The post touched on many items, one of which was the relative ease in using popular voice cloning programs to create fraudulent voices. Consumer Reports determined that four popular voice cloning programs “did not have the technical mechanisms necessary to prevent cloning someone’s voice without their knowledge or to limit the AI cloning to only the user’s voice.”
Reducing voice clone fraud?
Joel R. McConvey of Biometric Update wrote a piece (“Hi mom, it’s me,” an example of a popular fraudulent voice clone) that included an update on one of the four vendors cited by Consumer Reports.
In its responses, ElevenLabs – which was implicated in the deepfake Joe Biden robocall scam of November 2023 – says it is “implementing Coalition for Content Provenance and Authenticity (C2PA) standards by embedding cryptographically-signed metadata into the audio generated on our platform,” and lists customer screening, voice CAPTCHA and its No-Go Voice technology, which blocks the voices of hundreds of public figures, as among safeguards it already deploys.
Coalition for Content Provenance and Authenticity
So what are these C2PA standards? As a curious sort (I am ex-IDEMIA, after all), I investigated.
The Coalition for Content Provenance and Authenticity (C2PA) addresses the prevalence of misleading information online through the development of technical standards for certifying the source and history (or provenance) of media content. C2PA is a Joint Development Foundation project, formed through an alliance between Adobe, Arm, Intel, Microsoft and Truepic.
There are many other organizations whose logos appear on the website, including Amazon, Google, Meta, and Open AI.
Provenance
I won’t plunge into the entire specifications, but this excerpt from the “Explainer” highlights an important word, “provenance” (the P in C2PA).
Provenance generally refers to the facts about the history of a piece of digital content assets (image, video, audio recording, document). C2PA enables the authors of provenance data to securely bind statements of provenance data to instances of content using their unique credentials. These provenance statements are called assertions by the C2PA. They may include assertions about who created the content and how, when, and where it was created. They may also include assertions about when and how it was edited throughout its life. The content author, and publisher (if authoring provenance data) always has control over whether to include provenance data as well as what assertions are included, such as whether to include identifying information (in order to allow for anonymous or pseudonymous assets). Included assertions can be removed in later edits without invalidating or removing all of the included provenance data in a process called redaction.
Providence
I would really have to get into the nitty gritty of the specifications to see exactly how ElevenLabs, or anyone else, can accurately assert that a voice recording alleged to have been made by Richard Nixon actually was made by Richard Nixon. Hint: this one wasn’t.
Incidentally, while this was obviously never spoken, and I don’t believe that Nixon ever saw it, the speech was drafted as a contingency by William Safire. And I think everyone can admit that Safire could soar as a speechwriter for Nixon, whose sense of history caused him to cast himself as an American Churchill (with 1961 to 1969 as Nixon’s “wilderness years”). Safire also wrote for Agnew, who was not known as a great strategic thinker.
And the Apollo 11 speech above is not the only contingency speech ever written. Someone should create a deepfake of this speech that was NEVER delivered by then-General Dwight D. Eisenhower after D-Day:
Our landings in the Cherbourg-Havre have failed to gain a satisfactory foothold and I have withdrawn the troops. My decision to attack at this time and place was based upon the best information available. The troops, the air and the Navy did all that bravery and devotion to duty could do. If any blame or fault attaches to the attempt it is mine alone.
In 2023, 27% of people who reported a fraud said they lost money, while in 2024, that figure jumped to 38%.
In a way this is odd, since you would think that we would better detect fraud attempts now. But I guess we don’t. (I’ll say why in a minute.)
Imposter scams
The second fraud category, after investment scams, was imposter scams.
The second highest reported loss amount came from imposter scams, with $2.95 billion reported lost. In 2024, consumers reported losing more money to scams where they paid with bank transfers or cryptocurrency than all other payment methods combined.
Deepfakes
I’ve spent…a long time in the business of determining who people are, and who people aren’t. While the FTC summary didn’t detail the methods of imposter scams, at least some of these may have used deepfakes to perpetuate the scam.
