Checking the purported identity against private databases, such as credit records.
Checking the person’s driver’s license or other government document to ensure it’s real and not a fake.
Checking the purported identity against government databases, such as driver’s license databases. (What if the person presents a real driver’s license, but that license was subsequently revoked?)
Perform a “who you are” biometric test against the purported identity.
If you conduct all four tests, then you have used multiple factors of authentication to confirm that the person is who they say they are. If the identity is synthetic, chances are the purported person will fail at least one of these tests.
Do you fight synthetic identity fraud?
If you fight synthetic identity fraud, you should let people know about your solution.
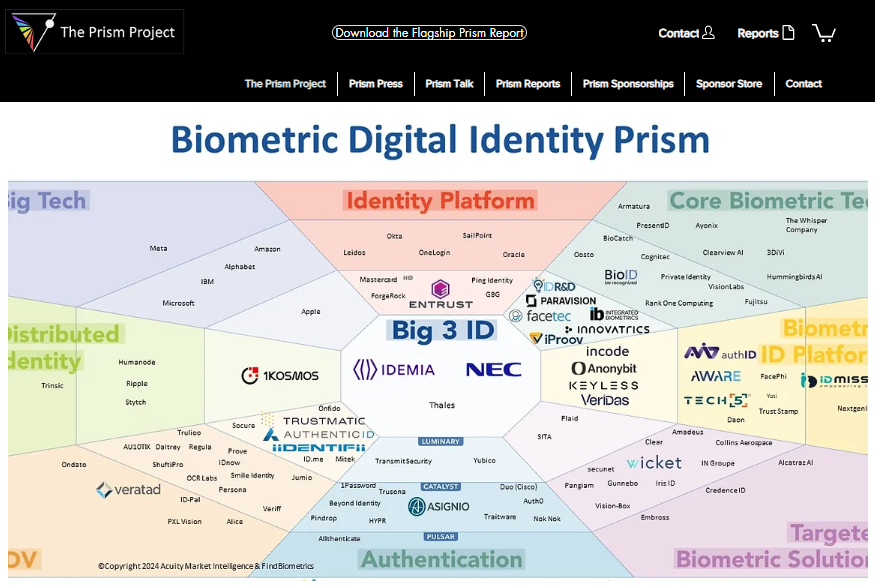
The Prism Project’s home page at https://www.the-prism-project.com/, illustrating the Biometric Digital Identity Prism as of March 2024. From Acuity Market Intelligence and FindBiometrics.
With over 100 firms in the biometric industry, their offerings are going to naturally differ—even if all the firms are TRYING to copy each other and offer “me too” solutions.
I’ve worked for over a dozen biometric firms as an employee or independent contractor, and I’ve analyzed over 80 biometric firms in competitive intelligence exercises, so I’m well aware of the vast implementation differences between the biometric offerings.
Some of the implementation differences provoke vehement disagreements between biometric firms regarding which choice is correct. Yes, we FIGHT.
Let’s look at three (out of many) of these implementation differences and see how they affect YOUR company’s content marketing efforts—whether you’re engaging in identity blog post writing, or some other content marketing activity.
The three biometric implementation choices
Firms that develop biometric solutions make (or should make) the following choices when implementing their solutions.
Presentation attack detection. Assuming the solution incorporates presentation attack detection (liveness detection), or a way of detecting whether the presented biometric is real or a spoof, the firm must decide whether to use active or passive liveness detection.
Age assurance. When choosing age assurance solutions that determine whether a person is old enough to access a product or service, the firm must decide whether or not age estimation is acceptable.
Biometric modality. Finally, the firm must choose which biometric modalities to support. While there are a number of modality wars involving all the biometric modalities, this post is going to limit itself to the question of whether or not voice biometrics are acceptable.
I will address each of these questions in turn, highlighting the pros and cons of each implementation choice. After that, we’ll see how this affects your firm’s content marketing.
(I)nstead of capturing a true biometric from a person, the biometric sensor is fooled into capturing a fake biometric: an artificial finger, a face with a mask on it, or a face on a video screen (rather than a face of a live person).
This tomfoolery is called a “presentation attack” (becuase you’re attacking security with a fake presentation).
And an organization called iBeta is one of the testing facilities authorized to test in accordance with the standard and to determine whether a biometric reader can detect the “liveness” of a biometric sample.
(Friends, I’m not going to get into passive liveness and active liveness. That’s best saved for another day.)
Now I could cite a firm using active liveness detection to say why it’s great, or I could cite a firm using passive liveness detection to say why it’s great. But perhaps the most balanced assessment comes from facia, which offers both types of liveness detection. How does facia define the two types of liveness detection?
