Money 20/20 is taking place in Las Vegas, Nevada, USA from Sunday, October 22 to Wednesday October 25.
While I am not in Las Vegas, Bredemarket will monitor the goings-on and share relevant news on Facebook (Bredemarket Identity Firm Services group), Instagram (Bredemarket), LinkedIn (Bredemarket Identity Firm Services page), bredemarket.com, and elsewhere.
For example, when biometric companies want to justify the use of their technology, they have found that it is very effective to position biometrics as a way to combat sex trafficking.
Similarly, moves to rein in social media are positioned as a way to preserve mental health.
Now that’s a not-so-pretty picture, but it effectively speaks to emotions.
“If poor vulnerable children are exposed to addictive, uncontrolled social media, YOUR child may end up in a straitjacket!”
In New York state, four government officials have declared that the ONLY way to preserve the mental health of underage social media users is via two bills, one of which is the “New York Child Data Protection Act.”
But there is a challenge to enforce ALL of the bill’s provisions…and only one way to solve it. An imperfect way—age estimation.
Because they want to protect the poor vulnerable children.
By Paolo Monti – Available in the BEIC digital library and uploaded in partnership with BEIC Foundation.The image comes from the Fondo Paolo Monti, owned by BEIC and located in the Civico Archivio Fotografico of Milan., CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=48057924
And because the major U.S. social media companies are headquartered in California. But I digress.
So why do they say that children need protection?
Recent research has shown devastating mental health effects associated with children and young adults’ social media use, including increased rates of depression, anxiety, suicidal ideation, and self-harm. The advent of dangerous, viral ‘challenges’ being promoted through social media has further endangered children and young adults.
Of course one can also argue that social media is harmful to adults, but the New Yorkers aren’t going to go that far.
So they are just going to protect the poor vulnerable children.
CC BY-SA 4.0.
This post isn’t going to deeply analyze one of the two bills the quartet have championed, but I will briefly mention that bill now.
The “Stop Addictive Feeds Exploitation (SAFE) for Kids Act” (S7694/A8148) defines “addictive feeds” as those that are arranged by a social media platform’s algorithm to maximize the platform’s use.
Those of us who are flat-out elderly vaguely recall that this replaced the former “chronological feed” in which the most recent content appeared first, and you had to scroll down to see that really cool post from two days ago. New York wants the chronological feed to be the default for social media users under 18.
The bill also proposes to limit under 18 access to social media without parental consent, especially between midnight and 6:00 am.
And those who love Illinois BIPA will be pleased to know that the bill allows parents (and their lawyers) to sue for damages.
Previous efforts to control underage use of social media have faced legal scrutinity, but since Attorney General James has sworn to uphold the U.S. Constitution, presumably she has thought about all this.
Enough about SAFE for Kids. Let’s look at the other bill.
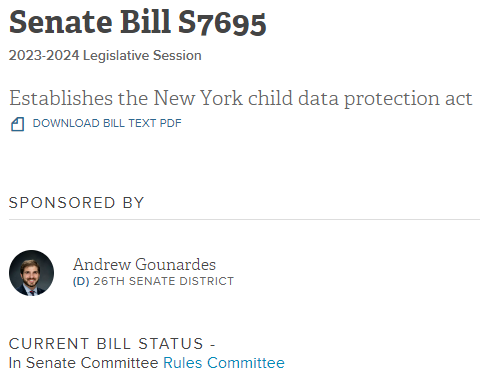
The New York Child Data Protection Act
The second bill, and the one that concerns me, is the “New York Child Data Protection Act” (S7695/A8149). Here is how the quartet describes how this bill will protect the poor vulnerable children.
CC BY-SA 4.0.
With few privacy protections in place for minors online, children are vulnerable to having their location and other personal data tracked and shared with third parties. To protect children’s privacy, the New York Child Data Protection Act will prohibit all online sites from collecting, using, sharing, or selling personal data of anyone under the age of 18 for the purposes of advertising, unless they receive informed consent or unless doing so is strictly necessary for the purpose of the website. For users under 13, this informed consent must come from a parent.
And again, this bill provides a BIPA-like mechanism for parents or guardians (and their lawyers) to sue for damages.
