I swear I’ve written about “MasterPrints” before, but I can’t find any such article. Maybe I just discussed it internally at IDEMIA when I worked there in 2018.
“Researchers at NYU and U Michigan have published a paper explaining how they used a pair of machine-learning systems to develop a “universal fingerprint” that can fool the lowest-security fingerprint sensors 76% of the time (it is less effective against higher-security sensors).
“The researchers used “generative adversarial networks” (GAN) to develop their attack: this technique uses a pair of machine learning systems, a “generator” which tries to fool a “discriminator,” to produce a kind of dialectical back-and-forth in that creates fakes that are harder and harder to detect.”
While this happened over seven years ago and is probably harder to implement with today’s technology, I was reminded of this when I ran across this Biometric Update article.
“A new research paper explores a signal-level approach to voice morphing attacks that exposes vulnerabilities in biometric voice recognition systems.
“The abstract describes Time-domain Voice Identity Morphing (TD-VIM) as “a novel approach for voice-based biometric morphing” which “enables the blending of voice characteristics from two distinct identities at the signal level.” TD-VIM allows for seamless voice morphing directly in the time domain, allowing “identity blending without any embeddings from the backbone, or reference text.””
So it, um, sounds like we not only have MasterPrints, but also MasterVoices.
“I think too much knowledge is actually bad in tech: you’re biased.”
Why does this quote affect me so deeply? Because with my 30-plus years of identity/biometric experience, I obviously have too much knowledge of the industry, which is obviously bad. After all, all a biometric company needs is a salesperson, an engineer, an African data labeler, and someone to run the generative AI for everything else. The company doesn’t need someone who knows that Printrak isn’t spelled with a C.
Google Gemini.
In this post I will share three of the “biases” I have developed in my 30-plus years in identity and biometrics, and how to correct these biases by stripping away that 20th century experience and applying novel thinking.
And if that last paragraph made you throw up in your mouth…read to the end of the post.
But first, let’s briefly explore these three biases that I shamefully hold due to my status as a biometric product marketing expert:
Independent algorithmic confirmation is valuable.
Process is valuable.
Artificial intelligence is merely a tool.
Biometric product marketing expert.
Bias 1: Independent Algorithmic Confirmation is Valuable
But how do prospects know that these algorithms work? How accurate are they? How fast are they? How secure are they?
My bias
My brain, embedded with over 30 years of bias, gravitates to the idea that vendors should submit their algorithms for independent testing and confirmation.
From a NIST facial recognition demographic bias text.
This could be an accuracy test such as the ones NIST and DHS administer, or confirmation of presentation attack detection capabilities (as BixeLab, iBeta, and other organizations perform), or confirmation of injection attack detection capabilities.
Novel thinking
But you’re smarter than that and refuse to support the testing-industrial complex. They have their explicit or implicit agendas and want to force the biometric vendors to do well on the tests. For example, the U.S. Federal Bureau of Investigation’s “Appendix F” fingerprint capture quality standard specifically EXCLUDES contactless solutions, forcing everyone down the same contact path.
But you and your novel thinking reject these unnecessary impediments. You’re not going to constrain yourself by the assertions of others. You are going to assert your own benefits. Develop and administer your own tests. Share with your prospects how wonderful you are without going through an intermediary. That will prove your superiority…right?
Bias 2: Process is Valuable
A biometric company has to perform a variety of tasks. Raise funding. Hire people. Develop, market, propose, sell, and implement products. Throw parties.
How will the company do all these things?
My bias
My brain, encumbered by my experience (including a decade at Motorola), persists in a belief that process is the answer. The process can be as simple as scribblings on a cocktail napkin, but you need some process if you want to cash out in a glorious exit—I mean, deliver superior products to your customers.
Perhaps you need a development processs that defines, among other things, how long a sprint should be. A capture and proposal process (Shipley or simpler) that defines, among other things, who has the authority to approve a $10 million proposal A go-to-market process that defines the deliverables for different tiers, and who is responsible, accountable, consulted, and informed. Or maybe just an onboarding process when starting a new project, dictating the questions you need to ask at the beginning.
Bredemarket’s seven questions. I ask, then I act.
Novel thinking
Sure all that process is fine…if you don’t want to do anything. Do you really want to force your people to wait two weeks for the latest product iteration? Impose a multinational bureauracy on your sales process? Go through an onerous checklist before marketing a product?
