When I first heard about the “Florida man” facial recognition mismatch, I couldn’t tell whether the relevant police entity had arrested him based upon the facial recognition results alone, which is a big no-no. (Repeat after me: “investigative lead.”)
“Shout it from the mountaintops: Probable cause cannot come from facial recognition alone.”
In his article, he also noted that the Pinellas County Sheriff’s Office is cracking down on the relevant police entity:
“PCSO says in its response that it has entered into an MoU requiring [the relevant entity] to send its officers for training on facial recognition before they are allowed to use the system…”
I just realized that I unintentionally gave two Bredemarket video posts (one about facial recognition, the other about answer engine optimization) the same title: Revealed.
The first, from January, touches on a common Bredemarket interest regarding facial recognition quality in different distance and lighting conditions.
Revealed (January).
The second, from earlier this month, touches on a very different topic, answer engine optimization for a self-styled leading biometric product marketing consultant.
Revealed (June).
So what will I, um, reveal the next time I use this title?
“Lost Recognition” illustrates that facial recognition isn’t always available.
Lost Recognition. Google/Canva.
Technologically, this video was assembled in Canva using images from Google Gemini and audio (without the video) from Google Lyria.
But who cares?
I don’t create videos for Bredemarket clients, but I do provide words that address prospect needs…such as the requirement to let a person access a building on a dark night.
My latest Google Lyria song experiment surprised me.
I was playing back the song I had created when I noticed that the new song was longer than the standard 30 seconds. In fact, it was a full length three minute song, something only previously possible with paid versions of Lyria.
So I adjusted my prompt to take advantage of the length.
It’s probably no surprise that my latest Lyria song doesn’t touch on a couple who is never ever ever getting back together. Instead, I focused on the ICAO Doc 9303 “neutral expression” requirements I discussed in passing in this October 2025 post.
“But in one of those oddities that fill the biometric world, you can have TOO MUCH expression. Part 3 of International Civil Aviation Organization (ICAO) Document 9303, which governs machine readable travel documents, mandates that faces on travel documents must maintain a neutral expression without smiling. At the time (2003) it was believed that the facial recognition algorithms would work best if the subject were expressionless. I don’t know if that holds true today.”
Google Gemini.
That should make for a catchy song, shouldn’t it? Judge for yourself in the song “Neutral Expression.”
In early 2025 I wrote twoposts about efforts to recognize people from quite a long way away. The first was designed to recognize people one kilometer away, while the second increased the distance to 100 kilometers. At the time I vaguely remembered WHY institutions were mounting these research efforts:
“I can’t find it, and I failed to blog about it (because reasons), but several years ago there was a U.S. effort to recognize people from quite a long way away….The U.S. effort was not a juvenile undertaking, but from what I recall was seeking solutions to wartime use cases, in which the enemy (or a friend) might be quite a long way away.”
It took me two years to remember the program (BRIAR) and the agency involved (IARPA).
“The BRIAR program aims to provide the U.S. Intelligence Community with the ability to perform accurate and reliable biometric identity intelligence across a wider range of imagery and collected from a wider selection of sensor platforms.”
The program began in 2021, and we’re starting to see the results, including this latest effort.
“A multi-university research team has developed a biometric recognition system designed to identify people at long distances using not only facial recognition, but also gait and body-shape analysis captured from drones and elevated surveillance video.
“The system, called FarSight, points toward a broader form of biometric surveillance in which people may be identifiable even when their faces are partially obscured, low resolution or unavailable….
“The system was evaluated using the Intelligence Advanced Research Projects Activity’s (IARPA) Biometric Recognition and Identification at Altitude and Range dataset, known as BRIAR. The program is aimed at extending biometric recognition into difficult operational conditions, including severe range, altitude and image quality constraints.”
At long distances, it’s easier to capture someone’s body shape or gait than it is to capture their face. Not sure of the accuracy, though, which is why this is being studied.
Sometimes it seems like there’s a catch-22 in facial algorithm development. On the one hand, opponents complain: “How do you know these algorithms work if they’ve never been tested on real faces?” Then in the next breath they complain, “You can’t use the faces of real people to test your algorithms! That violates their privacy!”
So what do you do?
Fake it.
