As some of you know, I’m seeking full-time employment after my former employer let me go in late May. As part of my job search, I was recently invited to a second interview for a company in my industry. Before that interview, I made an important decision about how I was going to present myself.
If you’ve read any of Bredemarket’s content, there are times when it takes a light tone, in which wildebeests roam the earth while engaging in marketing activities such as elaborating the benefits of crossing the stream.
Some of that DOES NOT fly in the corporate world. (For most companies, anyway.) If you analyze a wide selection of corporate blogs, you won’t see the word “nothingburger.” But you do here.
So as I prepared for this important job interview, I made sure that I was ready to discuss the five factors of authentication, and my deep experience as an identity content marketing expert with many of those factors.
The five factors of authentication, of course, are:
For the purposes of this job interview, there isn’t! I confined myself to the five factors only during the discussion, using examples such as passwords, driver’s licenses, faces, actions, and smartphone geolocation information.
But in the end, my caution was of no avail. I DIDN’T make it to the next stage of interviews.
Maybe I SHOULD have mentioned “Somewhat you why” after all.
It’s been years since I talked about Identity Assurance Levels (IALs) in any detail, but I wanted to delve into two of the levels and see when IAL3 is necessary, and when it is not.
The U.S. National Institute of Standards and Technology has defined “identity assurance levels” (IALs) that can be used when dealing with digital identities. It’s helpful to review how NIST has defined the IALs.
Assurance in a subscriber’s identity is described using one of three IALs:
IAL1: There is no requirement to link the applicant to a specific real-life identity. Any attributes provided in conjunction with the subject’s activities are self-asserted or should be treated as self-asserted (including attributes a [Credential Service Provider] CSP asserts to an [Relying Party] RP). Self-asserted attributes are neither validated nor verified.
IAL2: Evidence supports the real-world existence of the claimed identity and verifies that the applicant is appropriately associated with this real-world identity. IAL2 introduces the need for either remote or physically-present identity proofing. Attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL2 can support IAL1 transactions if the user consents.
IAL3: Physical presence is required for identity proofing. Identifying attributes must be verified by an authorized and trained CSP representative. As with IAL2, attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL3 can support IAL1 and IAL2 identity attributes if the user consents.
For purposes of this post, IAL1 is (if I may use a technical term) a nothingburger. It may be good enough for a Gmail account, but these days even social media accounts are more likely to require IAL2.
So what’s the practical difference between IAL2 and IAL3?
If we ignore IAL1 and concentrate on IAL2 and IAL3, we can see one difference between the two. IAL2 allows remote, unsupervised identity proofing, while IAL3 requires (in practice) that any remote identity proofing is supervised.
Much of my time at my previous employer Incode Technologies involved unsupervised remote identity proofing (IAL2). For example, if a woman wants to set up an account at a casino, she can complete the onboarding process to set up the account on her phone, without anyone from the casino being present to make sure she wasn’t faking her face or her ID. (Fraud detection is the “technologies” part of Incode Technologies, and that’s how they make sure she isn’t faking.)
SRIP provides remote supervision of in-person proofing using NextgenID’s Identity Stations, an all-in-one system designed to securely perform all enrollment processes and workflow requirements. The station facilitates the complete and accurate capture at IAL levels 1, 2 and 3 of all required personal identity documentations and includes a full complement of biometric capture support for face, fingerprint, and iris.