Google Gemini.
Just code it.
Just sell it.
Just write it.
Bias 3: Artificial Intelligence is Merely a Tool
The problem with experienced people is that they think that there is nothing new under the sun.
You talk about cloud computing, and they yawn, “Sounds like time sharing.” You talk about quantum computing, and they yawn, “Sounds like the Pentium.” You talk about blockchain, and they yawn, “Sounds like a notary public.”
My bias
As I sip my Pepperidge Farm, I can barely conceal my revulsion at those who think “we use AI” is a world-dominating marketing message. Artificial intelligence is not a way of life. It is a tool. A tool that in and of itself does not merit much of a mention.
Google Gemini.
How many automobile manufacturers proclaim “we use tires” as part of their marketing messaging? Tires are essential to an automobile’s performance, but since everyone has them, they’re not a differentiator and not worthy of mention.
In the same way, everyone has AI…so why talk about its mere presence? Talk about the benefits your implementation provides and how these benefits differentiate you from your competitors.
Novel thinking
Yep, the grandpas that declare “AI is only a tool” are missing the significance entirely. AI is not like a Pentium chip. It is a transformational technology that is already changing the way we create, sell, and market.
Therefore it is critically important to highlight your product’s AI use. AI isn’t a “so what” feature, but an indication of revolutionary transformative technology. You suppress mention of AI at your own peril.
How do I overcome my biases of experience?
OK, so I’ve identified the outmoded thinking that results from too much experience. But how do I overcome it?
I don’t.
Because if you haven’t already detected it, I believe that experience IS valuable, and that all three items above are essential and shouldn’t be jettisoned for the new, novel, and kewl.
Are you a identity/biometric marketing leader who needs to tell your prospects that your algorithms are validated by reputable independent bodies?
