowed within the physical and/or virtual campus. Some of these people can enter campus with special permission, while some are completely blocked.
Former students. Once a student graduates, their privileges are usually revoked, and they need special permission if they want to re-enter campus to visit teachers or friends. (Admittedly this isn’t rigorously enforced.)
Expelled students. Well, some former students have a harder time returning to campus. If you brought a gun on campus, it’s going to be much harder for you to re-enter.
Former instructors, administrators, and staff. Again, people who leave the employ of the institution may not be allowed back, and certain ones definitely won’t be allowed back.
Non-custodial parents of minor students. In some cases, a court order prohibits a natural parent from contact with their child. So the educational institutions are responsible for enforcing this court order and ensuring that the minor student leaves campus only with someone who is authorized to take the child.
Others.
So how do you keep these people off campus? There are two ways.
If they’re not on the allowlist, they can’t enter campus anyway. As part of the identity verification process for authorized individuals, there is a list of people who can enter the campus. By definition, the 8 billion-plus people who are not on that “allowlist” can’t get on campus without special permission.
Sometimes they can be put on a blocklist. Or maybe you want to KNOW that certain people can’t enter campus. The inverse of an allowlist, people who are granted access, is a blocklist, people who are prevented from getting access. (You may know “blocklist” by the older term “blacklist,” and “allowlist” by the older term “whitelist.” The Security Industry Association and the National Institute of Standards and Technology recommend updated terminology.)
There’s just one teeny tiny problem with blocklists. Sometimes they’re prohibited by law.
In some cases (but not in others), a person is required to give consent before they are enrolled in a biometric system. If you’re the ex-student who was expelled for brining a gun on campus, how motivated will you be to allow that educational institution to capture your biometrics to keep you off campus?
And yes, I realize that the expelled student’s biometrics were captured while they were a student, but once they were no longer a student, the institution would have on need to retain those biometrics. Unless they felt like it.
This situation becomes especially sticky for campuses that use video surveillance systems. Like Chaffey High School.
Chaffey High School, Ontario, California.
Now the mere installation of a video surveillance system does not (usually) result in legally prohibited behavior. It just depends upon what is done with the video.
If the video is not integrated with a biometric facial recognition system, there may not be an issue.
If Chaffey High School has its own biometric facial recognition system, then a whole host of legal factors may come into play.
If Chaffey High School does not have a biometric facial recognition system, but it gives the video to a police agency or private entity that does have a biometric facial recognition system, then some legal factors may emerge.
As you can see, educational identity is not as clear-cut as financial identity, both because financial institutions are more highly regulated and because blocklists are more controversial in educational identity. Vladimir Putin may not be able to open a financial account at a U.S. bank, but I bet he’d be allowed to enroll in an online course at a U.S. community college.
So if you are an educational institution or an identity firm who serves educational institutions, people who write for you need to know all of these nuances.
You need to provide the right information to your customers, and write it in a way that will motivate your customers to take the action you want them to take.
Speaking of motivating customers, are you with an identity firm or educational institution and need someone to write your marketing text?
Someone with 29 years of identity/biometric marketing experience?
Someone who understands that technological, organizational, and legal issues surrounding the use of identity solutions?
Someone who will explain why your customers should care about these issues, and the benefits a compliant solution provides to them?
If I can help you create your educational identity content, we need to talk.
Iris recognition continues to make the news. Let’s review what iris recognition is and its benefits (and drawbacks), why Apple made the news last month, and why Worldcoin is making the news this month.
What is iris recognition?
There are a number of biometric modalities that can identify individuals by “who they are” (one of the five factors of authentication). A few examples include fingerprints, faces, voices, and DNA. All of these modalities purport to uniquely (or nearly uniquely) identify an individual.