…technology that simulates human activity, such as software that creates deepfake videos and voice clones….They can use deepfakes and voice clones to facilitate imposter scams, extortion, and financial fraud. And that’s very much a non-exhaustive list.
The results found that four of the six products — from ElevenLabs, Speechify, PlayHT, and Lovo — did not have the technical mechanisms necessary to prevent cloning someone’s voice without their knowledge or to limit the AI cloning to only the user’s voice.
Instead, the protection was limited to a box users had to check off, confirming they had the legal right to clone the voice.
And of course the identity/biometric vendor commuity is addressing deepfakes also. Research from iProov indicates one reason why 38% of the FTC reporters lost money to fraud:
[M]ost people can’t identify deepfakes – those incredibly realistic AI-generated videos and images often designed to impersonate people. The study tested 2,000 UK and US consumers, exposing them to a series of real and deepfake content. The results are alarming: only 0.1% of participants could accurately distinguish real from fake content across all stimuli which included images and video… in a study where participants were primed to look for deepfakes. In real-world scenarios, where people are less aware, the vulnerability to deepfakes is likely even higher.
So what’s the solution? Throw more technology at the problem? Multi factor authentication (requiring the fraudster to deepfake multiple items)? Injection attack detection? Something else?
When marketing your facial recognition product (or any product), you need to pay attention to your positioning and messaging. This includes developing the answers to why, how, and what questions. But your positioning and your resulting messaging are deeply influenced by the characteristics of your product.
If facial recognition is your only modality
There are hundreds of facial recognition products on the market that are used for identity verification, authentication, crime solving (but ONLY as an investigative lead), and other purposes.
Some of these solutions ONLY use face as a biometric modality. Others use additional biometric modalities.
Similarly, a face-only company will argue that facial recognition is a very fast, very secure, and completely frictionless method of verification and authentication. When opponents bring up the demonstrated spoofs against faces, you will argue that your iBeta-conformant presentation attack detection methodology guards against such spoofing attempts.
Of course, if you initially only offer a face solution and then offer a second biometric, you’ll have to rewrite all your material. “You know how we said that face is great? Well, face and gait are even greater!”
It seems that many of the people that are waiting the long-delayed death of the password think that biometrics is the magic solution that will completely replace passwords.
For this reason, your company might have decided to use biometrics as your sole factor of identity verification and authentication.
Or perhaps your company took a different approach, and believes that multiple factors—perhaps all five factors—are required to truly verify and/or authenticate an individual. Use some combination of biometrics, secure documents such as driver’s licenses, geolocation, “something you do” such as a particular swiping pattern, and even (horrors!) knowledge-based authentication such as passwords or PINs.
This naturally shapes your positioning and messaging.
The single factor companies will argue that their approach is very fast, very secure, and completely frictionless. (Sound familiar?) No need to drag out your passport or your key fob, or to turn off your VPN to accurately indicate your location. Biometrics does it all!
The multiple factor companies will argue that ANY single factor can be spoofed, but that it is much, much harder to spoof multiple factors at once. (Sound familiar?)
So position yourself however you need to position yourself. Again, be prepared to change if your single factor solution adopts a second factor.
A final thought
Every company has its own way of approaching a problem, and your company is no different. As you prepare to market your products, survey your product, your customers, and your prospects and choose the correct positioning (and messaging) for your own circumstances.
And if you need help with biometric positioning and messaging, feel free to contact the biometric product marketing expert, John E. Bredehoft. (Full-time employment opportunities via LinkedIn, consulting opportunities via Bredemarket.)
In the meantime, take care of yourself, and each other.
Checking the purported identity against private databases, such as credit records.
Checking the person’s driver’s license or other government document to ensure it’s real and not a fake.
Checking the purported identity against government databases, such as driver’s license databases. (What if the person presents a real driver’s license, but that license was subsequently revoked?)
Perform a “who you are” biometric test against the purported identity.