Or that you have a process (simple or not) that governs how your customers receive your products?
Or that your AI actually does unique things that your competitors don’t, providing true benefits to your customers?
Bredemarket can help with strategy, analysis, content, and/or proposals for your identity/biometric firm. Talk to me (for free).
By the way, here’s MY process (and my services and pricing).
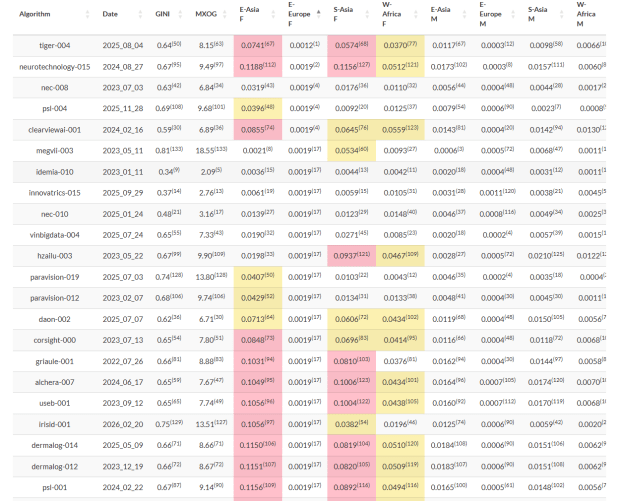
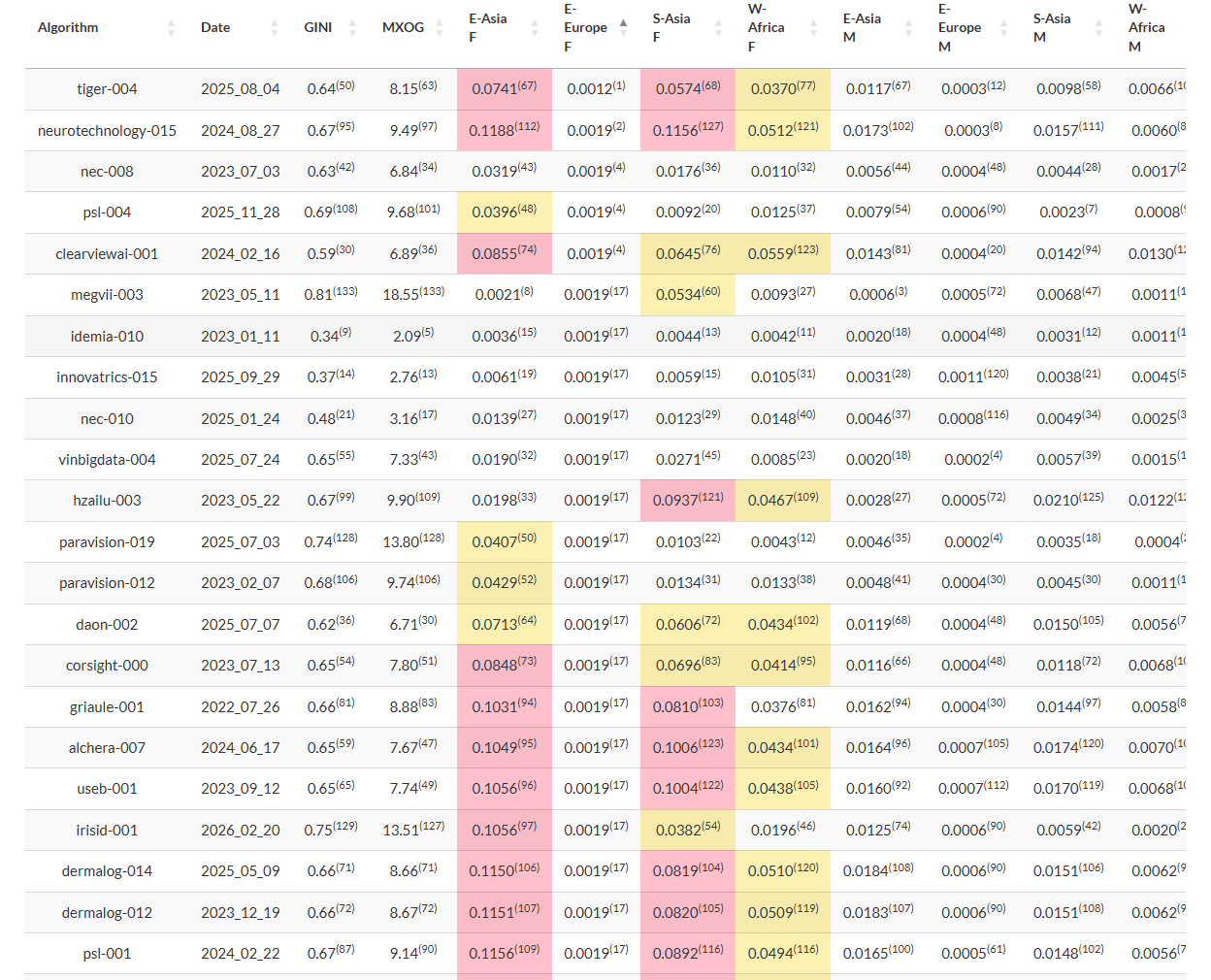
With the exception of colorblind people, the use of colors in dashboards makes information more accessible, particularly in populations where green means “good” and red means “bad.”
The National Institute of Standards and Technology understands the importance of consistent colors, having worked on traffic light colors since the National Bureau of Standards days (PDF).
For more modern applications such as biometrics, NIST recently incorporated a color coding display change to one of its tabs for the “Face Recognition Technology Evaluation (FRTE) 1:N Identification” results. Specifically, the “Demographics: False Positive Dependence” tab.
The change, announced in an email, is as follows:
“The false positive identification error rate tables now include color-coding to highlight anomalously high values.”
In this context, “anomalously high” is bad, or red. (Actually dark pink, but close enough.)
But let’s explain WHY and HOW NIST made this change.
Why does NIST highlight demographic false positive dependence?
NIST has of course explored the demographic effects of face recognition for years, and the “Demographics: False Positive Dependence” tab provides additional tracking for this.
Why does NIST do this?
“False positives occur when searches return wrong identities. Such outcomes have application-dependent consequences, which can be serious.”
How does NIST highlight demographic false positive dependence?
Anyway, NIST created the “Demographics: False Positive Dependence” tab.