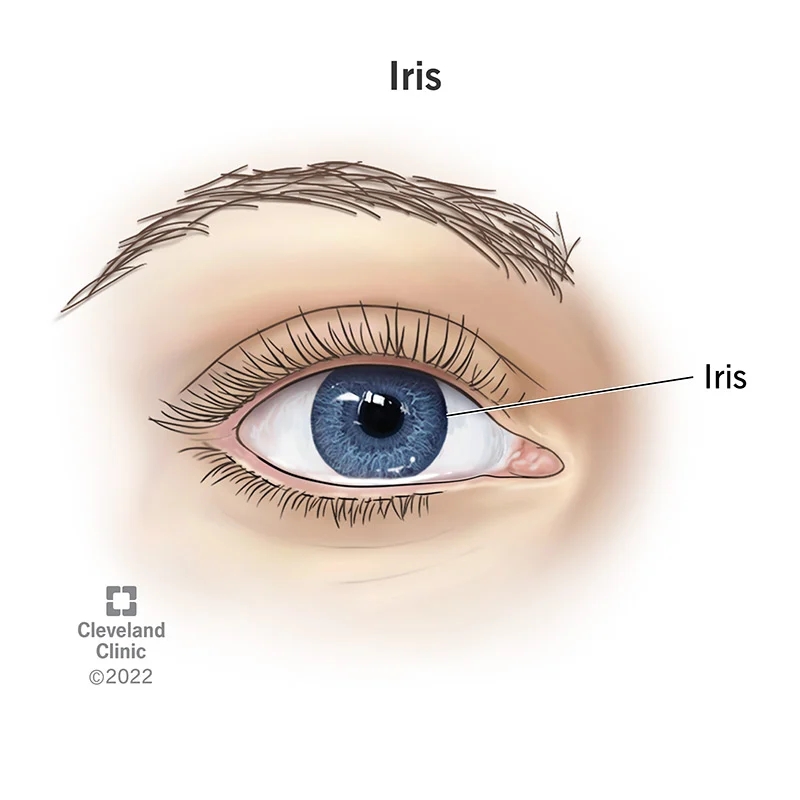
One other way to identify individuals is via the irises in their eyes. I’m not a doctor, but presumably the Cleveland Clinic employs medical professionals who are qualified to define what the iris is.
The iris is the colored part of your eye. Muscles in your iris control your pupil — the small black opening that lets light into your eye.
But why use irises rather than, say, fingerprints and faces? The best person to answer this is John Daugman. (At this point several of you are intoning, “John Daugman.” With reason. He’s the inventor of iris recognition.)
(I)ris patterns become interesting as an alternative approach to reliable visual recognition of persons when imaging can be done at distances of less than a meter, and especially when there is a need to search very large databases without incurring any false matches despite a huge number of possibilities. Although small (11 mm) and sometimes problematic to image, the iris has the great mathematical advantage that its pattern variability among different persons is enormous.
Daugman, John, “How Iris Recognition Works.” IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 1, JANUARY 2004. Quoted from page 21. (PDF)
Or in non-scientific speak, one benefit of iris recognition is that you know it is accurate, even when submitting a pair of irises in a one-to-many search against a huge database. How huge? We’ll discuss later.
Brandon Mayfield and fingerprints
Remember that Daugman’s paper was released roughly two months before Brandon Mayfield was misidentified in a fingerprint comparison. (Everyone now intone “Brandon Mayfield.”)
While some of the issues associated with Mayfield’s misidentification had nothing to do with forensic science (Al Jazeera spends some time discussing bias, and Itiel Dror also looked at bias post-Mayfield), this still shows that fingerprints are remarkably similar and that it takes care to properly identify people.
Police agencies, witnesses, and faces
And of course there are recent examples of facial misidentifications (both by police agencies and witnesses), again not necessarily forensic science related, and again showing the similarity of faces from two different people.
At the root of iris recognition’s accuracy is the data-richness of the iris itself. The IrisAccess system captures over 240 degrees of freedom or unique characteristics in formulating its algorithmic template. Fingerprints, facial recognition and hand geometry have far less detailed input in template construction.
Enough about claims. What about real results? The IREX 10 test, independently administered by the U.S. National Institute of Standards and Technology, measures the identification (one-to-many) accuracy of submitted algorithms. At the time I am writing this, the ten most accurate algorithms provide false negative identification rates (FNIR) between 0.0022 ± 0.0004 and 0.0037 ± 0.0005 when two eyes are used. (Single eye accuracy is lower.) By the time you see this, the top ten algorithms may have changed, because the vendors are always improving.