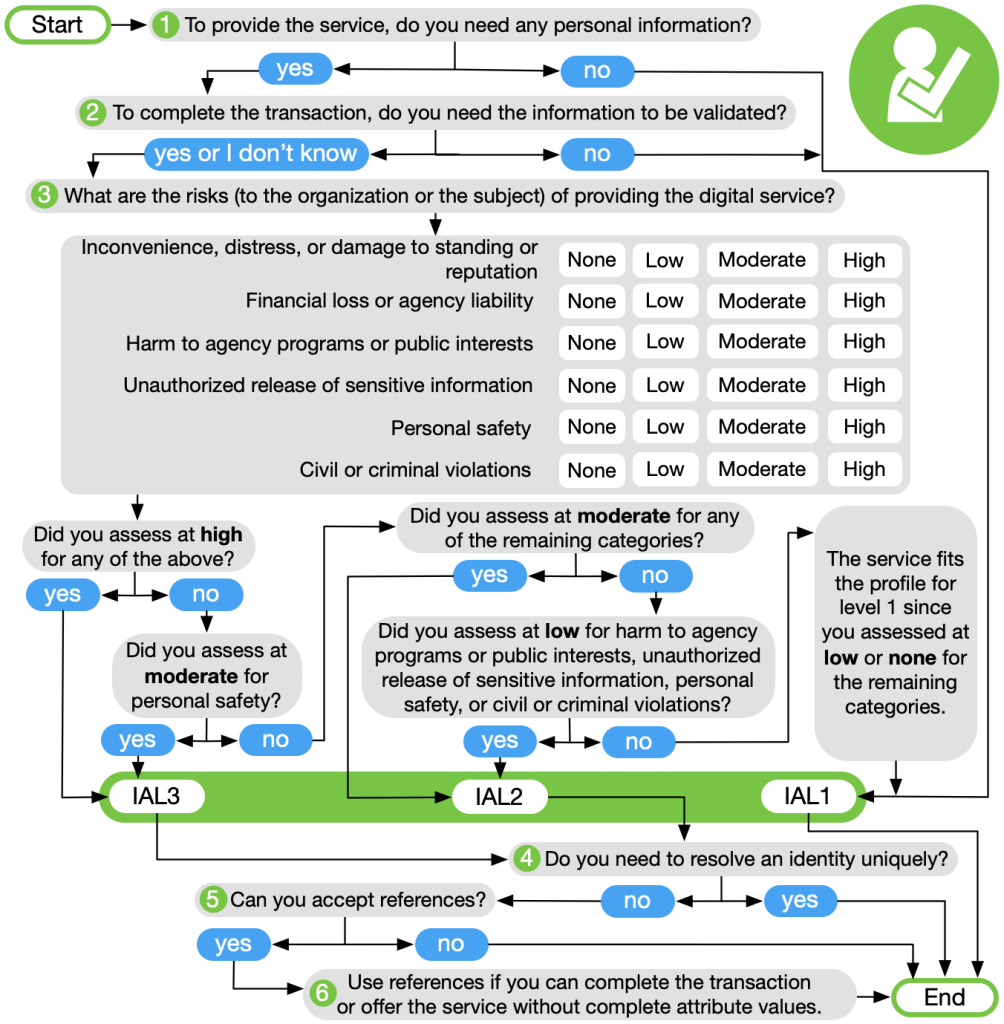
Now there are some other differences between IAL2 and IAL3 in terms of the proofing, so NIST came up with a handy dandy chart that allows you to decide which IAL level you need.
At this point, the agency understands that some level of proofing is required. Step 3 is intended to look at the potential impacts of an identity proofing failure to determine if IAL2 or IAL3 is the most appropriate selection. The primary identity proofing failure an agency may encounter is accepting a falsified identity as true, therefore providing a service or benefit to the wrong or ineligible person. In addition, proofing, when not required, or collecting more information than needed is a risk in and of itself. Hence, obtaining verified attribute information when not needed is also considered an identity proofing failure. This step should identify if the agency answered Step 1 and 2 incorrectly, realizing they do not need personal information to deliver the service. Risk should be considered from the perspective of the organization and to the user, since one may not be negatively impacted while the other could be significantly harmed. Agency risk management processes should commence with this step.
Even with the complexity of the flowchart, some determinations can be pretty simple. For example, if any of the six risks listed under question 3 are determined to be “high,” then you must use IAL3.
But the whole exercise is a lot to work through, and you need to work through it yourself. When I pasted the PNG file for the flowchart above into this blog post, I noticed that the filename is “IAL_CYOA.png.” And we all know what “CYOA” means.
But if you do the work, you’ll be better informed on the procedures you need to use to verify the identities of people.
One footnote: although NIST is a U.S. organization, its identity assurance levels (including IAL2 and IAL3) are used worldwide, including by the World Bank. So everyone should be familiar with them.
Depending upon whom you ask, there are either three or five factors of authentication.
Unless you ask me.
I say that there are six.
Let me explain.
First I’ll discuss what factors of authentication are, then I’ll talk about the three factor and five factor school, then I’ll briefly review my thoughts on the sixth factor—now that I know what I’ll call it.
For example, if Warren Buffett has a bank account, and I claim that I am Warren Buffett and am entitled to take money from that bank account, I must complete an authentication process to determine whether I am entitled to Warren Buffett’s money. (Spoiler alert: I’m not.)
An authentication factor is a special category of security credential that is used to verify the identity and authorization of a user attempting to gain access, send communications, or request data from a secured network, system or application….Each authentication factor represents a category of security controls of the same type.