If you conduct all four tests, then you have used multiple factors of authentication to confirm that the person is who they say they are. If the identity is synthetic, chances are the purported person will fail at least one of these tests.
Do you fight synthetic identity fraud?
If you fight synthetic identity fraud, you should let people know about your solution.
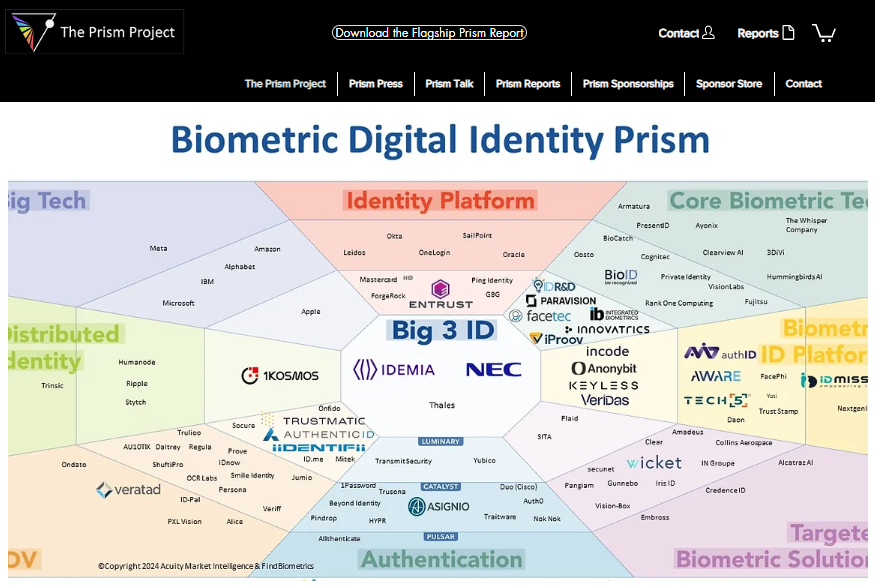
The Prism Project’s home page at https://www.the-prism-project.com/, illustrating the Biometric Digital Identity Prism as of March 2024. From Acuity Market Intelligence and FindBiometrics.
With over 100 firms in the biometric industry, their offerings are going to naturally differ—even if all the firms are TRYING to copy each other and offer “me too” solutions.
I’ve worked for over a dozen biometric firms as an employee or independent contractor, and I’ve analyzed over 80 biometric firms in competitive intelligence exercises, so I’m well aware of the vast implementation differences between the biometric offerings.
Some of the implementation differences provoke vehement disagreements between biometric firms regarding which choice is correct. Yes, we FIGHT.
Let’s look at three (out of many) of these implementation differences and see how they affect YOUR company’s content marketing efforts—whether you’re engaging in identity blog post writing, or some other content marketing activity.
The three biometric implementation choices
Firms that develop biometric solutions make (or should make) the following choices when implementing their solutions.
Presentation attack detection. Assuming the solution incorporates presentation attack detection (liveness detection), or a way of detecting whether the presented biometric is real or a spoof, the firm must decide whether to use active or passive liveness detection.
Age assurance. When choosing age assurance solutions that determine whether a person is old enough to access a product or service, the firm must decide whether or not age estimation is acceptable.
Biometric modality. Finally, the firm must choose which biometric modalities to support. While there are a number of modality wars involving all the biometric modalities, this post is going to limit itself to the question of whether or not voice biometrics are acceptable.
I will address each of these questions in turn, highlighting the pros and cons of each implementation choice. After that, we’ll see how this affects your firm’s content marketing.
(I)nstead of capturing a true biometric from a person, the biometric sensor is fooled into capturing a fake biometric: an artificial finger, a face with a mask on it, or a face on a video screen (rather than a face of a live person).
This tomfoolery is called a “presentation attack” (becuase you’re attacking security with a fake presentation).
And an organization called iBeta is one of the testing facilities authorized to test in accordance with the standard and to determine whether a biometric reader can detect the “liveness” of a biometric sample.