IREX10 two-eye accuracy, top ten algorithms as of July 28, 2023. (Link)
While the IREX10 one-to-many tests are conducted against databases of less than a million records, it is estimated that iris one-to-many accuracy remains high even with databases of a billion people—something we will return to later in this post.
Iris drawbacks
OK, so if irises are so accurate, why aren’t we dumping our fingerprint readers and face readers and just using irises?
In short, because of the high friction in capturing irises. You can use high-resolution cameras to capture fingerprints and faces from far away, but as of now iris capture usually requires you to get very close to the capture device.
Iris image capture circa 2020 from the U.S. Federal Bureau of Investigation. (Link)
Which I guess is better than the old days when you had to put your eye right up against the capture device, but it’s still not as friendly (or intrusive) as face capture, which can be achieved as you’re walking down a passageway in an airport or sports stadium.
Irises and Apple Vision Pro
So how are irises being used today? You may or may not have hard last month’s hoopla about the Apple Vision Pro, which uses irises for one-to-one authetication.
I’m not going to spend a ton of time delving into this, because I just discussed Apple Vision Pro in June. In fact, I’m just going to quote from what I already said.
In short, as you wear the headset (which by definition is right on your head, not far away), the headset captures your iris images and uses them to authenticate you.
It’s a one-to-one comparison, not the one-to-many comparison that I discussed earlier in this post, but it is used to uniquely identify an individual.
But iris recognition doesn’t have to be used for identification.
Irises and Worldcoin
“But wait a minute, John,” you’re saying. “If you’re not using irises to determine if a person is who they say they are, then why would anyone use irises?”
Over the past several years, I’ve analyzed a variety of identity firms. Earlier this year I took a look at Worldcoin….Worldcoin’s World ID emphasizes privacy so much that it does not conclusively prove a person’s identity (it only proves a person’s uniqueness)…
That’s the only thing that I’ve said about Worldcoin, at least publicly. (I looked at Worldcoin privately earlier in 2023, but that report is not publicly accessible and even I don’t have it any more.)
The Worldcoin Foundation today announced that Worldcoin, a project co-founded by Sam Altman, Alex Blania and Max Novendstern, is now live and in a production-grade state.
The launch includes the release of the World ID SDK and plans to scale Orb operations to 35+ cities across 20+ countries around the world. In tandem, the Foundation’s subsidiary, World Assets Ltd., minted and released the Worldcoin token (WLD) to the millions of eligible people who participated in the beta; WLD is now transactable on the blockchain….
“In the age of AI, the need for proof of personhood is no longer a topic of serious debate; instead, the critical question is whether or not the proof of personhood solutions we have can be privacy-first, decentralized and maximally inclusive,” said Worldcoin co-founder and Tools for Humanity CEO Alex Blania. “Through its unique technology, Worldcoin aims to provide anyone in the world, regardless of background, geography or income, access to the growing digital and global economy in a privacy preserving and decentralized way.”
Worldcoin does NOT positively identify people…but it can still pay you
A very important note: Worldcoin’s purpose is not to determine identity (that a person is who they say they are). Worldcoin’s purpose is to determine uniqueness: namely, that a person (whoever they are) is unique among all the billions of people in the world. Once uniqueness is determined, the person can get money money money with an assurance that the same person won’t get money twice.
Iris biometrics outperform other biometric modalities and already achieved false match rates beyond 1.2× 10−141.2×10−14 (one false match in one trillion[9]) two decades ago[10]—even without recent advancements in AI. This is several orders of magnitude more accurate than the current state of the art in face recognition.
I’ll admit that I previously thought that age estimation was worthless, but I’ve since changed my mind about the necessity for it. Which is a good thing, because the U.S. National Institute of Standards and Technology (NIST) is about to add age estimation to its Face Recognition Vendor Test suite.
What is age estimation?
Before continuing, I should note that age estimation is not a way to identify people, but a way to classify people. For once, I’m stepping out of my preferred identity environment and looking at a classification question. Not “gender shades,” but “get off my lawn” (or my tricycle).