Active liveness detection, as the name suggests, requires some sort of activity from the user. If a system is unable to detect liveness, it will ask the user to perform some specific actions such as nodding, blinking or any other facial movement. This allows the system to detect natural movements and separate it from a system trying to mimic a human being….
Passive liveness detection operates discreetly in the background, requiring no explicit action from the user. The system’s artificial intelligence continuously analyses facial movements, depth, texture, and other biometric indicators to detect an individual’s liveness.
Pros and cons
Briefly, the pros and cons of the two methods are as follows:
While active liveness detection offers robust protection, requires clear consent, and acts as a deterrent, it is hard to use, complex, and slow.
Passive liveness detection offers an enhanced user experience via ease of use and speed and is easier to integrate with other solutions, but it incorporates privacy concerns (passive liveness detection can be implemented without the user’s knowledge) and may not be used in high-risk situations.
So in truth the choice is up to each firm. I’ve worked with firms that used both liveness detection methods, and while I’ve spent most of my time with passive implementations, the active ones can work also.
A perfect wishy-washy statement that will get BOTH sides angry at me. (Except perhaps for companies like facia that use both.)
If you need to know a person’s age, you can ask them. Because people never lie.
Well, maybe they do. There are two better age assurance methods:
Age verification, where you obtain a person’s government-issued identity document with a confirmed birthdate, confirm that the identity document truly belongs to the person, and then simply check the date of birth on the identity document and determine whether the person is old enough to access the product or service.
Age estimation, where you don’t use a government-issued identity document and instead examine the face and estimate the person’s age.
I changed my mind on age estimation
I’ve gone back and forth on this. As I previously mentioned, my employment history includes time with a firm produces driver’s licenses for the majority of U.S. states. And back when that firm was providing my paycheck, I was financially incentivized to champion age verification based upon the driver’s licenses that my company (or occasionally some inferior company) produced.
But as age assurance applications moved into other areas such as social media use, a problem occurred since 13 year olds usually don’t have government IDs. A few of them may have passports or other government IDs, but none of them have driver’s licenses.
But does age estimation work? I’m not sure if ANYONE has posted a non-biased view, so I’ll try to do so myself.
The pros of age estimation include its applicability to all ages including young people, its protection of privacy since it requires no information about the individual identity, and its ease of use since you don’t have to dig for your physical driver’s license or your mobile driver’s license—your face is already there.
The huge con of age estimation is that it is by definition an estimate. If I show a bartender my driver’s license before buying a beer, they will know whether I am 20 years and 364 days old and ineligible to purchase alcohol, or whether I am 21 years and 0 days old and eligible. Estimates aren’t that precise.
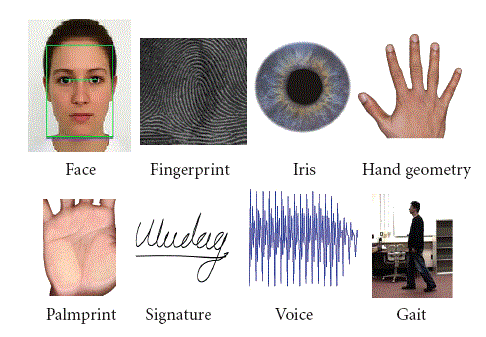
Fingerprints, palm prints, faces, irises, and everything up to gait. (And behavioral biometrics.) There are a lot of biometric modalities out there, and one that has been around for years is the voice biometric.
I’ve discussed this topic before, and the partial title of the post (“We’ll Survive Voice Spoofing”) gives away how I feel about the matter, but I’ll present both sides of the issue.
No one can deny that voice spoofing exists and is effective, but many of the examples cited by the popular press are cases in which a HUMAN (rather than an ALGORITHM) was fooled by a deepfake voice. But voice recognition software can also be fooled.
Take a study from the University of Waterloo, summarized here, that proclaims: “Computer scientists at the University of Waterloo have discovered a method of attack that can successfully bypass voice authentication security systems with up to a 99% success rate after only six tries.”
If you re-read that sentence, you will notice that it includes the words “up to.” Those words are significant if you actually read the article.
In a recent test against Amazon Connect’s voice authentication system, they achieved a 10 per cent success rate in one four-second attack, with this rate rising to over 40 per cent in less than thirty seconds. With some of the less sophisticated voice authentication systems they targeted, they achieved a 99 per cent success rate after six attempts.
Other voice spoofing studies
Similar to Gender Shades, the University of Waterloo study does not appear to have tested hundreds of voice recognition algorithms. But there are other studies.
The 2021 NIST Speaker Recognition Evaluation (PDF here) tested results from 15 teams, but this test was not specific to spoofing.