(Friends, I’m not going to get into passive liveness and active liveness. That’s best saved for another day.)
Now I could cite a firm using active liveness detection to say why it’s great, or I could cite a firm using passive liveness detection to say why it’s great. But perhaps the most balanced assessment comes from facia, which offers both types of liveness detection. How does facia define the two types of liveness detection?
Active liveness detection, as the name suggests, requires some sort of activity from the user. If a system is unable to detect liveness, it will ask the user to perform some specific actions such as nodding, blinking or any other facial movement. This allows the system to detect natural movements and separate it from a system trying to mimic a human being….
Passive liveness detection operates discreetly in the background, requiring no explicit action from the user. The system’s artificial intelligence continuously analyses facial movements, depth, texture, and other biometric indicators to detect an individual’s liveness.
Pros and cons
Briefly, the pros and cons of the two methods are as follows:
While active liveness detection offers robust protection, requires clear consent, and acts as a deterrent, it is hard to use, complex, and slow.
Passive liveness detection offers an enhanced user experience via ease of use and speed and is easier to integrate with other solutions, but it incorporates privacy concerns (passive liveness detection can be implemented without the user’s knowledge) and may not be used in high-risk situations.
So in truth the choice is up to each firm. I’ve worked with firms that used both liveness detection methods, and while I’ve spent most of my time with passive implementations, the active ones can work also.
A perfect wishy-washy statement that will get BOTH sides angry at me. (Except perhaps for companies like facia that use both.)
If you need to know a person’s age, you can ask them. Because people never lie.
Well, maybe they do. There are two better age assurance methods:
Age verification, where you obtain a person’s government-issued identity document with a confirmed birthdate, confirm that the identity document truly belongs to the person, and then simply check the date of birth on the identity document and determine whether the person is old enough to access the product or service.
Age estimation, where you don’t use a government-issued identity document and instead examine the face and estimate the person’s age.
I changed my mind on age estimation
I’ve gone back and forth on this. As I previously mentioned, my employment history includes time with a firm produces driver’s licenses for the majority of U.S. states. And back when that firm was providing my paycheck, I was financially incentivized to champion age verification based upon the driver’s licenses that my company (or occasionally some inferior company) produced.
But as age assurance applications moved into other areas such as social media use, a problem occurred since 13 year olds usually don’t have government IDs. A few of them may have passports or other government IDs, but none of them have driver’s licenses.
But does age estimation work? I’m not sure if ANYONE has posted a non-biased view, so I’ll try to do so myself.
The pros of age estimation include its applicability to all ages including young people, its protection of privacy since it requires no information about the individual identity, and its ease of use since you don’t have to dig for your physical driver’s license or your mobile driver’s license—your face is already there.
The huge con of age estimation is that it is by definition an estimate. If I show a bartender my driver’s license before buying a beer, they will know whether I am 20 years and 364 days old and ineligible to purchase alcohol, or whether I am 21 years and 0 days old and eligible. Estimates aren’t that precise.
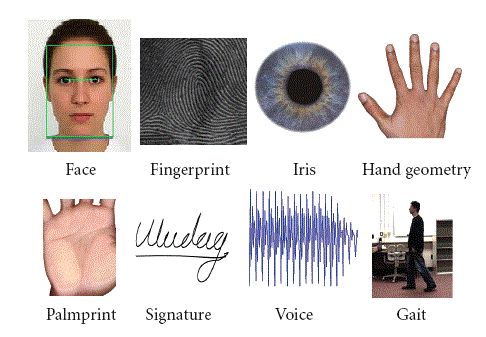
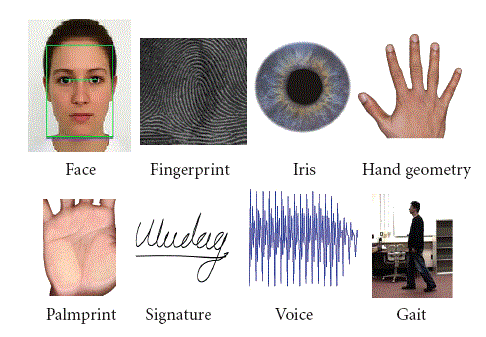
Fingerprints, palm prints, faces, irises, and everything up to gait. (And behavioral biometrics.) There are a lot of biometric modalities out there, and one that has been around for years is the voice biometric.
