

The COVID-19 pandemic may be a fading memory, but contactless biometrics remains popular.
Back in the 1980s, you had to touch something to get the then-new “livescan” machines to capture your fingerprints. While you no longer had messy ink-stained fingers, you still had to put your fingers on a surface that a bunch of other people had touched. What if they had the flu? Or AIDS (the health scare of that decade)?
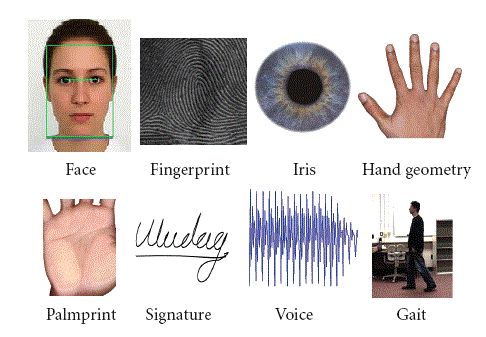
As we began to see facial recognition in the 1990s and early 2000s, one advantage of that biometric modality was that it was CONTACTLESS. Unlike fingerprints, you didn’t have to press your face against a surface.

But then fingerprints also became contactless after someone asked an unusual question in 2004.
“Actually this effort launched before that, as there were efforts in 2004 and following years to capture a complete set of fingerprints within 15 seconds…”
This WAS an unusual question, considering that it took a minute or more to capture inked prints or livescan prints. And the government expected this to happen in 15 seconds?
A decade later several companies were pursuing this in conjunction with NIST. There were two solutions: dedicated kiosks such as MorphoWave from my then-employer MorphoTrak, and solutions that used a standard smartphone camera such as SlapShot from Sciometrics and Integrated Biometrics.

The, um, upshot is that now contactless fingerprint and face capture are both a thing. Contactless capture provides speed, and even the impossible 15 second capture target was blown away.
Fingers and faces can be captured “on the move” in airports, border crossings, stadiums, and university lunchrooms and other educational facilities.
Perhaps Iris and voice can be considered contactless and fast.
But even “rapid” DNA isn’t that rapid.












{kind=link}