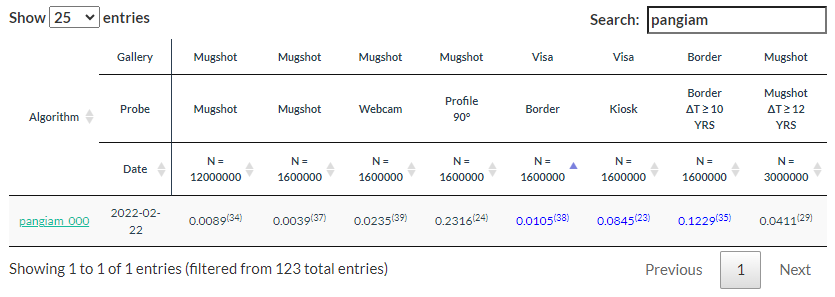
A test that was specific to spoofing was the ASVspoof 2021 test with 54 team participants, but the ASVspoof 2021 results are only accessible in abstract form, with no detailed results.
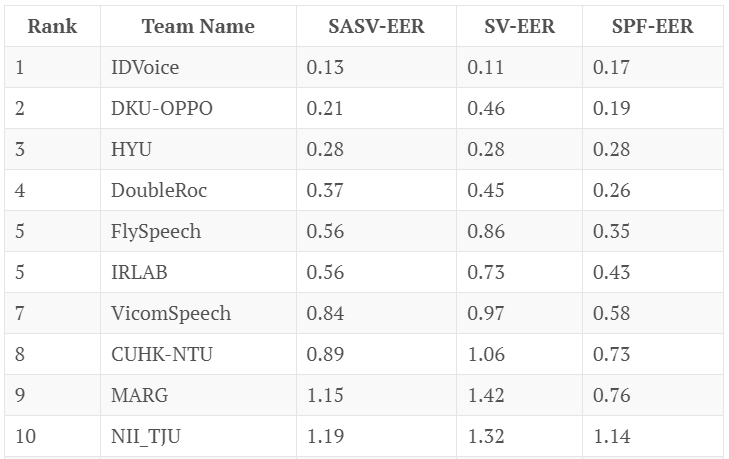
Another test, this one with results, is the SASV2022 challenge, with 23 valid submissions. Here are the top 10 performers and their error rates.
You’ll note that the top performers don’t have error rates anywhere near the University of Waterloo’s 99 percent.
So some firms will argue that voice recognition can be spoofed and thus cannot be trusted, while other firms will argue that the best voice recognition algorithms are rarely fooled.
What does this mean for your company?
Obviously, different firms are going to respond to the three questions above in different ways.
For example, a firm that offers face biometrics but not voice biometrics will convey how voice is not a secure modality due to the ease of spoofing. “Do you want to lose tens of millions of dollars?”
A firm that offers voice biometrics but not face biometrics will emphasize its spoof detection capabilities (and cast shade on face spoofing). “We tested our algorithm against that voice fake that was in the news, and we detected the voice as a deepfake!”
There is no universal truth here, and the message your firm conveys depends upon your firm’s unique characteristics.
And those characteristics can change.
Once when I was working for a client, this firm had made a particular choice with one of these three questions. Therefore, when I was writing for the client, I wrote in a way that argued the client’s position.
After I stopped working for this particular client, the client’s position changed and the firm adopted the opposite view of the question.
Therefore I had to message the client and say, “Hey, remember that piece I wrote for you that said this? Well, you’d better edit it, now that you’ve changed your mind on the question…”
Bear this in mind as you create your blog, white paper, case study, or other identity/biometric content, or have someone like the biometric content marketing expert Bredemarket work with you to create your content. There are people who sincerely hold the opposite belief of your firm…but your firm needs to argue that those people are, um, misinformed.
As further proof that I am celebrating, rather than hiding, my “seasoned” experience—and you know what the code word “seasoned” means—I am entitling this blog post “Take Me to the Pilot.”
Although I’m thinking about a different type of “pilot”—a pilot to establish that Login.gov can satisfy Identity Assurance Level 2 (IAL2).
The link in that sentence directs the kind reader to a post I wrote in November 2023, detailing that fact that the GSA Inspector General criticized…the GSA…for implying that Login.gov was IAL2-compliant when it was not. The November post references a GSA-authored August blog post which reads in part (in bold):
Login.gov is on a path to providing an IAL2-compliant identity verification service to its customers in a responsible, equitable way.
Specifically, over the next few months, Login.gov will:
Pilot facial matching technology consistent with the National Institute of Standards and Technology’s Digital Identity Guidelines (800-63-3) to achieve evidence-based remote identity verification at the IAL2 level….