Age estimation uses facial features to estimate how old a person is, in the absence of any other information such as a birth certificate. In a Yoti white paper that I’ll discuss in a minute, the Western world has two primary use cases for age estimation:
First, to estimate whether a person is over or under the age of 18 years. In many Western countries, the age of 18 is a significant age that grants many privileges. In my own state of California, you have to be 18 years old to vote, join the military without parental consent, marry (and legally have sex), get a tattoo, play the lottery, enter into binding contracts, sue or be sued, or take on a number of other responsibilities. Therefore, there is a pressing interest to know whether the person at the U.S. Army Recruiting Center, a tattoo parlor, or the lottery window is entitled to use the service.
Second, to estimate whether a person is over or under the age of 13 years. Although age 13 is not as great a milestone as age 18, this is usually the age at which social media companies allow people to open accounts. Thus the social media companies and other companies that cater to teens have a pressing interest to know the teen’s age.
Why was I against age estimation?
Because I felt it was better to know an age, rather than estimate it.
My opinion was obviously influenced by my professional background. When IDEMIA was formed in 2017, I became part of a company that produced government-issued driver’s licenses for the majority of states in the United States. (OK, MorphoTrak was previously contracted to produce driver’s licenses for North Carolina, but…that didn’t last.)
With a driver’s license, you know the age of the person and don’t have to estimate anything.
And estimation is not an exact science. Here’s what Yoti’s March 2023 white paper says about age estimation accuracy:
Our True Positive Rate (TPR) for 13-17 year olds being correctly estimated as under 25 is 99.93% and there is no discernible bias across gender or skin tone. The TPRs for female and male 13-17 year olds are 99.90% and 99.94% respectively. The TPRs for skin tone 1, 2 and 3 are 99.93%, 99.89% and 99.92% respectively. This gives regulators globally a very high level of confidence that children will not be able to access adult content.
Our TPR for 6-11 year olds being correctly estimated as under 13 is 98.35%. The TPRs for female and male 6-11 year olds are 98.00% and 98.71% respectively. The TPRs for skin tone 1, 2 and 3 are 97.88%, 99.24% and 98.18% respectively so there is no material bias in this age group either.
Yoti’s facial age estimation is performed by a ‘neural network’, trained to be able to estimate human age by analysing a person’s face. Our technology is accurate for 6 to 12 year olds, with a mean absolute error (MAE) of 1.3 years, and of 1.4 years for 13 to 17 year olds. These are the two age ranges regulators focus upon to ensure that under 13s and 18s do not have access to age restricted goods and services.
While this is admirable, is it precise enough to comply with government regulations? Mean absolute errors of over a year don’t mean a hill of beans. By the letter of the law, if you are 17 years and 364 days old and you try to vote, you are breaking the law.
Why did I change my mind?
Over the last couple of months I’ve thought about this a bit more and have experienced a Jim Bakker “I was wrong” moment.
How many 13 year olds do you know that have driver’s licenses? Probably none.
How many 13 year olds do you know that have government-issued REAL IDs? Probably very few.
How many 13 year olds do you know that have passports? Maybe a few more (especially after 9/11), but not that many.
Even at age 18, there is no guarantee that a person will have a government-issued REAL ID.
So how are 18 year olds, or 13 year olds, supposed to prove that they are old enough for services? Carry their birth certificate around?
You’ll note that Yoti didn’t target a use case for 21 year olds. This is partially because Yoti is a UK firm and therefore may not focus on the strict U.S. laws regarding alcohol, tobacco, and casino gambling. But it’s also because it’s much, much more likely that a 21 year old will have a government-issued ID, eliminating the need for age estimation.
Sometimes.
In some parts of the world, no one has government IDs
Over the past several years, I’ve analyzed a variety of identity firms. Earlier this year I took a look at Worldcoin. While Worldcoin’s World ID emphasizes privacy so much that it does not conclusively prove a person’s identity (it only proves a person’s uniqueness), and makes no attempt to provide the age of the person with the World ID, Worldcoin does have something to say about government issued IDs.
Online services often request proof of ID (usually a passport or driver’s license) to comply with Know your Customer (KYC) regulations. In theory, this could be used to deduplicate individuals globally, but it fails in practice for several reasons.