When considering authentication factors, the whole group/category/type definition is important. For example, while a certain system may require both a 12-character password and a 4-digit personal identification number (PIN), these are pretty much the same type of authentication. It’s just that the password is longer than the PIN. From a security perspective, you don’t gain a lot by requiring both a password and a PIN. You would gain more by choosing a type of authentication that is substantially different from passwords and PIN.
How many factors of authentication are there?
So how do we define the factors of authentication? Different people have different definitions.
Factors include: (i) something you know (e.g. password/personal identification number (PIN)); (ii) something you have (e.g., cryptographic identification device, token); or (iii) something you are (e.g., biometric).
Note that NIST’s three factors are very different from one another. Knowing something (such as a password or a PIN) differs from having something (such as a driver’s license) or being something (a fingerprint or a face).
But some people believe that there are more than three factors of authentication.
Over the months, I struggled through some examples of the “why” factor.
Why is a person using a credit card at a McDonald’s in Atlantic City? (Link) Or, was the credit card stolen, or was it being used legitimately?
Why is a person boarding a bus? (Link) Or, was the bus pass stolen, or was it being used legitimately?
Why is a person standing outside a corporate office with a laptop and monitor? (Link) Or, is there a legitimate reason for an ex-employee to gain access to the corporate office?
As I refined my thinking, I came to the conclusion that “why” is a reasonable factor of authentication, and that this was separate from the other authentication factors (such as “something you do”).
And the sixth factor of authentication is called…
You’ll recall that I wanted to cast this sixth authentication factor into the “some xxx you xxx” format.
So, as of today, here is the official Bredemarket list of the six factors of authentication:
Something you know.
Something you have.
Something you are.
Something you do.
Somewhere you are.
(Drumroll…)
Somewhat you why.
Yes, the name of this factor stands out from the others like a sore thumb (probably a loop).
However, the performance of this factor stands out from the others. If we can develop algorithms that accurately measure the “why” reasonableness of something as a way to authenticate identity, then our authentication capabilities will become much more powerful.
I’ll admit that I previously thought that age estimation was worthless, but I’ve since changed my mind about the necessity for it. Which is a good thing, because the U.S. National Institute of Standards and Technology (NIST) is about to add age estimation to its Face Recognition Vendor Test suite.
What is age estimation?
Before continuing, I should note that age estimation is not a way to identify people, but a way to classify people. For once, I’m stepping out of my preferred identity environment and looking at a classification question. Not “gender shades,” but “get off my lawn” (or my tricycle).
Age estimation uses facial features to estimate how old a person is, in the absence of any other information such as a birth certificate. In a Yoti white paper that I’ll discuss in a minute, the Western world has two primary use cases for age estimation:
First, to estimate whether a person is over or under the age of 18 years. In many Western countries, the age of 18 is a significant age that grants many privileges. In my own state of California, you have to be 18 years old to vote, join the military without parental consent, marry (and legally have sex), get a tattoo, play the lottery, enter into binding contracts, sue or be sued, or take on a number of other responsibilities. Therefore, there is a pressing interest to know whether the person at the U.S. Army Recruiting Center, a tattoo parlor, or the lottery window is entitled to use the service.
Second, to estimate whether a person is over or under the age of 13 years. Although age 13 is not as great a milestone as age 18, this is usually the age at which social media companies allow people to open accounts. Thus the social media companies and other companies that cater to teens have a pressing interest to know the teen’s age.
Why was I against age estimation?
Because I felt it was better to know an age, rather than estimate it.
My opinion was obviously influenced by my professional background. When IDEMIA was formed in 2017, I became part of a company that produced government-issued driver’s licenses for the majority of states in the United States. (OK, MorphoTrak was previously contracted to produce driver’s licenses for North Carolina, but…that didn’t last.)
With a driver’s license, you know the age of the person and don’t have to estimate anything.
And estimation is not an exact science. Here’s what Yoti’s March 2023 white paper says about age estimation accuracy:
Our True Positive Rate (TPR) for 13-17 year olds being correctly estimated as under 25 is 99.93% and there is no discernible bias across gender or skin tone. The TPRs for female and male 13-17 year olds are 99.90% and 99.94% respectively. The TPRs for skin tone 1, 2 and 3 are 99.93%, 99.89% and 99.92% respectively. This gives regulators globally a very high level of confidence that children will not be able to access adult content.
Our TPR for 6-11 year olds being correctly estimated as under 13 is 98.35%. The TPRs for female and male 6-11 year olds are 98.00% and 98.71% respectively. The TPRs for skin tone 1, 2 and 3 are 97.88%, 99.24% and 98.18% respectively so there is no material bias in this age group either.