Using proven facial matching technology, Login.gov’s pilot will allow users to match a live selfie with the photo on a self-supplied form of photo ID, such as a driver’s license. Login.gov will not allow these images to be used for any purpose other than verifying identity, an approach which reflects Login.gov’s longstanding commitment to ensuring the privacy of its users. This pilot is slated to start in May with a handful of existing agency-partners who have expressed interest, with the pilot expanding to additional partners over the summer. GSA will simultaneously seek an independent third party assessment (Kantara) of IAL2 compliance, which GSA expects will be completed later this year.
In short, GSA’s April 11 press release about the Login.gov pilot says that it expects to complete IAL2 compliance later this year. So it’s going to take more than a year for the GSA to repair the gap that its Inspector General identified.
My seasoned response
Once I saw Steve’s update this morning, I felt it sufficiently important to share the news among Bredemarket’s various social channels.
With a picture.
B-side of Elton John “Your Song” single issued 1970.
For those of you who are not as “seasoned” as I am, the picture depicts the B-side of a 1970 vinyl 7″ single (not a compact disc) from Elton John, taken from the album that broke Elton in the United States. (Not literally; that would come a few years later.)
By the way, while the original orchestrated studio version is great, the November 1970 live version with just the Elton John – Dee Murray – Nigel Olsson trio is OUTSTANDING.
Back to Bredemarket social media. If you go to my Instagram post on this topic, I was able to incorporate an audio snippet from “Take Me to the Pilot” (studio version) into the post. (You may have to go to the Instagram post to actually hear the audio.)
Not that the song has anything to do with identity verification using government ID documents paired with facial recognition. Or maybe it does; Elton John doesn’t know what the song means, and even lyricist Bernie Taupin doesn’t know what the song means.
So from now on I’m going to say that “Take Me to the Pilot” documents future efforts toward IAL2 compliance. Although frankly the lyrics sound like they describe a successful iris spoofing attempt.
Through a glass eye, your throne Is the one danger zone
We get all sorts of great tools, but do we know how to use them? And what are the consequences if we don’t know how to use them? Could we lose the use of those tools entirely due to bad publicity from misuse?
According to a report released in September by the US Government Accountability Office, only 5 percent of the 196 FBI agents who have access to facial recognition technology from outside vendors have completed any training on how to properly use the tools.
It turns out that the study is NOT limited to FBI use of facial recognition services, but also addresses six other federal agencies: the Bureau of Alcohol, Tobacco, Firearms and Explosives (the guvmint doesn’t believe in the Oxford comma); U.S. Customs and Border Protection; the Drug Enforcement Administration; Homeland Security Investigations; the U.S. Marshals Service; and the U.S. Secret Service.
Initially, none of the seven agencies required users to complete facial recognition training. As of April 2023, two of the agencies (Homeland Security Investigations and the U.S. Marshals Service) required training, two (the FBI and Customs and Border Protection) did not, and the other three had quit using these four facial recognition services.
The FBI stated that facial recognition training was recommended as a “best practice,” but not mandatory. And when something isn’t mandatory, you can guess what happened:
GAO found that few of these staff completed the training, and across the FBI, only 10 staff completed facial recognition training of 196 staff that accessed the service. FBI said they intend to implement a training requirement for all staff, but have not yet done so.
Although not a requirement, FBI officials said they recommend (as a best practice) that some staff complete FBI’s Face Comparison and Identification Training when using Clearview AI. The recommended training course, which is 24 hours in length, provides staff with information on how to interpret the output of facial recognition services, how to analyze different facial features (such as ears, eyes, and mouths), and how changes to facial features (such as aging) could affect results.
However, this type of training was not recommended for all FBI users of Clearview AI, and was not recommended for any FBI users of Marinus Analytics or Thorn.
I should note that the report was issued in September 2023, based upon data gathered earlier in the year, and that for all I know the FBI now mandates such training.
Or maybe it doesn’t.
What about your state and local facial recognition users?
Of course, training for federal facial recognition users is only a small part of the story, since most of the law enforcement activity takes place at the state and local level. State and local users need training so that they can understand:
The anatomy of the face, and how it affects comparisons between two facial images.
How cameras work, and how this affects comparisons between two facial images.
How poor quality images can adversely affect facial recognition.
How facial recognition should ONLY be used as an investigative lead.
If facial recognition users had been trained, none of the false arrests over the last few years would have taken place.
The users would have realized that the poor images were not of sufficient quality to determine a match.
The users would have realized that even if they had been of sufficient quality, facial recognition must only be used as an investigative lead, and once other data had been checked, the cases would have fallen apart.
But the false arrests gave the privacy advocates the ammunition they needed.
Not to insist upon proper training in the use of facial recognition.