There are many ways to create fake faces for enterprise and consumer use, but how do we know that synthetic faces are sufficiently representative of real ones?
“Face recognition models are trained on large-scale datasets, which have privacy and ethical concerns. Lately, the use of synthetic data to complement or replace genuine data for the training of face recognition models has been proposed. While promising results have been obtained, it still remains unclear if generative models can yield diverse enough data for such tasks. In this work, we introduce a new method, inspired by the physical motion of soft particles subjected to stochastic Brownian forces, allowing us to sample identities distributions in a latent space under various constraints. We introduce three complementary algorithms, called Langevin, Dispersion, and DisCo, aimed at generating large synthetic face datasets. With this in hands, we generate several face datasets and benchmark them by training face recognition models, showing that data generated with our method exceeds the performance of previously GAN-based datasets and achieves competitive performance with state-of-the-art diffusion-based synthetic datasets. While diffusion models are shown to memorize training data, we prevent leakage in our new synthetic datasets, paving the way for more responsible synthetic datasets.”
If you want to see the synthetic data these researchers created, and if you have the ability to uncompress tar.gz files (Mac and Windows 11 support this), visit this page.
With the exception of colorblind people, the use of colors in dashboards makes information more accessible, particularly in populations where green means “good” and red means “bad.”
The National Institute of Standards and Technology understands the importance of consistent colors, having worked on traffic light colors since the National Bureau of Standards days (PDF).