Yoti’s facial age estimation is performed by a ‘neural network’, trained to be able to estimate human age by analysing a person’s face. Our technology is accurate for 6 to 12 year olds, with a mean absolute error (MAE) of 1.3 years, and of 1.4 years for 13 to 17 year olds. These are the two age ranges regulators focus upon to ensure that under 13s and 18s do not have access to age restricted goods and services.
While this is admirable, is it precise enough to comply with government regulations? Mean absolute errors of over a year don’t mean a hill of beans. By the letter of the law, if you are 17 years and 364 days old and you try to vote, you are breaking the law.
Why did I change my mind?
Over the last couple of months I’ve thought about this a bit more and have experienced a Jim Bakker “I was wrong” moment.
How many 13 year olds do you know that have driver’s licenses? Probably none.
How many 13 year olds do you know that have government-issued REAL IDs? Probably very few.
How many 13 year olds do you know that have passports? Maybe a few more (especially after 9/11), but not that many.
Even at age 18, there is no guarantee that a person will have a government-issued REAL ID.
So how are 18 year olds, or 13 year olds, supposed to prove that they are old enough for services? Carry their birth certificate around?
You’ll note that Yoti didn’t target a use case for 21 year olds. This is partially because Yoti is a UK firm and therefore may not focus on the strict U.S. laws regarding alcohol, tobacco, and casino gambling. But it’s also because it’s much, much more likely that a 21 year old will have a government-issued ID, eliminating the need for age estimation.
Sometimes.
In some parts of the world, no one has government IDs
Over the past several years, I’ve analyzed a variety of identity firms. Earlier this year I took a look at Worldcoin. While Worldcoin’s World ID emphasizes privacy so much that it does not conclusively prove a person’s identity (it only proves a person’s uniqueness), and makes no attempt to provide the age of the person with the World ID, Worldcoin does have something to say about government issued IDs.
Online services often request proof of ID (usually a passport or driver’s license) to comply with Know your Customer (KYC) regulations. In theory, this could be used to deduplicate individuals globally, but it fails in practice for several reasons.
KYC services are simply not inclusive on a global scale; more than 50% of the global population does not have an ID that can be verified digitally.
IDs are issued by states and national governments, with no global system for verification or accountability. Many verification services (i.e. KYC providers) rely on data from credit bureaus that is accumulated over time, hence stale, without the means to verify its authenticity with the issuing authority (i.e. governments), as there are often no APIs available. Fake IDs, as well as real data to create them, are easily available on the black market. Additionally, due to their centralized nature, corruption at the level of the issuing and verification organizations cannot be eliminated.
Same source as above.
Now this (in my opinion) doesn’t make the case for Worldcoin, but it certainly casts some doubt on a universal way to document ages.
So we’d better start measuring the accuracy of age estimation.
If only there were an independent organization that could measure age estimation, in the same way that NIST measures the accuracy of fingerprint, face, and iris identification.
You know where this is going.
How will NIST test age estimation?
Yes, NIST is in the process of incorporating an age estimation test in its battery of Face Recognition Vendor Tests.
Facial age verification has recently been mandated in legislation in a number of jurisdictions. These laws are typically intended to protect minors from various harms by verifying that the individual is above a certain age. Less commonly some applications extend benefits to groups below a certain age. Further use-cases seek only to determine actual age. The mechanism for estimating age is usually not specified in legislation. Face analysis using software is one approach, and is attractive when a photograph is available or can be captured.
In 2014, NIST published a NISTIR 7995 on Performance of Automated Age Estimation. The report showed using a database with 6 million images, the most accurate age estimation algorithm have accurately estimated 67% of the age of a person in the images within five years of their actual age, with a mean absolute error (MAE) of 4.3 years. Since then, more research has dedicated to further improve the accuracy in facial age verification.
Note that this was in 2014. As we have seen above, Yoti asserts a dramatically lower error rate in 2023.
NIST is just ramping up the testing right now, but once it moves forward, it will be possible to compare age estimation accuracy of various algorithms, presumably in multiple scenarios.
Well, for those algorithm providers who choose to participate.
Does your firm need to promote its age estimation solution?
Does your company have an age estimation solution that is superior to all others?
Do you need an experienced identity professional to help you spread the word about your solution?
When you have tens of thousands of people dying, then the only conscionable response is to ban automobiles altogether. Any other action or inaction is completely irresponsible.