I’ve discussed this topic before, and the partial title of the post (“We’ll Survive Voice Spoofing”) gives away how I feel about the matter, but I’ll present both sides of the issue.
No one can deny that voice spoofing exists and is effective, but many of the examples cited by the popular press are cases in which a HUMAN (rather than an ALGORITHM) was fooled by a deepfake voice. But voice recognition software can also be fooled.
Take a study from the University of Waterloo, summarized here, that proclaims: “Computer scientists at the University of Waterloo have discovered a method of attack that can successfully bypass voice authentication security systems with up to a 99% success rate after only six tries.”
If you re-read that sentence, you will notice that it includes the words “up to.” Those words are significant if you actually read the article.
In a recent test against Amazon Connect’s voice authentication system, they achieved a 10 per cent success rate in one four-second attack, with this rate rising to over 40 per cent in less than thirty seconds. With some of the less sophisticated voice authentication systems they targeted, they achieved a 99 per cent success rate after six attempts.
Other voice spoofing studies
Similar to Gender Shades, the University of Waterloo study does not appear to have tested hundreds of voice recognition algorithms. But there are other studies.
The 2021 NIST Speaker Recognition Evaluation (PDF here) tested results from 15 teams, but this test was not specific to spoofing.
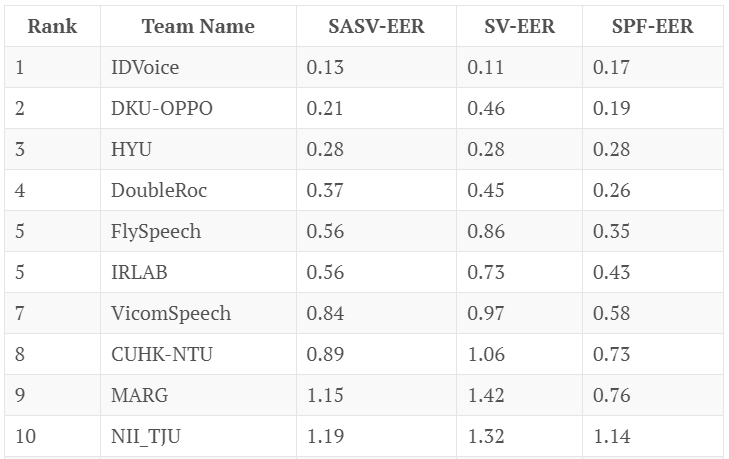
A test that was specific to spoofing was the ASVspoof 2021 test with 54 team participants, but the ASVspoof 2021 results are only accessible in abstract form, with no detailed results.
Another test, this one with results, is the SASV2022 challenge, with 23 valid submissions. Here are the top 10 performers and their error rates.
You’ll note that the top performers don’t have error rates anywhere near the University of Waterloo’s 99 percent.
So some firms will argue that voice recognition can be spoofed and thus cannot be trusted, while other firms will argue that the best voice recognition algorithms are rarely fooled.
What does this mean for your company?
Obviously, different firms are going to respond to the three questions above in different ways.
For example, a firm that offers face biometrics but not voice biometrics will convey how voice is not a secure modality due to the ease of spoofing. “Do you want to lose tens of millions of dollars?”
A firm that offers voice biometrics but not face biometrics will emphasize its spoof detection capabilities (and cast shade on face spoofing). “We tested our algorithm against that voice fake that was in the news, and we detected the voice as a deepfake!”
There is no universal truth here, and the message your firm conveys depends upon your firm’s unique characteristics.