Like nuclear or biological weapons, facial recognition’s threat to human society and civil liberties far outweighs any potential benefits. Silicon Valley lobbyists are disingenuously calling for regulation of facial recognition so they can continue to profit by rapidly spreading this surveillance dragnet. They’re trying to avoid the real debate: whether technology this dangerous should even exist. Industry-friendly and government-friendly oversight will not fix the dangers inherent in law enforcement’s discriminatory use of facial recognition: we need an all-out ban.
(And just wait until the anti-facial recognition forces discover that this is not only a plot of evil Silicon Valley, but also a plot of evil non-American foreign interests located in places like Paris and Tokyo.)
Because the anti-facial recognition forces want us to remove the use of technology and go back to the good old days…of eyewitness misidentification.
Eyewitnesses are often expected to identify perpetrators of crimes based on memory, which is incredibly malleable. Under intense pressure, through suggestive police practices, or over time, an eyewitness is more likely to find it difficult to correctly recall details about what they saw.
This post concentrates on IDENTIFICATION perfection, or the ability to enjoy zero errors when identifying individuals.
The risk of claiming identification perfection (or any perfection) is that a SINGLE counter-example disproves the claim.
If you assert that your biometric solution offers 100% accuracy, a SINGLE false positive or false negative shatters the assertion.
If you claim that your presentation attack detection solution exposes deepfakes (face, voice, or other), then a SINGLE deepfake that gets past your solution disproves your claim.
And as for the pre-2009 claim that latent fingerprint examiners never make a mistake in an identification…well, ask Brandon Mayfield about that one.
In fact, I go so far as to avoid using the phrase “no two fingerprints are alike.” Many years ago (before 2009) in an International Association for Identification meeting, I heard someone justify the claim by saying, “We haven’t found a counter-example yet.” That doesn’t mean that we’ll NEVER find one.
At first glance, it appears that Motorola would be the last place to make a boneheaded mistake like that. After all, Motorola is known for its focus on quality.
But in actuality, Motorola was the perfect place to make such a mistake, since it was one of the champions of the “Six Sigma” philosophy (which targets a maximum of 3.4 defects per million opportunities). Motorola realized that manufacturing perfection is impossible, so manufacturers (and the people in Motorola’s weird Biometric Business Unit) should instead concentrate on reducing the error rate as much as possible.
So one misspelling could be tolerated, but I shudder to think what would have happened if I had misspelled “quality” a second time.
Back in August 2023, the U.S. General Services Administration published a blog post that included the following statement:
Login.gov is on a path to providing an IAL2-compliant identity verification service to its customers in a responsible, equitable way. Building on the strong evidence-based identity verification that Login.gov already offers, Login.gov is on a path to providing IAL2-compliant identity verification that ensures both strong security and broad and equitable access.
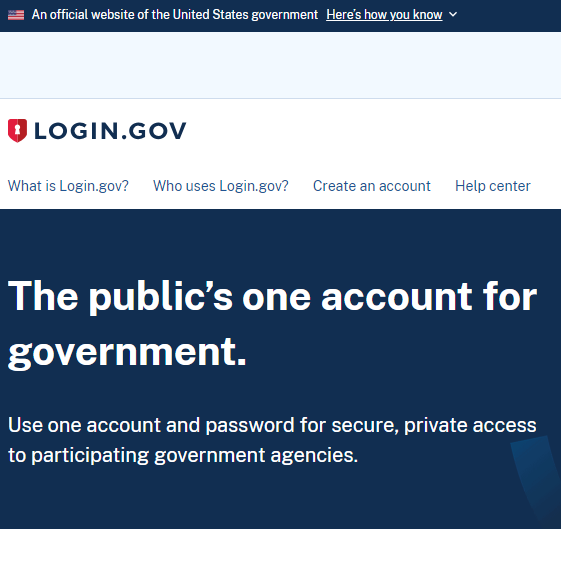
Login.gov is a secure sign in service used by the public to sign in to participating government agencies. Participating agencies will ask you to create a Login.gov account to securely access your information on their website or application.
You can use the same username and password to access any agency that partners with Login.gov. This streamlines your process and eliminates the need to remember multiple usernames and passwords.
Why would agencies implement Login.gov? Because the agencies want to protect their constituents’ information. If fraudsters capture personally identifiable information (PII) of someone applying for government services, the breached government agency will face severe repurcussions. Login.gov is supposed to protect its partner agencies from these nightmares.
How does Login.gov do this?
Sometimes you might use two-factor authentication consisting of a password and a second factor such as an SMS code or the use of an authentication app.
In more critical cases, Login.gov requests a more reliable method of identification, such as a government-issued photo ID (driver’s license, passport, etc.).
The U.S. National Institute of Standards and Technology, in its publication NIST SP 800-63a, has defined “identity assurance levels” (IALs) that can be used when dealing with digital identities. It’s helpful to review how NIST has defined the IALs. (I’ll define the other acronyms as we go along.)