After all, you can ask the experts who want us to ban biometrics because it can be spoofed and is racist, so therefore we shouldn’t use biometrics at all.
I disagree with the calls to ban biometrics, and I’ll go through three “biometrics are bad” examples and say why banning biometrics is NOT justified.
Even some identity professionals may not know about the old “gummy fingers” story from 20+ years ago.
And yes, I know that I’ve talked about Gender Shades ad nauseum, but it bears repeating again.
And voice deepfakes are always a good topic to discuss in our AI-obsessed world.
But the iris security was breached by a “dummy eye” just a month later, in the same way that gummy fingers and face masks have defeated other biometric technologies.
Back in 2002, this news WAS really “scary,” since it suggested that you could access a fingerprint reader-protected site with something that wasn’t a finger. Gelatin. A piece of metal. A photograph.
TECH5 participated in the 2023 LivDet Non-contact Fingerprint competition to evaluate its latest NN-based fingerprint liveness detection algorithm and has achieved first and second ranks in the “Systems” category for both single- and four-fingerprint liveness detection algorithms respectively. Both submissions achieved the lowest error rates on bonafide (live) fingerprints. TECH5 achieved 100% accuracy in detecting complex spoof types such as Ecoflex, Playdoh, wood glue, and latex with its groundbreaking Neural Network model that is only 1.5MB in size, setting a new industry benchmark for both accuracy and efficiency.
TECH5 excelled in detecting fake fingers for “non-contact” reading where the fingers don’t even touch a surface such as an optical surface. That’s appreciably harder than detecting fake fingers that touch contact devices.
I should note that LivDet is an independent assessment. As I’ve said before, independent technology assessments provide some guidance on the accuracy and performance of technologies.
So gummy fingers and future threats can be addressed as they arrive.
Let’s stop right there for a moment and address two items before we continue. Trust me; it’s important.
This study evaluated only three algorithms: one from IBM, one from Microsoft, and one from Face++. It did not evaluate the hundreds of other facial recognition algorithms that existed in 2018 when the study was released.
The study focused on gender classification and race classification. Back in those primitive innocent days of 2018, the world assumed that you could look at a person and tell whether the person was male or female, or tell the race of a person. (The phrase “self-identity” had not yet become popular, despite the Rachel Dolezal episode which happened before the Gender Shades study). Most importantly, the study did not address identification of individuals at all.
However, the findings did find something:
While the companies appear to have relatively high accuracy overall, there are notable differences in the error rates between different groups. Let’s explore.
All companies perform better on males than females with an 8.1% – 20.6% difference in error rates.
All companies perform better on lighter subjects as a whole than on darker subjects as a whole with an 11.8% – 19.2% difference in error rates.
When we analyze the results by intersectional subgroups – darker males, darker females, lighter males, lighter females – we see that all companies perform worst on darker females.
What does this mean? It means that if you are using one of these three algorithms solely for the purpose of determining a person’s gender and race, some results are more accurate than others.
And all the stories about people such as Robert Williams being wrongfully arrested based upon faulty facial recognition results have nothing to do with Gender Shades. I’ll address this briefly (for once):
In the United States, facial recognition identification results should only be used by the police as an investigative lead, and no one should be arrested solely on the basis of facial recognition. (The city of Detroit stated that Williams’ arrest resulted from “sloppy” detective work.)
If you are using facial recognition for criminal investigations, your people had better have forensic face training. (Then they would know, as Detroit investigators apparently didn’t know, that the quality of surveillance footage is important.)
If you’re going to ban computerized facial recognition (even when only used as an investigative lead, and even when only used by properly trained individuals), consider the alternative of human witness identification. Or witness misidentification. Roeling Adams, Reggie Cole, Jason Kindle, Adam Riojas, Timothy Atkins, Uriah Courtney, Jason Rivera, Vondell Lewis, Guy Miles, Luis Vargas, and Rafael Madrigal can tell you how inaccurate (and racist) human facial recognition can be. See my LinkedIn article “Don’t ban facial recognition.”
Obviously, facial recognition has been the subject of independent assessments, including continuous bias testing by the National Institute of Standards and Technology as part of its Face Recognition Vendor Test (FRVT), specifically within the 1:1 verification testing. And NIST has measured the identification bias of hundreds of algorithms, not just three.
Richard Nixon never spoke those words in public, although it’s possible that he may have rehearsed William Safire’s speech, composed in case Apollo 11 had not resulted in one giant leap for mankind. As noted in the video, Nixon’s voice and appearance were spoofed using artificial intelligence to create a “deepfake.”