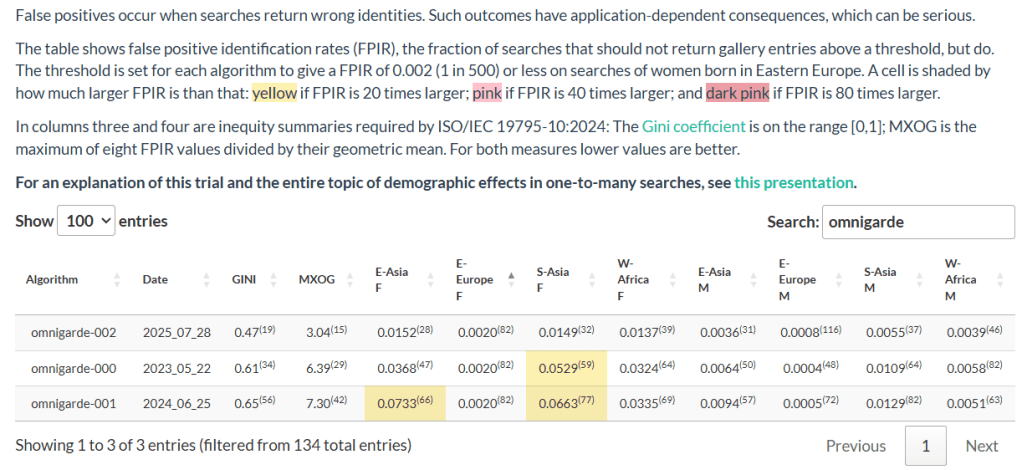
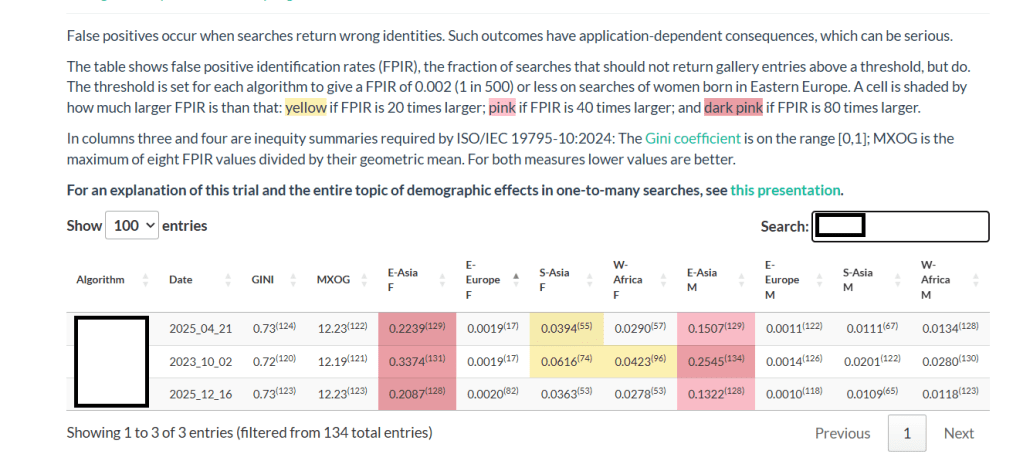
“The table shows false positive identification rates (FPIR), the fraction of searches that should not return gallery entries above a threshold, but do. The threshold is set for each algorithm to give a FPIR of 0.002 (1 in 500) or less on searches of women born in Eastern Europe.”
And for algorithms that have “anomalously high values” in other demographic populations, NIST has added the color coding.
“A cell is shaded by how much larger FPIR is than that: yellow if FPIR is 20 times larger; pink if FPIR is 40 times larger; and dark pink if FPIR is 80 times larger.”
What does the highlighting look like?
Let me illustrate this with the results from the three algorithms Omnigarde submitted.
Data captured April 8, 2026. Omnigarde.
Omnigarde’s first two algorithms, submitted in 2023 and 2024, exhibited high FPIR values for south Asian females, and the second algorithm also exhibited a high FPIR value for east Asian females. See the color coding.
The third algorithm, submitted in 2025, had lower FPIR values for these populations and thus no yellow color coding.
Even the less-stellar algorithms show improvement over time.
Data captured April 8, 2026. Anonymized (but you can figure it out if you’re curious).
Final thoughts
Both vendors and customers/prospects can rightfully question whether this is helpful or hurtful. I lean toward “helpful,” because if the facial recognition algorithm you use provides high false positives for certain popularions, you need to know.
And as always, law enforcement in the United States should NEVER solely rely on facial recognition results as the basis for an arrest…even for Eastern European females. They should ONLY be an investigative lead.
In the meantime, take care of yourself, and each other.