Assurance in a subscriber’s identity is described using one of three IALs:
IAL1: There is no requirement to link the applicant to a specific real-life identity. Any attributes provided in conjunction with the subject’s activities are self-asserted or should be treated as self-asserted (including attributes a [Credential Service Provider] CSP asserts to an [Relying Party] RP). Self-asserted attributes are neither validated nor verified.
IAL2: Evidence supports the real-world existence of the claimed identity and verifies that the applicant is appropriately associated with this real-world identity. IAL2 introduces the need for either remote or physically-present identity proofing. Attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL2 can support IAL1 transactions if the user consents.
IAL3: Physical presence is required for identity proofing. Identifying attributes must be verified by an authorized and trained CSP representative. As with IAL2, attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL3 can support IAL1 and IAL2 identity attributes if the user consents.
So in its simplest terms, IAL2 requires evidence of a verified credential so that an online person can be linked to a real-life identity. If someone says they’re “John Bredehoft” and fills in an online application to receive government services, IAL2 compliance helps to ensure that the person filling out the online application truly IS John Bredehoft, and not Bernie Madoff.
As more and more of us conduct business—including government business—online, IAL2 compliance is essential to reduce fraud.
One more thing about IAL2 compliance. The mere possession of a valid government issued photo ID is NOT sufficient for IAL2 compliance. After all, Bernie Madoff may be using John Bredehoft’s driver’s license. To make sure that it’s John Bredehoft using John Bredehoft’s driver’s license, an additional check is needed.
This has been explained by ID.me, a private company that happens to compete with Login.gov to provide identity proofing services to government agencies.
Biometric comparison (e.g., selfie with liveness detection or fingerprint) of the strongest piece of evidence to the applicant
So you basically take the information on a driver’s license and perform a facial recognition 1:1 comparison with the person possessing the driver’s license, ideally using liveness detection, to make sure that the presented person is not a fake.
As part of an investigation that has run since last April (2022), GSA’s Office of the Inspector General found that the agency was billing agencies for IAL2-compliant services, even though Login.gov did not meet Identity Assurance Level 2 (IAL2) standards.
GSA knowingly billed over $10 million for services provided through contracts with other federal agencies, even though Login.gov is not IAL2 compliant, according to the watchdog.
My decision making process relies on extensive data analysis and aligning with the company’s strategic objectives. It’s devoid of personal bias ensuring unbiased and strategic choices that prioritize the organization’s best interests.
Mika was brought to my attention by accomplished product marketer/artist Danuta (Dana) Deborgoska. (She’s appeared in the Bredemarket blog before, though not by name.) Dana is also Polish (but not Colombian) and clearly takes pride in the artificial intelligence accomplishments of this Polish-headquartered company. You can read her LinkedIn post to see her thoughts, one of which was as follows:
Data is the new oxygen, and we all know that we need clean data to innovate and sustain business models.
There’s a reference to oxygen again, but it’s certainly appropriate. Just as people cannot survive without oxygen, Generative AI cannot survive without data.
But the need for data predates AI models. From 2017:
Reliance Industries Chairman Mukesh Ambani said India is poised to grow…but to make that happen the country’s telecoms and IT industry would need to play a foundational role and create the necessary digital infrastructure.
Calling data the “oxygen” of the digital economy, Ambani said the telecom industry had the urgent task of empowering 1.3 billion Indians with the tools needed to flourish in the digital marketplace.
Of course, the presence or absence of data alone is not enough. As Debogorska notes, we don’t just need any data; we need CLEAN data, without error and without bias. Dirty data is like carbon monoxide, and as you know carbon monoxide is harmful…well, most of the time.
That’s been the challenge not only with artificial intelligence, but with ALL aspects of data gathering.
The all-male board of directors of a fertilizer company in 1960. Fair use. From the New York Times.
In all of these cases, someone (Amazon, Enron’s shareholders, or NIST) asked questions about the cleanliness of the data, and then set out to answer those questions.
In the case of Amazon’s recruitment tool and the company Enron, the answers caused Amazon to abandon the tool and Enron to abandon its existence.
Despite the entreaties of so-called privacy advocates (who prefer the privacy nightmare of physical driver’s licenses to the privacy-preserving features of mobile driver’s licenses), we have not abandoned facial recognition, but we’re definitely monitoring it in a statistical (not an anecdotal) sense.
The cleanliness of the data will continue to be the challenge as we apply artificial intelligence to new applications.
Things change. Pangiam, a company that didn’t even exist a few years ago, and that started off by acquiring a one-off project from a local government agency, is now itself a friendly acquisition target (pending stockholder and regulatory approvals).