In early 2020, a branch manager of a Japanese company in Hong Kong received a call from a man whose voice he recognized—the director of his parent business. The director had good news: the company was about to make an acquisition, so he needed to authorize some transfers to the tune of $35 million. A lawyer named Martin Zelner had been hired to coordinate the procedures and the branch manager could see in his inbox emails from the director and Zelner, confirming what money needed to move where. The manager, believing everything appeared legitimate, began making the transfers.
What he didn’t know was that he’d been duped as part of an elaborate swindle, one in which fraudsters had used “deep voice” technology to clone the director’s speech…
Now I’ll grant that this is an example of human voice verification, which can be as inaccurate as the previously referenced human witness misidentification. But are computerized systems any better, and can they detect spoofed voices?
IDVoice Verified combines ID R&D’s core voice verification biometric engine, IDVoice, with our passive voice liveness detection, IDLive Voice, to create a high-performance solution for strong authentication, fraud prevention, and anti-spoofing verification.
Anti-spoofing verification technology is a critical component in voice biometric authentication for fraud prevention services. Before determining a match, IDVoice Verified ensures that the voice presented is not a recording.
This is only the beginning of the war against voice spoofing. Other companies will pioneer new advances that will tell the real voices from the fake ones.
As for independent testing:
ID R&D has participated in multiple ASVspoof tests, and performed well in them.
Back in 2021, it seemed that I was commenting on the EU Digital COVID Certificate (EUDCC) ad nauseum. The EUDCC is the “vaccine passport” that was developed to allow people in member EU countries to prove their COVID vaccination status in another EU country.
August 2021 was the last time that I wrote about the EUDCC in the Bredemarket blog. Until now.
Enter…WHO?
You know how standards are adopted by brute force from big players? Well, one big player has forced itself into the discussion. That player is the World Health Organization, commonly known as WHO.
Stella Kyriakides, the European commissioner for health and food safety (announced) that the voluntary certificate program has already been taken up by almost 80 countries.
Last I checked there were not 80 countries in the EU. So this health standards thing took off after the initial hiccups. Although the Wikipedia list of non-EU adopting countries does not include two big players—the United States and China (the same two countries I cited in my August 2021 post).
WHO’s Global Digital Health Certification Network is an open-source platform, built on robust & transparent standards that establishes the first building block of digital public health infrastructure for developing a wide range of digital products for strengthening pandemic preparedness and to deliver better health for all….
The GDHCN is builds (sic) upon the experience of regional networks for COVID-19 Certificates and takes up the infrastructure and experiences with the digital European Union Digital COVID Certificate (EU DCC) system, which has seen adoption across all Member States of the EU as well as 51 non-EU countries and territories. The GDHCN has been designed to be interoperable with other existing regional networks (e.g., ICAO VSD-NC, DIVOC, LACPass, SMART Health Cards) specifications.
On the surface it sounds great, but we’ll see what happens when it goes live (Borak states that the go-live date is July 1).
And we’ll see how it expands:
To facilitate the uptake of the EU DCC by WHO and contribute to its operation and further development, WHO and the European Commission have agreed to partner in digital health.
This partnership will work to technically develop the WHO system with a staged approach to cover additional use cases, which may include, for example, the digitisation of the International Certificate of Vaccination or Prophylaxis. Expanding such digital solutions will be essential to deliver better health for citizens across the globe.
Are you an executive with a small or medium sized identity/biometrics firm?
If so, you want to share the story of your identity firm. But what are you going to say?
How will you figure out what makes your firm better than all the inferior identity firms that compete with you?
How will you get the word out about why your identity firm beats all the others?
Are you getting tired of my repeated questions?
Are you ready for the answers?
Your identity firm differs from all others
Over the last 29 years, I (John E. Bredehoft of Bredemarket) have worked for and with over a dozen identity firms, either as an employee or as a consultant.
You’d think that since I have worked for so many different identity firms, it’s an easy thing to start working with a new firm by simply slapping down the messaging that I’ve created for all the other identity firms.
The messaging that I created in my various roles at IDEMIA and its corporate predecessors was dramatically different than the messaging I created as a Senior Product Marketing Manager at Incode Technologies, which was also very different from the messaging that I created for my previous Bredemarket clients.
IDEMIA benefits such as “servicing your needs anywhere in the world” and “applying our decades of identity experience to solve your problems” are not going to help with a U.S.-only firm that’s only a decade old.
Similarly, messaging for a company that develops its own facial recognition algorithms will necessarily differ from messaging for a company that chooses the best third-party facial recognition algorithms on the market.