But let’s dig into the details. With apologies to the New York State Assembly, I’m going to dig into the Senate version of the bill (S7695). Bear in mind that this bill could be amended after I post this, and some of the portions that I cite could change.
This only applies to natural persons. So the bots are safe, regardless of age.
Speaking of age, the age of 18 isn’t the only age referenced in the bill. Here’s a part of the “privacy protection by default” section:
§ 899-FF. PRIVACY PROTECTION BY DEFAULT.
1. EXCEPT AS PROVIDED FOR IN SUBDIVISION SIX OF THIS SECTION AND SECTION EIGHT HUNDRED NINETY-NINE-JJ OF THIS ARTICLE, AN OPERATOR SHALL NOT PROCESS, OR ALLOW A THIRD PARTY TO PROCESS, THE PERSONAL DATA OF A COVERED USER COLLECTED THROUGH THE USE OF A WEBSITE, ONLINE SERVICE, ONLINE APPLICATION, MOBILE APPLICA- TION, OR CONNECTED DEVICE UNLESS AND TO THE EXTENT:
(A) THE COVERED USER IS TWELVE YEARS OF AGE OR YOUNGER AND PROCESSING IS PERMITTED UNDER 15 U.S.C. § 6502 AND ITS IMPLEMENTING REGULATIONS; OR
(B) THE COVERED USER IS THIRTEEN YEARS OF AGE OR OLDER AND PROCESSING IS STRICTLY NECESSARY FOR AN ACTIVITY SET FORTH IN SUBDIVISION TWO OF THIS SECTION, OR INFORMED CONSENT HAS BEEN OBTAINED AS SET FORTH IN SUBDIVISION THREE OF THIS SECTION.
So a lot of this bill depends upon whether a person is over or under the age of eighteen, or over or under the age of thirteen.
And that’s a problem.
How old are you?
The bill needs to know whether or not a person is 18 years old. And I don’t think the quartet will be satisfied with the way that alcohol websites determine whether someone is 21 years old.
Attorney General James and the others would presumably prefer that the social media companies verify ages with a government-issued ID such as a state driver’s license, a state identification card, or a national passport. This is how most entities verify ages when they have to satisfy legal requirements.
For some people, even some minors, this is not that much of a problem. Anyone who wants to drive in New York State must have a driver’s license, and you have to be at least 16 years old to get a driver’s license. Admittedly some people in the city never bother to get a driver’s license, but at some point these people will probably get a state ID card.
However, there are going to be some 17 year olds who don’t have a driver’s license, government ID or passport.
And some 16 year olds.
And once you look at younger people—15 year olds, 14 year olds, 13 year olds, 12 year olds—the chances of them having a government-issued identification document are much less.
What are these people supposed to do? Provide a birth certificate? And how will the social media companies know if the birth certificate is legitimate?
But there’s another way to determine ages—age estimation.
How old are you, part 2
As long-time readers of the Bredemarket blog know, I have struggled with the issue of age verification, especially for people who do not have driver’s licenses or other government identification. Age estimation in the absence of a government ID is still an inexact science, as even Yoti has stated.
Our technology is accurate for 6 to 12 year olds, with a mean absolute error (MAE) of 1.3 years, and of 1.4 years for 13 to 17 year olds. These are the two age ranges regulators focus upon to ensure that under 13s and 18s do not have access to age restricted goods and services.
So if a minor does not have a government ID, and the social media firm has to use age estimation to determine a minor’s age for purposes of the New York Child Data Protection Act, the following two scenarios are possible:
An 11 year old may be incorrectly allowed to give informed consent for purposes of the Act.
A 14 year old may be incorrectly denied the ability to give informed consent for purposes of the Act.
Is age estimation “good enough for government work”?
It’s the end of an era for a once-critical pandemic document: The ubiquitous white COVID-19 vaccination cards are being phased out.
Now that COVID-19 vaccines are not being distributed by the federal government, the U.S. Centers for Disease Control and Prevention has stopped printing new cards.
This doesn’t affect the validity of current cards. It just means that if you get a COVID vaccine, or any future vaccine, and you need to prove you obtained it, you will have to contact the medical facility who administered it.