From MWAA to Pangiam
Back when I worked for IDEMIA and helped to market its border control solutions, one of our competitors for airport business was an airport itself—specifically, the Metropolitan Washington Airports Authority. Rather than buying a biometric exit solution from someone else, the MWAA developed its own, called veriScan.
2021 image from the former airportveriscan website.
ALEXANDRIA, Va., March 19, 2021 /PRNewswire/ — Pangiam, a technology-based security and travel services provider, announced today that it has acquired veriScan, an integrated biometric facial recognition system for airports and airlines, from the Metropolitan Washington Airports Authority (“Airports Authority”). Terms of the transaction were not disclosed.
So what will Pangiam work on next? Where will it expand? What will it acquire?
Nothing.
Enter BigBear.ai
Pangiam itself is now an acquisition target.
COLUMBIA, MD.— November 6, 2023 — BigBear.ai (NYSE: BBAI), a leading provider of AI-enabled business intelligence solutions, today announced a definitive merger agreement to acquire Pangiam Intermediate Holdings, LLC (Pangiam), a leader in Vision AI for the global trade, travel, and digital identity industries, for approximately $70 million in an all-stock transaction. The combined company will create one of the industry’s most comprehensive Vision AI portfolios, combining Pangiam’s facial recognition and advanced biometrics with BigBear.ai’s computer vision capabilities, positioning the company as a foundational leader in one of the fastest growing categories for the application of AI. The proposed acquisition is expected to close in the first quarter of 2024, subject to customary closing conditions, including approval by the holders of a majority of BigBear.ai’s outstanding common shares and receipt of regulatory approval.
Yet another example of how biometrics is now just a minor part of general artificial intelligence efforts. Identify a face or a grenade, it’s all the same.
Anyway, let’s check back in a few months. Because of the technology involved, this proposed acquisition will DEFINITELY merit government review.
As identity/biometric professionals well know, there are five authentication factors that you can use to gain access to a person’s account. (You can also use these factors for identity verification to establish the person’s account in the first place.)
Something You Are. I’ve spent…a long time with this factor, since this is the factor that includes biometrics modalities (finger, face, iris, DNA, voice, vein, etc.). It also includes behavioral biometrics, provided that they are truly behavioral and relatively static.
As I mentioned in August, there are a number of biometric modalities, including face, fingerprint, iris, hand geometry, palm print, signature, voice, gait, and many more.
If your firm offers an identity solution that partially depends upon “something you are,” then you need to create content (blog, case study, social media, white paper, etc.) that converts prospects for your identity/biometric product/service and drives content results.
For example, when biometric companies want to justify the use of their technology, they have found that it is very effective to position biometrics as a way to combat sex trafficking.
Similarly, moves to rein in social media are positioned as a way to preserve mental health.
Now that’s a not-so-pretty picture, but it effectively speaks to emotions.
“If poor vulnerable children are exposed to addictive, uncontrolled social media, YOUR child may end up in a straitjacket!”
In New York state, four government officials have declared that the ONLY way to preserve the mental health of underage social media users is via two bills, one of which is the “New York Child Data Protection Act.”
But there is a challenge to enforce ALL of the bill’s provisions…and only one way to solve it. An imperfect way—age estimation.
Because they want to protect the poor vulnerable children.
By Paolo Monti – Available in the BEIC digital library and uploaded in partnership with BEIC Foundation.The image comes from the Fondo Paolo Monti, owned by BEIC and located in the Civico Archivio Fotografico of Milan., CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=48057924
And because the major U.S. social media companies are headquartered in California. But I digress.
So why do they say that children need protection?
Recent research has shown devastating mental health effects associated with children and young adults’ social media use, including increased rates of depression, anxiety, suicidal ideation, and self-harm. The advent of dangerous, viral ‘challenges’ being promoted through social media has further endangered children and young adults.
Of course one can also argue that social media is harmful to adults, but the New Yorkers aren’t going to go that far.
So they are just going to protect the poor vulnerable children.
CC BY-SA 4.0.
This post isn’t going to deeply analyze one of the two bills the quartet have championed, but I will briefly mention that bill now.
The “Stop Addictive Feeds Exploitation (SAFE) for Kids Act” (S7694/A8148) defines “addictive feeds” as those that are arranged by a social media platform’s algorithm to maximize the platform’s use.
Those of us who are flat-out elderly vaguely recall that this replaced the former “chronological feed” in which the most recent content appeared first, and you had to scroll down to see that really cool post from two days ago. New York wants the chronological feed to be the default for social media users under 18.
The bill also proposes to limit under 18 access to social media without parental consent, especially between midnight and 6:00 am.
And those who love Illinois BIPA will be pleased to know that the bill allows parents (and their lawyers) to sue for damages.