So which messaging is right?
It depends on who is paying me.
How your differences affect your firm’s messaging
When creating messaging for your identity firm, one size does not fit all, for the reasons listed above.
The content of your messaging will differ, based upon your differentiators.
For example, if you were the U.S.-only firm established less than ten years ago, your messaging would emphasize the newness of your solution and approach, as opposed to the stodgy legacy companies that never updated their ideas.
And if your firm has certain types of end users, such as law enforcement users, your messaging would probably feature an abundance of U.S. flags.
In addition, the channels that you use for your messaging will differ.
Identity firms will not want to market on every single social media channel. They will only market on the channels where their most motivated buyers are present.
That may be your own website.
Or LinkedIn.
Or Facebook.
Or Twitter.
Or Instagram.
Or YouTube.
Or TikTok.
Or a private system only accessible to people with a Top Secret Clearance.
It may be more than one of these channels, but it probably won’t be all of them.
But before you work on your content or channels, you need to know what to say, and how to communicate it.
How to know and communicate your differentiators
As we’ve noted, your firm is different than all others.
How do you know the differences?
How do you know what you want to talk about?
How do you know what you DON’T want to talk about?
Here are three methods to get you started on knowing and communicating your differentiators in your content.
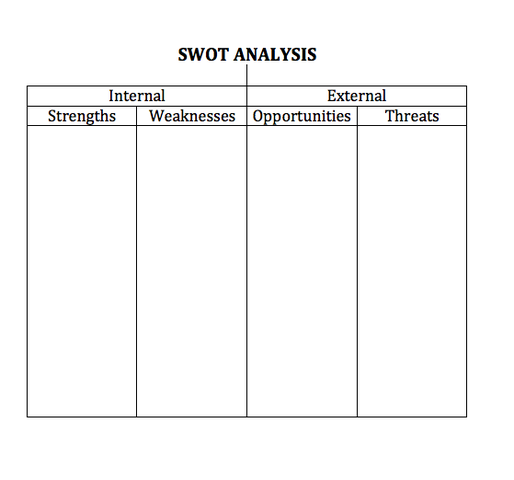
Method One: The time-tested SWOT analysis
If you talk to a marketer for more than two seconds about positioning a company, the marketer will probably throw the acronym “SWOT” back at you. I’ve mentioned the SWOT acronym before.
For those who don’t know the acronym, SWOT stands for
Strengths. These are internal attributes that benefit your firm. For example, your firm is winning a lot of business and growing in customer count and market share.
Weaknesses. These are also internal attributes, but in this case the attributes that detract from your firm. For example, you have very few customers.
Opportunities. These are external factors that enhance your firm. One example is a COVID or similar event that creates a surge in demand for contactless solutions.
Threats. The flip side is external factors that can harm your firm. One example is increasing privacy regulations that can slow or halt adoption of your product or service.
If you’re interested in more detail on the topic, there are a number of online sources that discuss SWOT analyses. Here’s TechTarget’s discussion of SWOT.
The common way to create the output from a SWOT analysis is to create four boxes and list each element (S, W, O, and T) within a box.
Once this is done, you’ll know that your messaging should emphasize the strengths and opportunities, and downplay or avoid the weaknesses and threats.
Or alternatively argue that the weaknesses and threats are really strengths and opportunities. (I’ve done this before.)
Method Two: Think before you create
Personally, I believe that a SWOT analysis is not enough. Before you use the SWOT findings to create content, there’s a little more work you have to do.
I recommend that before you create content, you should hold a kickoff of the content creation process and figure out what you want to do before you do it.
During that kickoff meeting, you should ask some questions to make sure you understand what needs to be done.
I’ve written about kickoffs and questions before, and I’m not going to repeat what I already said. If you want to know more:
Now that you’ve locked down the messaging, it’s time to actually create the content that differentiates your identity firm from all the inferior identity firms in the market. While some companies can proceed right to content creation, others may run into one of two problems.
The identity firm doesn’t have any knowledgeable writers on staff. To create the content, you need people who understand the identity industry, and who know how to write. Some firms lack people with this knowledge and capability.
The identity firm has knowledgeable writers on staff, but they’re busy. Some companies have too many things to do at once, and any knowledgeable writers that are on staff may be unavailable due to other priorities.
This is where you supplement you identity firm’s existing staff with one or more knowledgeable writers who can work with you to create the content that leaves your inferior competitors in the dust.
What is next?
So do you need a knowledgeable biometric content marketing expert to create your content?