Or, in selected states (because in the U.S. health is generally a state and not a federal responsibility), you can access the state’s digital health information. For example, the state of Washington offers MyIRmobile, as do the states of Arizona, Louisiana, Maryland, Mississippi, North Dakota, and West Virginia.
Sign up for MyIR Mobile by going to myirmobile.com and follow the registration instructions. Your registration information will be used to match your records with the state immunization registry. You will be sent a verification code on your phone to finalize the process. Once registration is complete, you’ll be able to view your immunization records, Certificate of Immunization Status (CIS) and access your COVID-19 vaccination certificate.
And one of those records was so unmemorable that it was memorable.
The album, recorded in the early to mid 1960s, trumpeted the fact that the group that recorded the album was extremely versatile. You see, the record not only included surf songs, but also included car songs!
The only problem? The album was NOT by the Beach Boys.
Instead, the album was from some otherwise unknown band that was trying to achieve success by doing what the competition did. (In this case, the Beach Boys.)
I can’t remember the name of the band, and I bet no one else can either.
“Me too” in computing and lawn care
Sadly, this tactic of Xeroxing (or Mitaing) the competition is not confined to popular music. Have you noticed that so many recipes for marketing success involve copying what your competitors do?
Semrush: “Analyze your competitors’ keywords that you are not ranking for to discover gaps in your SEO strategy.”
iSpionage: “If you can emulate your competitors but do things slightly better you have a good chance of being successful.”
Someone who shall remain nameless: “Look at this piece of collateral that one of our competitors did. We should do something just like that.”
And of course the tactic of slavishly copying competitors has been proven to work. For example, remember when Apple Computer adopted the slogan “Think The Same” as the company dressed in blue, ensured all its computers could run MS-DOS, and otherwise imitated everything that IBM did?
“But John,” you are saying. “That’s unfair. Not everyone can be Apple.”
My point exactly. Everyone can’t be Apple because they’re so busy trying to imitate someone else—either a competitor or some other really popular company.
Personally, I’m waiting for some company to claim to be “the Bredemarket of satellite television. (Which would simply mean that the company would have a lot of shows about wildebeests.) But I’ll probably have to wait a while for some company to be the Bredemarket of anything.
(An aside: while talking with a friend, I compared the British phrase “eating your pudding” to the American phrase “eating your own dog food,” although I noted that “I like to say ‘eating your own wildebeest food‘ just to stand out.” Let’s see ChatGPT do THAT.)
“Me too” in identity verification
Now I’ll tread into more dangerous territory.
Here’s an example from the identity/biometric world. Since I self-identity (heh) as the identity content marketing expert, I’m supremely qualified to cite this example.
I spent a year embedded in the identity verification industry, and got to see the messaging from my own company and by the competition.
After a while, I realized that most of the firms in the industry were saying the same thing. Here are a few examples. See if you can spot the one word that EVERY company is using:
(Company I) “Reimagine trust.”
(Company J) “To protect against fraud and financial crime, businesses online need to know and trust that their customers are who they claim to be — and that these customers continue to be trustworthy.”
(Company M) “Trust is the core of any successful business relationship. As the digital revolution continues to push businesses and financial industries towards digital-first services, gaining digital trust with consumers will be of utmost importance for survival.”
(Company O) “Create trust at onboarding and beyond with a complete, AI-powered digital identity solution built to help you know your customers online.”
(Company P) “Trust that users are who they say they are, and gain their trust by humanizing the identity experience.”
(Company V) “Stop fraud. Build trust. Identity verification made simple.”
Yes, these companies, and many others, prominently feature the t-word in their messaging.
Now perhaps some of you would argue that trust is essential to identity verification in the same way that water is essential to an ocean, and that therefore EVERYBODY HAS to use the t-word in their communications.
After all, if I was going to create content for this prospect, we had to ensure that the content stood out from their competitors.
Without revealing confidential information, I can say that I asked the firm why they were better than every other firm out there, and why all the other firms sucked. And the firm provided me with a compelling answer to that question. I can’t reveal that answer, but you can probably guess that the word “trust” was not involved.
A final thought
So let me ask you:
Why is YOUR firm better than every other firm out there, and why do all or YOUR competitors suck?
Your firm’s survival may depend upon communicating that answer.