Previous efforts to control underage use of social media have faced legal scrutinity, but since Attorney General James has sworn to uphold the U.S. Constitution, presumably she has thought about all this.
Enough about SAFE for Kids. Let’s look at the other bill.
The New York Child Data Protection Act
The second bill, and the one that concerns me, is the “New York Child Data Protection Act” (S7695/A8149). Here is how the quartet describes how this bill will protect the poor vulnerable children.
CC BY-SA 4.0.
With few privacy protections in place for minors online, children are vulnerable to having their location and other personal data tracked and shared with third parties. To protect children’s privacy, the New York Child Data Protection Act will prohibit all online sites from collecting, using, sharing, or selling personal data of anyone under the age of 18 for the purposes of advertising, unless they receive informed consent or unless doing so is strictly necessary for the purpose of the website. For users under 13, this informed consent must come from a parent.
And again, this bill provides a BIPA-like mechanism for parents or guardians (and their lawyers) to sue for damages.
But let’s dig into the details. With apologies to the New York State Assembly, I’m going to dig into the Senate version of the bill (S7695). Bear in mind that this bill could be amended after I post this, and some of the portions that I cite could change.
This only applies to natural persons. So the bots are safe, regardless of age.
Speaking of age, the age of 18 isn’t the only age referenced in the bill. Here’s a part of the “privacy protection by default” section:
§ 899-FF. PRIVACY PROTECTION BY DEFAULT.
1. EXCEPT AS PROVIDED FOR IN SUBDIVISION SIX OF THIS SECTION AND SECTION EIGHT HUNDRED NINETY-NINE-JJ OF THIS ARTICLE, AN OPERATOR SHALL NOT PROCESS, OR ALLOW A THIRD PARTY TO PROCESS, THE PERSONAL DATA OF A COVERED USER COLLECTED THROUGH THE USE OF A WEBSITE, ONLINE SERVICE, ONLINE APPLICATION, MOBILE APPLICA- TION, OR CONNECTED DEVICE UNLESS AND TO THE EXTENT:
(A) THE COVERED USER IS TWELVE YEARS OF AGE OR YOUNGER AND PROCESSING IS PERMITTED UNDER 15 U.S.C. § 6502 AND ITS IMPLEMENTING REGULATIONS; OR
(B) THE COVERED USER IS THIRTEEN YEARS OF AGE OR OLDER AND PROCESSING IS STRICTLY NECESSARY FOR AN ACTIVITY SET FORTH IN SUBDIVISION TWO OF THIS SECTION, OR INFORMED CONSENT HAS BEEN OBTAINED AS SET FORTH IN SUBDIVISION THREE OF THIS SECTION.
So a lot of this bill depends upon whether a person is over or under the age of eighteen, or over or under the age of thirteen.
And that’s a problem.
How old are you?
The bill needs to know whether or not a person is 18 years old. And I don’t think the quartet will be satisfied with the way that alcohol websites determine whether someone is 21 years old.
Attorney General James and the others would presumably prefer that the social media companies verify ages with a government-issued ID such as a state driver’s license, a state identification card, or a national passport. This is how most entities verify ages when they have to satisfy legal requirements.
For some people, even some minors, this is not that much of a problem. Anyone who wants to drive in New York State must have a driver’s license, and you have to be at least 16 years old to get a driver’s license. Admittedly some people in the city never bother to get a driver’s license, but at some point these people will probably get a state ID card.
However, there are going to be some 17 year olds who don’t have a driver’s license, government ID or passport.
And some 16 year olds.
And once you look at younger people—15 year olds, 14 year olds, 13 year olds, 12 year olds—the chances of them having a government-issued identification document are much less.
What are these people supposed to do? Provide a birth certificate? And how will the social media companies know if the birth certificate is legitimate?
But there’s another way to determine ages—age estimation.
How old are you, part 2
As long-time readers of the Bredemarket blog know, I have struggled with the issue of age verification, especially for people who do not have driver’s licenses or other government identification. Age estimation in the absence of a government ID is still an inexact science, as even Yoti has stated.
Our technology is accurate for 6 to 12 year olds, with a mean absolute error (MAE) of 1.3 years, and of 1.4 years for 13 to 17 year olds. These are the two age ranges regulators focus upon to ensure that under 13s and 18s do not have access to age restricted goods and services.
So if a minor does not have a government ID, and the social media firm has to use age estimation to determine a minor’s age for purposes of the New York Child Data Protection Act, the following two scenarios are possible:
An 11 year old may be incorrectly allowed to give informed consent for purposes of the Act.
A 14 year old may be incorrectly denied the ability to give informed consent for purposes of the Act.
Is age estimation “good enough for government work”?