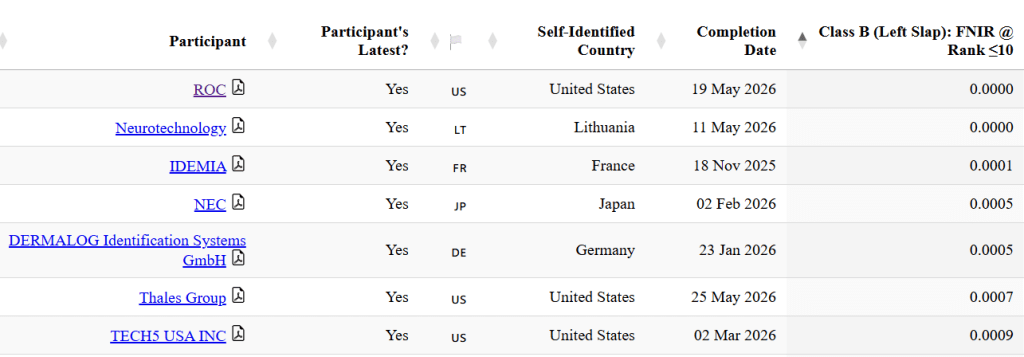
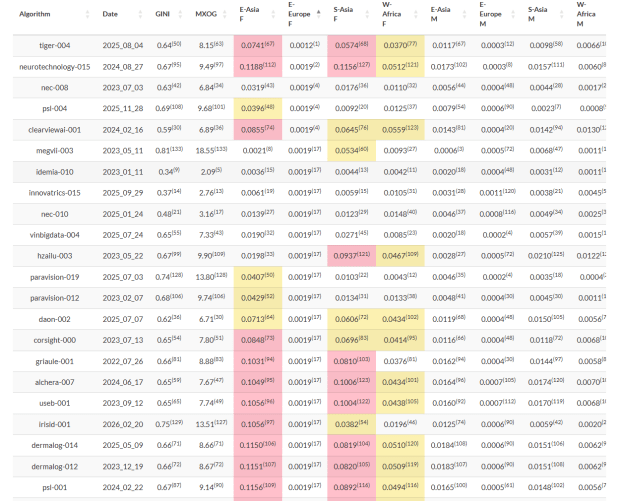
Unlike most other posts that appear under my name—Bredebot posts are another matter—this post breaks my 2023 rule because most of it was written by Google Gemini, not me.
But I figured that if I wrote a book specifically about SIX factors of authentication…

…it would be nice to know if other experts held similar thoughts.
My prompt to Gemini
Bredemarket has promoted “somewhat you why” as a sixth factor of identity verification / authentication. Has anyone else shared similar observations?
Gemini’s response
Here is the short answer: Yes, industry experts and security frameworks strongly agree with the core observation, though they call it “Authentication Intent,” “Intent Verification,” or “Context-Aware/Risk-Based Authentication” rather than using Bredemarket’s play-on-words.
John Bredehoft (Bredemarket) coined “somewhat you why” to fit the traditional naming convention (something you know, have, are, do, somewhere you are). His argument is that checking why an action or request is taking place—evaluating intent, transaction risk, or reasonableness—functions as a crucial safeguard, especially in an era of deepfakes and automated AI agents.
While the tongue-in-cheek name is unique to Bredemarket, the concept itself is widely discussed and implemented across the cybersecurity industry under three main paradigms:
1. “Authentication Intent” (NIST Standards)
The National Institute of Standards and Technology (NIST) explicitly addresses intent in NIST SP 800-63B.
- The Problem: A user might have a valid session token, biometrics, or physical key plugged in, but malware or a session hijack could trigger actions without the user’s conscious decision.
- The Solution: Systems require an explicit act of intent—like tapping a physical FIDO key, typing a PIN, or responding to a contextual prompt—proving that the user intended to execute that specific action at that moment.
2. Intent Verification for AI & Delegated Actions
With the rise of autonomous AI agents and automated workflows, identity security groups (like the Non-Human Identity/NHI movement) frequently discuss Intent Verification.
- Conventional authentication proves who logged in, but not whether the user meant to perform this specific action.
- Intent Verification bridges authentication and authorization by evaluating whether a transaction (e.g., a $35M wire transfer or an API call) aligns with the user’s actual current decision and business policy.
3. Context-Aware and Adaptive Authentication
Identity providers (like Palo Alto Networks, Okta, and Silverfort) build their Adaptive Multi-Factor Authentication (AMFA) around the “why” and “context”:
- Context Signals: What resource is being accessed? Is this normal business behavior? Does this request make sense given the time, value, and sensitivity?
- Dynamic Step-Up: If the “why” seems low-risk (e.g., checking internal docs during work hours), access is smooth. If the “why” is high-risk or suspicious (e.g., a wire transfer requested via video call), the system demands step-up verification.
How the Views Compare
While most identity security professionals treat “intent and context” as a governance or risk engine layer wrapping traditional factors rather than a 6th factor itself, everyone agrees with Bredemarket’s baseline premise: verifying who someone is without evaluating what and why they are trying to do it is no longer enough to stop modern fraud.