Identity and biometrics firms can achieve quantifiable benefits with prospects by blogging. Over 40 identity and biometrics firms are already blogging. Is yours?
These firms (and probably many more) already recognize the value of identity blog post writing, and some of them are blogging frequently to get valuable content to their prospects and customers.
Is your firm on the list? If so, how frequently do you update your blog?
In most cases, I can provide your blog post via my standard package, the Bredemarket 400 Short Writing Service. I offer other packages and options if you have special needs.
Get in touch with Bredemarket
Authorize Bredemarket, Ontario California’s content marketing expert, to help your firm produce words that return results.
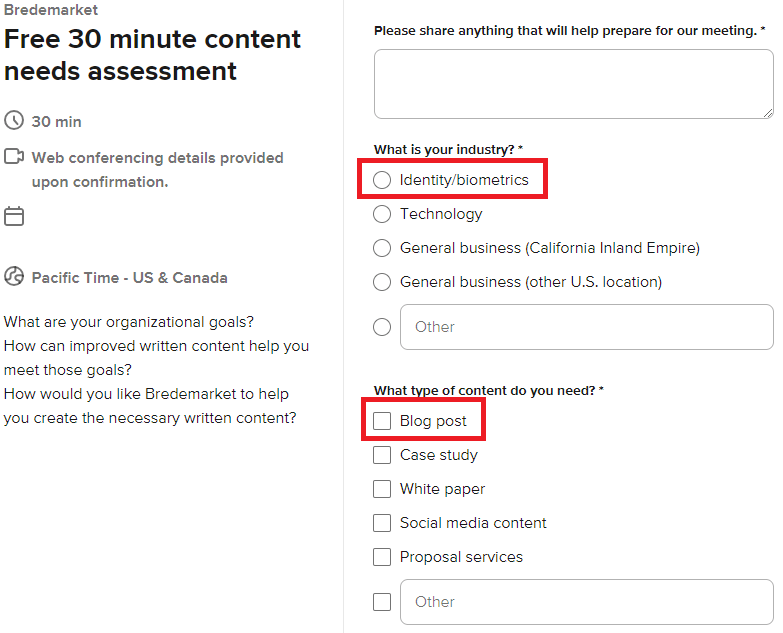
To discuss your identity/biometrics blog post needs further,book a meeting with me at calendly.com/bredemarket. On the questionnaire, select the Identity/biometrics industry and Blog post content.
But are computerized systems any better, and can they detect spoofed voices?
Well, in the same way that fingerprint readers worked to overcome gummy bears, voice readers are working to overcome deepfake voices.
This is only the beginning of the war against voice spoofing. Other companies will pioneer new advances that will tell the real voices from the fake ones.
As for independent testing:
ID R&D has participated in multiple ASVspoof tests, and performed well in them.
Let’s address two items before we continue. Trust me; it’s important.
The Gender Shades study evaluated only three algorithms: one from IBM, one from Microsoft, and one from Face++. It did not evaluate the hundreds of other facial recognition algorithms that existed in 2018 when the study was released.
The study focused on gender classification and race classification. Back in those primitive innocent days of 2018, the world assumed that you could look at a person and tell whether the person was male or female, or tell the race of a person. (The phrase “self-identity” had not yet become popular, despite the Rachel Dolezal episode which happened before the Gender Shades study). Most importantly, the study did not address identification of individuals at all.
Back in 2002, this news WAS really “scary,” since it suggested that you could access a fingerprint reader-protected site with something that wasn’t a finger. Gelatin. A piece of metal. A photograph.
Except that the fingerprint reader world didn’t stand still after 2002, and the industry developed ways to detect spoofed fingers.
Yes, I’m stealing the Biometric Update practice of combining multiple items into a single post, but this lets me take a brief break from identity (mostly) and examine three general technology stories:
Advances in speech neuroprosthesis (the Pat Bennett / Stanford University story).
The benefits of Dynamic Media for Adobe Enterprise Manager users, as described by KBWEB Consult.
The benefits of graph databases for Identity and Access Management (IAM) implementations, as described by IndyKite.
Neuroprosthetics “is a discipline related to neuroscience and biomedical engineering concerned with developing neural prostheses, artificial devices to replace or improve the function of an impaired nervous system.