KYC services are simply not inclusive on a global scale; more than 50% of the global population does not have an ID that can be verified digitally.
IDs are issued by states and national governments, with no global system for verification or accountability. Many verification services (i.e. KYC providers) rely on data from credit bureaus that is accumulated over time, hence stale, without the means to verify its authenticity with the issuing authority (i.e. governments), as there are often no APIs available. Fake IDs, as well as real data to create them, are easily available on the black market. Additionally, due to their centralized nature, corruption at the level of the issuing and verification organizations cannot be eliminated.
Same source as above.
Now this (in my opinion) doesn’t make the case for Worldcoin, but it certainly casts some doubt on a universal way to document ages.
So we’d better start measuring the accuracy of age estimation.
If only there were an independent organization that could measure age estimation, in the same way that NIST measures the accuracy of fingerprint, face, and iris identification.
You know where this is going.
How will NIST test age estimation?
Yes, NIST is in the process of incorporating an age estimation test in its battery of Face Recognition Vendor Tests.
Facial age verification has recently been mandated in legislation in a number of jurisdictions. These laws are typically intended to protect minors from various harms by verifying that the individual is above a certain age. Less commonly some applications extend benefits to groups below a certain age. Further use-cases seek only to determine actual age. The mechanism for estimating age is usually not specified in legislation. Face analysis using software is one approach, and is attractive when a photograph is available or can be captured.
In 2014, NIST published a NISTIR 7995 on Performance of Automated Age Estimation. The report showed using a database with 6 million images, the most accurate age estimation algorithm have accurately estimated 67% of the age of a person in the images within five years of their actual age, with a mean absolute error (MAE) of 4.3 years. Since then, more research has dedicated to further improve the accuracy in facial age verification.
Note that this was in 2014. As we have seen above, Yoti asserts a dramatically lower error rate in 2023.
NIST is just ramping up the testing right now, but once it moves forward, it will be possible to compare age estimation accuracy of various algorithms, presumably in multiple scenarios.
Well, for those algorithm providers who choose to participate.
Does your firm need to promote its age estimation solution?
Does your company have an age estimation solution that is superior to all others?
Do you need an experienced identity professional to help you spread the word about your solution?
When you have tens of thousands of people dying, then the only conscionable response is to ban automobiles altogether. Any other action or inaction is completely irresponsible.
After all, you can ask the experts who want us to ban biometrics because it can be spoofed and is racist, so therefore we shouldn’t use biometrics at all.
I disagree with the calls to ban biometrics, and I’ll go through three “biometrics are bad” examples and say why banning biometrics is NOT justified.
Even some identity professionals may not know about the old “gummy fingers” story from 20+ years ago.
And yes, I know that I’ve talked about Gender Shades ad nauseum, but it bears repeating again.
And voice deepfakes are always a good topic to discuss in our AI-obsessed world.
But the iris security was breached by a “dummy eye” just a month later, in the same way that gummy fingers and face masks have defeated other biometric technologies.
Back in 2002, this news WAS really “scary,” since it suggested that you could access a fingerprint reader-protected site with something that wasn’t a finger. Gelatin. A piece of metal. A photograph.
TECH5 participated in the 2023 LivDet Non-contact Fingerprint competition to evaluate its latest NN-based fingerprint liveness detection algorithm and has achieved first and second ranks in the “Systems” category for both single- and four-fingerprint liveness detection algorithms respectively. Both submissions achieved the lowest error rates on bonafide (live) fingerprints. TECH5 achieved 100% accuracy in detecting complex spoof types such as Ecoflex, Playdoh, wood glue, and latex with its groundbreaking Neural Network model that is only 1.5MB in size, setting a new industry benchmark for both accuracy and efficiency.
TECH5 excelled in detecting fake fingers for “non-contact” reading where the fingers don’t even touch a surface such as an optical surface. That’s appreciably harder than detecting fake fingers that touch contact devices.
I should note that LivDet is an independent assessment. As I’ve said before, independent technology assessments provide some guidance on the accuracy and performance of technologies.
So gummy fingers and future threats can be addressed as they arrive.