One who has been in the biometric industry for 29 years?
One who has been writing short and long form content for more than 29 years?
Are you getting tired of my repeated questions again?
Well then I’ll just tell you that Bredemarket is the answer to your identity/biometric content marketing needs.
Are you ready to take your identity firm to the next level with a compelling message that increases awareness, consideration, conversion, and long-term revenue? Let’s talk today!
My compulsion to share stuff about identity and biometrics, which you can see if you visit my Bredemarket Identity Firm Services LinkedIn page and Facebook group.
Unfortunately for us, 90% of the song deals with the negative aspects of a person obsessing over another person. If you pick through the lyrics of the Animotion song “Obsession” and forget about what (or who) the singer is obsessing about, you can find isolated phrases that describe how an obsession can motivate you.
“I cannot sleep”
“Be still”
“I will not accept defeat”
But thankfully, there are more positive ways to embrace an obsession.
Justin Welsh on embracing an obsession
While Justin Welsh’s July 2022 post “TSS #028: Don’t Pick a Niche. Embrace an Obsession” is targeted for solopreneurs, it could just as easily apply to those who work for others. Regardless of your compensation structure, why do you choose to work where you do?
For Welsh, the practice of picking a niche risks commoditization.
They end up looking like, sounding like, and acting like all of their competition. The internet is full of copycats and duplicates.
(For example, I’d bet that all of the people who are picking a niche know better than to cite the Animotion song “Obsession” in a blog post promoting their business.)
Perhaps it’s semantics, but in Welsh’s way of thinking, embracing an obsession differs from picking a niche. To describe the power of embracing an obsession, Welsh references a tweet from Daniel Vassalo:
Find something you want to do really badly, and you won’t need any goals, habits, systems, discipline, rewards, or any other mental hacks. When the motivation is intrinsic, those things happen on their own.
Find something you want to do really badly, and you won’t need any goals, habits, systems, discipline, rewards, or any other mental hacks. When the motivation is intrinsic, those things happen on their own.
I trust you can see the difference between picking something you HAVE to do, versus obsessing over something you WANT to do.
What’s in it for you?
Welsh was addressing this post to me and people like me, and his message resonates with me.
But frankly, YOU don’t care about me and about whether I’m motivated. All that you care about is that YOU get YOUR content that you need from me.
So why should you care what Justin Welsh and Daniel Vassllo told me?
The obvious answer is that if you contract with Bredemarket for your marketing and writing services, you’ll get a “pry my keyboard out of my cold dead hands” person who WANTS to write your stuff, and doesn’t want to turn the writing process over to some two-year-old bot (except for very small little bits).
I’m still working on my TikTok generative AI dance. (Don’t hold your breath.)
“Pry my keyboard,” indeed.
Do you need someone to obsess over YOUR content?
Of course, if you need someone to write YOUR stuff, then I won’t have time to work on a TikTok dance. This is a good thing for me, you, and the world.
As I’ve stated elsewhere, before I write a thing for a Bredemarket client, I make sure that I understand WHY you do what you do, and understand everything else that is relevant to the content that we create.
As I work on the content, you have opportunities to review it and provide your feedback. This ensures that both of us are happy with the final copy.
And that your end users become obsessed with YOU.
So if you need me to create content for you, please contact me.
Does your identity business provide biometric or non-biometric products and services that use finger, face, iris, DNA, voice, government documents, geolocation, or other factors or modalities?
Does your identity business need written content, such as blog posts (from the identity/biometric blog expert), case studies, data sheets, proposal text, social media posts, or white papers?
How can your identity business (with the help of an identity content marketing expert) create the right written content?
I’ve spent the first two entries in this post series (Part One, Part Two) talking about my compulsion to share identity information to Slack or LinkedIn or other places.
And you’re probably asking a very important question.
So what?
Talking about my compulsion isn’t really a good customer-focused thing to do.
Unless my compulsion benefits you in some say.
And for some of you, it does.
If you are a professional in the identity industry, you want to remain up-to-date on all the goings-on. And there are a number of sources that provide that information. But in many cases, you have to read the entire article.
That’s where my long-established practice of quoting excerpts can help.
Through force of habit, most of my shares to the Bredemarket Identity Firm Services LinkedIn showcase page begin with a relevant excerpt, and sometimes I include an editorial comment based on my 25-plus years in the identity industry. If the excerpt (and/or editorial) interests you, you can click on the link and read the article. If the excerpt/editorial doesn’t interest you, you can skip the article entirely.