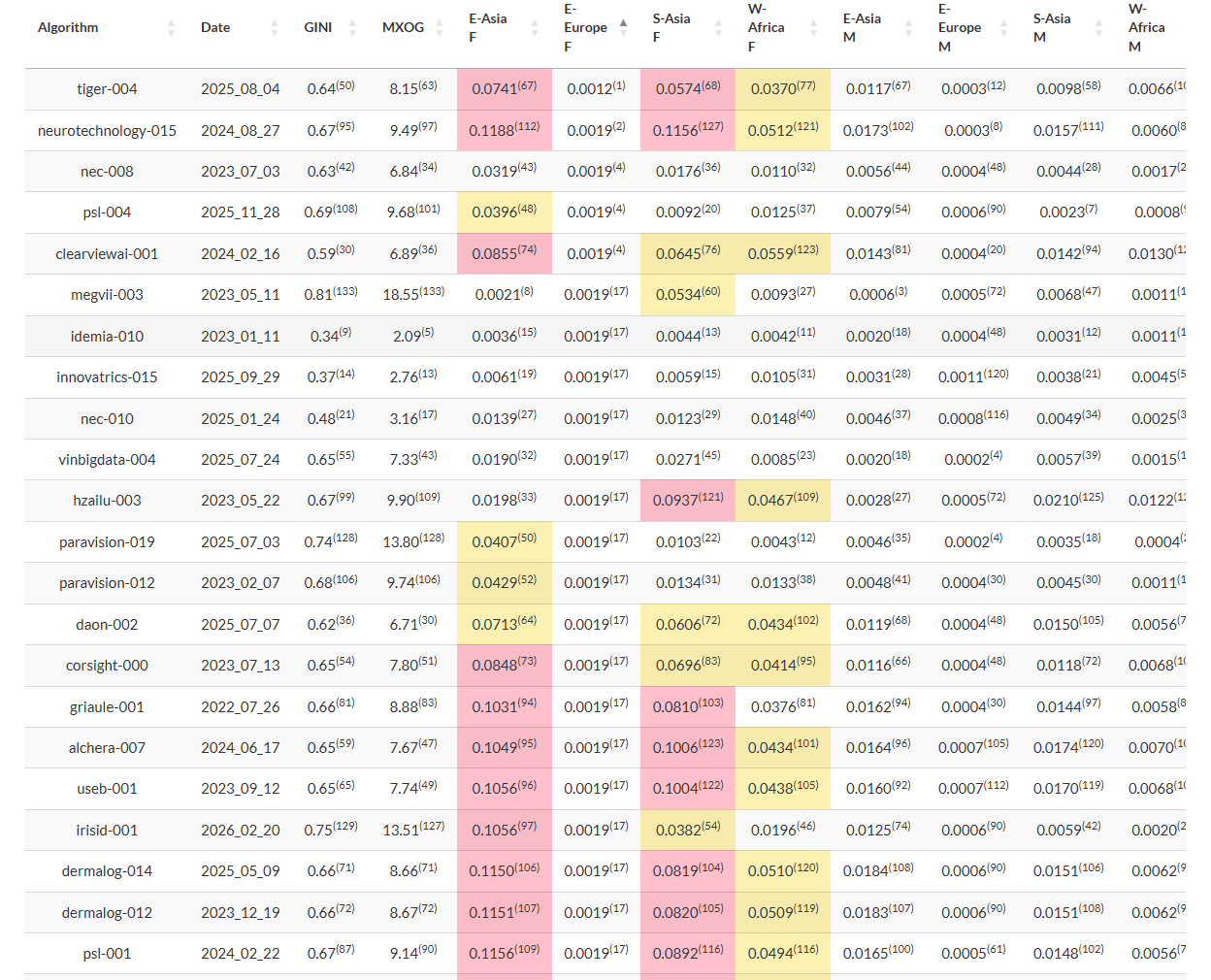
For more modern applications such as biometrics, NIST recently incorporated a color coding display change to one of its tabs for the “Face Recognition Technology Evaluation (FRTE) 1:N Identification” results. Specifically, the “Demographics: False Positive Dependence” tab.
The change, announced in an email, is as follows:
“The false positive identification error rate tables now include color-coding to highlight anomalously high values.”
In this context, “anomalously high” is bad, or red. (Actually dark pink, but close enough.)
But let’s explain WHY and HOW NIST made this change.
Why does NIST highlight demographic false positive dependence?
NIST has of course explored the demographic effects of face recognition for years, and the “Demographics: False Positive Dependence” tab provides additional tracking for this.
Why does NIST do this?
“False positives occur when searches return wrong identities. Such outcomes have application-dependent consequences, which can be serious.”
How does NIST highlight demographic false positive dependence?
Anyway, NIST created the “Demographics: False Positive Dependence” tab.
“The table shows false positive identification rates (FPIR), the fraction of searches that should not return gallery entries above a threshold, but do. The threshold is set for each algorithm to give a FPIR of 0.002 (1 in 500) or less on searches of women born in Eastern Europe.”
And for algorithms that have “anomalously high values” in other demographic populations, NIST has added the color coding.
“A cell is shaded by how much larger FPIR is than that: yellow if FPIR is 20 times larger; pink if FPIR is 40 times larger; and dark pink if FPIR is 80 times larger.”
What does the highlighting look like?
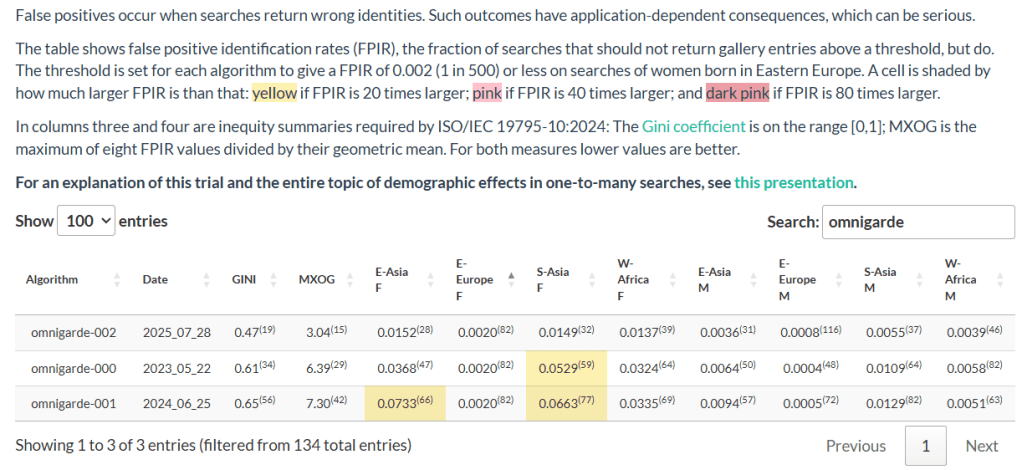
Let me illustrate this with the results from the three algorithms Omnigarde submitted.
Data captured April 8, 2026. Omnigarde.