Let’s stop right there for a moment and address two items before we continue. Trust me; it’s important.
This study evaluated only three algorithms: one from IBM, one from Microsoft, and one from Face++. It did not evaluate the hundreds of other facial recognition algorithms that existed in 2018 when the study was released.
The study focused on gender classification and race classification. Back in those primitive innocent days of 2018, the world assumed that you could look at a person and tell whether the person was male or female, or tell the race of a person. (The phrase “self-identity” had not yet become popular, despite the Rachel Dolezal episode which happened before the Gender Shades study). Most importantly, the study did not address identification of individuals at all.
However, the findings did find something:
While the companies appear to have relatively high accuracy overall, there are notable differences in the error rates between different groups. Let’s explore.
All companies perform better on males than females with an 8.1% – 20.6% difference in error rates.
All companies perform better on lighter subjects as a whole than on darker subjects as a whole with an 11.8% – 19.2% difference in error rates.
When we analyze the results by intersectional subgroups – darker males, darker females, lighter males, lighter females – we see that all companies perform worst on darker females.
What does this mean? It means that if you are using one of these three algorithms solely for the purpose of determining a person’s gender and race, some results are more accurate than others.
And all the stories about people such as Robert Williams being wrongfully arrested based upon faulty facial recognition results have nothing to do with Gender Shades. I’ll address this briefly (for once):
In the United States, facial recognition identification results should only be used by the police as an investigative lead, and no one should be arrested solely on the basis of facial recognition. (The city of Detroit stated that Williams’ arrest resulted from “sloppy” detective work.)
If you are using facial recognition for criminal investigations, your people had better have forensic face training. (Then they would know, as Detroit investigators apparently didn’t know, that the quality of surveillance footage is important.)
If you’re going to ban computerized facial recognition (even when only used as an investigative lead, and even when only used by properly trained individuals), consider the alternative of human witness identification. Or witness misidentification. Roeling Adams, Reggie Cole, Jason Kindle, Adam Riojas, Timothy Atkins, Uriah Courtney, Jason Rivera, Vondell Lewis, Guy Miles, Luis Vargas, and Rafael Madrigal can tell you how inaccurate (and racist) human facial recognition can be. See my LinkedIn article “Don’t ban facial recognition.”
Obviously, facial recognition has been the subject of independent assessments, including continuous bias testing by the National Institute of Standards and Technology as part of its Face Recognition Vendor Test (FRVT), specifically within the 1:1 verification testing. And NIST has measured the identification bias of hundreds of algorithms, not just three.
Richard Nixon never spoke those words in public, although it’s possible that he may have rehearsed William Safire’s speech, composed in case Apollo 11 had not resulted in one giant leap for mankind. As noted in the video, Nixon’s voice and appearance were spoofed using artificial intelligence to create a “deepfake.”
In early 2020, a branch manager of a Japanese company in Hong Kong received a call from a man whose voice he recognized—the director of his parent business. The director had good news: the company was about to make an acquisition, so he needed to authorize some transfers to the tune of $35 million. A lawyer named Martin Zelner had been hired to coordinate the procedures and the branch manager could see in his inbox emails from the director and Zelner, confirming what money needed to move where. The manager, believing everything appeared legitimate, began making the transfers.
What he didn’t know was that he’d been duped as part of an elaborate swindle, one in which fraudsters had used “deep voice” technology to clone the director’s speech…
Now I’ll grant that this is an example of human voice verification, which can be as inaccurate as the previously referenced human witness misidentification. But are computerized systems any better, and can they detect spoofed voices?
IDVoice Verified combines ID R&D’s core voice verification biometric engine, IDVoice, with our passive voice liveness detection, IDLive Voice, to create a high-performance solution for strong authentication, fraud prevention, and anti-spoofing verification.
Anti-spoofing verification technology is a critical component in voice biometric authentication for fraud prevention services. Before determining a match, IDVoice Verified ensures that the voice presented is not a recording.
This is only the beginning of the war against voice spoofing. Other companies will pioneer new advances that will tell the real voices from the fake ones.
As for independent testing:
ID R&D has participated in multiple ASVspoof tests, and performed well in them.