And those characteristics can change.
Once when I was working for a client, this firm had made a particular choice with one of these three questions. Therefore, when I was writing for the client, I wrote in a way that argued the client’s position.
After I stopped working for this particular client, the client’s position changed and the firm adopted the opposite view of the question.
Therefore I had to message the client and say, “Hey, remember that piece I wrote for you that said this? Well, you’d better edit it, now that you’ve changed your mind on the question…”
Bear this in mind as you create your blog, white paper, case study, or other identity/biometric content, or have someone like the biometric content marketing expert Bredemarket work with you to create your content. There are people who sincerely hold the opposite belief of your firm…but your firm needs to argue that those people are, um, misinformed.
This post concentrates on IDENTIFICATION perfection, or the ability to enjoy zero errors when identifying individuals.
The risk of claiming identification perfection (or any perfection) is that a SINGLE counter-example disproves the claim.
If you assert that your biometric solution offers 100% accuracy, a SINGLE false positive or false negative shatters the assertion.
If you claim that your presentation attack detection solution exposes deepfakes (face, voice, or other), then a SINGLE deepfake that gets past your solution disproves your claim.
And as for the pre-2009 claim that latent fingerprint examiners never make a mistake in an identification…well, ask Brandon Mayfield about that one.
In fact, I go so far as to avoid using the phrase “no two fingerprints are alike.” Many years ago (before 2009) in an International Association for Identification meeting, I heard someone justify the claim by saying, “We haven’t found a counter-example yet.” That doesn’t mean that we’ll NEVER find one.
At first glance, it appears that Motorola would be the last place to make a boneheaded mistake like that. After all, Motorola is known for its focus on quality.
But in actuality, Motorola was the perfect place to make such a mistake, since it was one of the champions of the “Six Sigma” philosophy (which targets a maximum of 3.4 defects per million opportunities). Motorola realized that manufacturing perfection is impossible, so manufacturers (and the people in Motorola’s weird Biometric Business Unit) should instead concentrate on reducing the error rate as much as possible.
So one misspelling could be tolerated, but I shudder to think what would have happened if I had misspelled “quality” a second time.
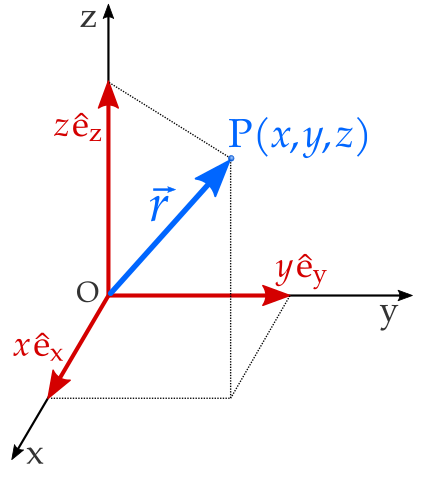
As identity/biometric professionals well know, there are five authentication factors that you can use to gain access to a person’s account. (You can also use these factors for identity verification to establish the person’s account in the first place.)
Something You Are. I’ve spent…a long time with this factor, since this is the factor that includes biometrics modalities (finger, face, iris, DNA, voice, vein, etc.). It also includes behavioral biometrics, provided that they are truly behavioral and relatively static.
As I mentioned in August, there are a number of biometric modalities, including face, fingerprint, iris, hand geometry, palm print, signature, voice, gait, and many more.
If your firm offers an identity solution that partially depends upon “something you are,” then you need to create content (blog, case study, social media, white paper, etc.) that converts prospects for your identity/biometric product/service and drives content results.
But are computerized systems any better, and can they detect spoofed voices?
Well, in the same way that fingerprint readers worked to overcome gummy bears, voice readers are working to overcome deepfake voices.
This is only the beginning of the war against voice spoofing. Other companies will pioneer new advances that will tell the real voices from the fake ones.
As for independent testing:
ID R&D has participated in multiple ASVspoof tests, and performed well in them.