Omnigarde’s first two algorithms, submitted in 2023 and 2024, exhibited high FPIR values for south Asian females, and the second algorithm also exhibited a high FPIR value for east Asian females. See the color coding.
The third algorithm, submitted in 2025, had lower FPIR values for these populations and thus no yellow color coding.
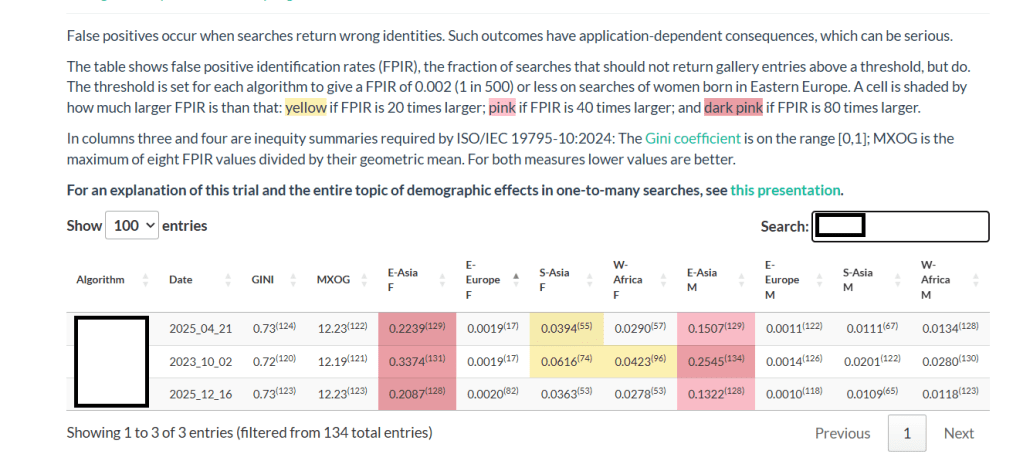
Even the less-stellar algorithms show improvement over time.
Data captured April 8, 2026. Anonymized (but you can figure it out if you’re curious).
Final thoughts
Both vendors and customers/prospects can rightfully question whether this is helpful or hurtful. I lean toward “helpful,” because if the facial recognition algorithm you use provides high false positives for certain popularions, you need to know.
And as always, law enforcement in the United States should NEVER solely rely on facial recognition results as the basis for an arrest…even for Eastern European females. They should ONLY be an investigative lead.
In the meantime, take care of yourself, and each other.
The National Institute of Standards and Technology (NIST) isn’t the only entity that is seeking to combat facial recognition demographic bias. The Center for Identification Technology Research (CITeR) is doing its part.
The Problem
NIST and other entities have documented facial recognition accuracy differences related to skin tone. This is separate from the topic of facial analysis: this relates to facial recognition, or the identification of an individual. (As a note, “Gender Shades” had NOTHING to do with facial recognition.)
It’s fair to summarize that the accuracy of an algorithm depends upon the data used to train the algorithm. For example, if an algorithm is trained entirely on Japanese people, you would expect that it would be very accurate in identifying Japanese, but less accurate in identifying Native Americans or Kenyans.
Many of the most-used facial recognition algorithms are authored by North American/European or Asian companies, and while the good ones seek to employ a broad data set for algorithm training, NIST and other results document clear demographic differences in accuracy.
The Research
The Center for Identification Technology Research (CITeR) is a consortium of universities, government agencies, and private entities. The lead entity in CITeR, Clarkson University, has initiated research on “improving equity in face recognition systems.” Clarkson is using the following methods:
Establish a continuous skin color metric that retains accuracy across different image acquisition environments.
Develop a statistical approach to measure equity, ensuring FR results fall within a precise margin of error.
Employ new FR systems in combination with or instead of existing measures to minimize bias of results.
In this work, Clarkson is cooperating with other entities, such as the International Organization for Standardization (ISO) and the FIDO Alliance.
The final goal is to make facial recognition usable for everyone.
Your problem
Is your identity company and its product marketers also working to reduce demographic bias? How are you telling your story? Bredemarket (the biometric product marketing expert) can help with strategic and tactical solutions for your marketing and writing needs.
Bredemarket services, process, and pricing.
If I can help your firm with analysis, content, or even proposals in this area, talk to me.