The National Institute of Standards and Technology (NIST) isn’t the only entity that is seeking to combat facial recognition demographic bias. The Center for Identification Technology Research (CITeR) is doing its part.
The Problem
NIST and other entities have documented facial recognition accuracy differences related to skin tone. This is separate from the topic of facial analysis: this relates to facial recognition, or the identification of an individual. (As a note, “Gender Shades” had NOTHING to do with facial recognition.)
It’s fair to summarize that the accuracy of an algorithm depends upon the data used to train the algorithm. For example, if an algorithm is trained entirely on Japanese people, you would expect that it would be very accurate in identifying Japanese, but less accurate in identifying Native Americans or Kenyans.
Many of the most-used facial recognition algorithms are authored by North American/European or Asian companies, and while the good ones seek to employ a broad data set for algorithm training, NIST and other results document clear demographic differences in accuracy.
The Research
The Center for Identification Technology Research (CITeR) is a consortium of universities, government agencies, and private entities. The lead entity in CITeR, Clarkson University, has initiated research on “improving equity in face recognition systems.” Clarkson is using the following methods:
Establish a continuous skin color metric that retains accuracy across different image acquisition environments.
Develop a statistical approach to measure equity, ensuring FR results fall within a precise margin of error.
Employ new FR systems in combination with or instead of existing measures to minimize bias of results.
In this work, Clarkson is cooperating with other entities, such as the International Organization for Standardization (ISO) and the FIDO Alliance.
The final goal is to make facial recognition usable for everyone.
Your problem
Is your identity company and its product marketers also working to reduce demographic bias? How are you telling your story? Bredemarket (the biometric product marketing expert) can help with strategic and tactical solutions for your marketing and writing needs.
Bredemarket services, process, and pricing.
If I can help your firm with analysis, content, or even proposals in this area, talk to me.
As I’ve noted before, healthcare is a pioneering user of artificial intelligence, although (hopefully) under robust controls to maintain accuracy and preserve HIPAA-level privacy.
“We are living through a generational shift, one where AI doesn’t just augment how organizations work but fundamentally transforms them from the inside out,” said Mohamad Makhzoumi, Co-CEO of NEA, who will join Qualified Health’s Board of Directors in conjunction with the financing. “From NEA’s nearly five decades of company-building experience, we believe the organizations shaping the next era of healthcare innovation will be those helping health systems reimagine every administrative and clinical workflow from the ground up, and Qualified Health is exactly that company. We are thrilled to lead this financing and to partner with Justin and team to accelerate healthcare’s AI transformation and shape the future of healthcare enterprises across the country.”
“Health systems today are operating under extraordinary pressure, from rising labor costs to tightening reimbursement, while managing increasing complexity in patient care,” said Jared Kesselheim, MD, Managing Partner at Transformation Capital. “What stood out to us about Qualified Health is that the team approaches this work as medical care specialists, with a deep understanding of the realities health systems face every day. That perspective allows them to identify where AI can create meaningful clinical and operational impact. We’re excited to partner with Justin and the Qualified Health team as they help leading health systems navigate this next phase of healthcare.”
Another topic raised by Nadaa Taiyab during today’s SoCal Tech Forum meeting was ambient clinical intelligence. See her comments on how AI benefits diametrically opposing healthcare entities here.
There are three ways that a health professional can create records during, and/or after, a patient visit.
Typing. The professional has their hands on the keyboard during the meeting, which doesn’t make a good impression on the patient.
Structured dictation. The professional can actually look at the patient, but the dictation is unnatural. As Bredebot characterizes it: “where you have to speak specific commands like ‘Period’ or ‘New Paragraph.’”
“Ambient clinical intelligence, or ACI, is advanced, AI-powered voice recognizing technology that quietly listens in on clinical encounters and aids the medical documentation process by automating medical transcription and note taking. This all-encompassing technology has the ability to totally transform the lives of clinicians, and thus healthcare on every level.”
Like any generative AI model, ambient clinical intelligence has to provide my four standard benefits: accuracy, ease of use, security, and speed.
Accuracy is critically important in any health application, since inaccurate coding could literally affect life or death.
Ease of use is of course the whole point of ambient clinical intelligence, since it replaces harder-to-use methods.
Security and privacy are necessary when dealing with personal health information (PHI).
Speed is essential also. As Taiyab noted elsewhere in her talk, the work is increasing and the workforce not increasing as rapidly.