Various news sources highlighted the story of amyotrophic lateral sclerosis (ALS) patient Pat Bennett and her somewhat-enhanced ability to formulate words, resulting from research at Stanford University.
Because I was curious, I sought the Nature article that discussed the research in detail, “A high-performance speech neuroprosthesis.” The article describes a proof of concept of a speech brain-computer interface (BCI).
Here we demonstrate a speech-to-text BCI that records spiking activity from intracortical microelectrode arrays. Enabled by these high-resolution recordings, our study participant—who can no longer speak intelligibly owing to amyotrophic lateral sclerosis—achieved a 9.1% word error rate on a 50-word vocabulary (2.7 times fewer errors than the previous state-of-the-art speech BCI2) and a 23.8% word error rate on a 125,000-word vocabulary (the first successful demonstration, to our knowledge, of large-vocabulary decoding). Our participant’s attempted speech was decoded at 62 words per minute, which is 3.4 times as fast as the previous record8 and begins to approach the speed of natural conversation (160 words per minute9).
For Bennett, the (ALS) deterioration began not in her spinal cord, as is typical, but in her brain stem. She can still move around, dress herself and use her fingers to type, albeit with increasing difficulty. But she can no longer use the muscles of her lips, tongue, larynx and jaws to enunciate clearly the phonemes — or units of sound, such as sh — that are the building blocks of speech….
After four months, Bennett’s attempted utterances were being converted into words on a computer screen at 62 words per minute — more than three times as fast as the previous record for BCI-assisted communication.
Now let’s shift to companies that need to produce marketing collateral. Bredemarket produces collateral, but not to the scale that big companies need to produce. A single company may have to produce millions of pieces of collateral, each of which is specific to a particular product, in a particular region, for a particular audience/persona. Even Bredemarket could potentially produce all sorts of content, if it weren’t so difficult to do so:
An Instagram carousel post about the Bredemarket 400 Short Writing Service, targeted to voice sales executives in the identity industry.
A TikTok reel about the Bredemarket 400 Short Writing Service, targeted to marketing executives in the AI industry.
All of this specialized content, using all of these different image and video formats? I’m not gonna create all that.
But as KBWEB Consult (a boutique technology consulting firm specializing in the implementation and delivery of Adobe Enterprise Cloud technologies) points out in its article “Implementing Rapid Omnichannel Messaging with AEM Dynamic Media,” Adobe Experience Manager has tools to speed up this process and create correctly-messaged content in ALL the formats for ALL the audiences.
One of those tools is Dynamic Media.
AEM Dynamic Media accelerates omnichannel personalization, ensuring your business messages are presented quickly and in the proper formats. Starting with a master file, Dynamic Media quickly adjusts images and videos to satisfy varying asset specifications, contributing to increased content velocity.
A graph database, also referred to as a semantic database, is a software application designed to store, query and modify network graphs. A network graph is a visual construct that consists of nodes and edges. Each node represents an entity (such as a person) and each edge represents a connection or relationship between two nodes.
Graph databases have been around in some variation for along time. For example, a family tree is a very simple graph database….
Graph databases are well-suited for analyzing interconnections…
To see how this applies to identity and access management (IAM), I’ll turn to IndyKite, whose Lasse Andersen recently presented on graph database use in IAM (in a webinar sponsored by Strativ Group). IndyKite describes its solution as follows (in part):
A knowledge graph that holistically captures the identities of customers and IoT devices along with the rich relationships between them
A dynamic and real-time data model that unifies disconnected identity data and business metadata into one contextualized layer
Yes, I know that every identity company (with one exception) uses the word “trust,” and they all use the word “seamless.”
But this particular technology benefits banking customers (at least the honest ones) by using the available interconnections to provide all the essential information about the customer and the customer’s devices, in a way that does not inconvenience the customer. IndyKite claims “greater privacy and security,” along with flexibility for future expansion.
In other words, it increases velocity.
What is your technology story?
I hope you provided this quick overview of these three technology advances.
But do you have a technology story that YOU want to tell?
Perhaps Bredemarket, the technology content marketing expert, can help you select the words to tell your story. If you’re interested in talking, let me know.