But if the medical professional and patient benefit from the accuracy, ease of use, security, and speed of ambient clinical intelligence, we all win.
I previously mused about an alternative universe in which a single human body had ten (different) faces.
Facial recognition would be more accurate if biometric systems had ten faces to match. (Kind of like you-know-what.)
Well, now I’m getting ridiculous by musing about a person with one hundred faces for identification.
Grok.
When I’m not musing about alternative universes with different biometrics, I’m helping identity/biometric firms market their products in this one.
And this frivolous exercise actually illustrates a significant difference between fingerprints and faces, especially in use cases where subjects submit all ten fingerprints but only a single face. The accuracy benefits are…well, they’re ten times more powerful.
Are there underlying benefits in YOUR biometric technology that you want to highlight? Bredemarket can help you do this. Book a free meeting with me, and I’ll ask you some questions to figure out where we can work together.
This post concentrates on IDENTIFICATION perfection, or the ability to enjoy zero errors when identifying individuals.
The risk of claiming identification perfection (or any perfection) is that a SINGLE counter-example disproves the claim.
If you assert that your biometric solution offers 100% accuracy, a SINGLE false positive or false negative shatters the assertion.
If you claim that your presentation attack detection solution exposes deepfakes (face, voice, or other), then a SINGLE deepfake that gets past your solution disproves your claim.
And as for the pre-2009 claim that latent fingerprint examiners never make a mistake in an identification…well, ask Brandon Mayfield about that one.
In fact, I go so far as to avoid using the phrase “no two fingerprints are alike.” Many years ago (before 2009) in an International Association for Identification meeting, I heard someone justify the claim by saying, “We haven’t found a counter-example yet.” That doesn’t mean that we’ll NEVER find one.
At first glance, it appears that Motorola would be the last place to make a boneheaded mistake like that. After all, Motorola is known for its focus on quality.
But in actuality, Motorola was the perfect place to make such a mistake, since it was one of the champions of the “Six Sigma” philosophy (which targets a maximum of 3.4 defects per million opportunities). Motorola realized that manufacturing perfection is impossible, so manufacturers (and the people in Motorola’s weird Biometric Business Unit) should instead concentrate on reducing the error rate as much as possible.
So one misspelling could be tolerated, but I shudder to think what would have happened if I had misspelled “quality” a second time.
I wanted to illustrate the difference between biometric writing, and SUBSTANTIVE biometric writing.
A particular company recently promoted its release of a facial recognition application. The application was touted as “state-of-the-art,” and the press release mentioned “high accuracy.” However, the press release never supported the state-of-the-art or high accuracy claims.
Concentrating on the high accuracy claim, there are four methods in which a biometric vendor (facial recognition, fingerprint identification, iris recognition, whatever) can substantiate a high accuracy claim. This particular company did not employ ANY of these methods.
The first method is to publicize the accuracy results of a test that you designed and conducted yourself. This method has its drawbacks, since if you’re administering your own test, you have control over the reported results. But it’s better than nothing.
The second method is for you to conduct a test that was designed by someone else. An example of such a test is Labeled Faces in the Wild (LFW). There used to be a test called Megaface, but this project has concluded. A test like this is good for research, but there are still issues; for example, if you don’t like the results, you just don’t submit them.
The third method is to have an independent third party design AND conduct the test, using test data. A notable example of this method is the Facial Recognition Vendor Test series sponsored by the U.S. National Institute of Standards and Technology. Yet even this test has drawbacks for some people, since the data used to conduct the test is…test data.
The fourth method, which could be employed by an entity (such as a government agency) who is looking to purchase a biometric system, is to have the entity design and conduct the test using its own data. Of course, the results of an accuracy test conducted using the biometric data of a local police agency in North America cannot be applied to determine the accuracy of a national passport system in Asia.
So, these are four methods to substantiate a “high accuracy” claim. Each method has its advantages and disadvantages, and it is possible for a vendor to explain WHY it chose one method over the other. (For example, one facial recognition vendor explained that it couldn’t submit its application for NIST FRVT testing because the NIST testing design was not compatible with the way that this vendor’s application worked. For this particular vendor, methods 1 and 4 were better ways to substantiate its accuracy claims.)
But if a company claims “high accuracy” without justifying the claim with ANY of these four methods, then the claim is meaningless. Or, it’s “biometric writing” without substantiation.