I’ve worked with rapid DNA since I was in Proposals at MorphoTrak, when our corporate parent Safran had an agreement with IntegenX (now part of Thermo Fisher Scientific). Rapid DNA, when suitable for use, can process a DNA sample in 90 minutes or less, providing a quick way to process DNA in both criminal and non-criminal cases.
But as I explain below, sometimes rapid DNA isn’t so rapid. In those cases, investigators have to turn to boring biometric technologies such as fingerprints instead. Fingerprints are a much older identification modality, but they still work.
Bredemarket recently purchased access to a Journal of Forensic Sciences article entitled “Advances in postmortem fingerprinting: Applications in disaster victim identification” (https://doi.org/10.1111/1556-4029.15513) by Bryan T. Johnson MSFS of the Federal Bureau of Investigation Laboratory in Quantico. The abstract (which is NOT behind the paywall) states the following, in part:
In disaster victim identification (DVI), fingerprints, DNA, and dental examinations are the three primary methods of identification….As DNA technology continues to evolve, RAPID DNA may now identify a profile within 90 min if the remains are not degraded or comingled. When there are true unknowns, however, there is usually no DNA, dental, or medical records to retrieve for a comparison without a tentative identity.
In the body of the paper itself (which IS behind the paywall), Johnson cites one example in which use of rapid DNA would have DELAYED the process.
DVI depends upon comparison of a DNA sample from a victim with a previous DNA sample taken from the victim. If this is not available, then the victim’s DNA is compared against the DNA of a family member.
Identifying foreign nationals aboard the MV Conception
When the MV Conception boat caught fire and sank in September 2019, 34 people lost their lives and had to be positively identified.
While most of the MV Conception victims were California residents, some victims were from Singapore and India. It would take weeks to collect and transport the DNA samples from the victims’ family members back to the United States for comparison against the DNA samples from the victims. Weeks of uncertainty during which family members had no confirmation that their relatives were among the deceased.
However, because the foreign victims were visitors to the United States, they had fingerprints on file with the Department of Homeland Security. Interagency agreements allowed the investigating agencies to access the DHS fingerprints and compare them against the fingerprints of the foreign victims, providing tentative identifications within three days. (Fingerprint identification is a 100+ year old method, but it works!) These tentative identifications were subsequently confirmed when the familial DNA samples arrived.
What does this mean?
The message here is NOT that “fingerprints rule, DNA drools.” In some cases the investigators could not retrieve fingerprints from the bodies and HAD to use rapid DNA.
The message here is that when identifying people, you should use ANY biometric (or non-biometric) modality that is available: fingerprints, DNA, dental records, driver’s licenses, Radio Shack Battery Club card, or anything else that provides an investigative lead or a positive identification.
AAL1 (some confidence). AAL1, in the words of NIST, “provides some assurance.” Single-factor authentication is OK, but multi-factor authentication can be used also. All sorts of authentication methods, including knowledge-based authentication, satisfy the requirements of AAL1. In short, AAL1 isn’t exactly a “nothingburger” as I characterized IAL1, but AAL1 doesn’t provide a ton of assurance.
AAL2 (high confidence). AAL2 increases the assurance by requiring “two distinct authentication factors,” not just one. There are specific requirements regarding the authentication factors you can use. And the security must conform to the “moderate” security level, such as the moderate security level in FedRAMP. So AAL2 is satisfactory for a lot of organizations…but not all of them.
AAL3 (very high confidence). AAL3 is the highest authenticator assurance level. It “is based on proof of possession of a key through a cryptographic protocol.” Of course, two distinct authentication factors are required, including “a hardware-based authenticator and an authenticator that provides verifier impersonation resistance — the same device MAY fulfill both these requirements.”
This is of course a very high overview, and there are a lot of…um…minutiae that go into each of these definitions. If you’re interested in that further detail, please read section 4 of NIST Special Publication 800-63B for yourself.
Which authenticator assurance level should you use?
NIST has provided a handy dandy AAL decision flowchart in section 6.2 of NIST Special Publication 800-63-3, similar to the IAL decision flowchart in section 6.1 that I reproduced earlier. If you go through the flowchart, you can decide whether you need AAL1, AAL2, or the very high AAL3.
One of the key questions is the question flagged as 2, “Are you making personal data accessible?” The answer to this question in the flowchart moves you between AAL2 (if personal data is made accessible) and AAL1 (if it isn’t).
So what?
Do the different authenticator assurance levels provide any true benefits, or are they just items in a government agency’s technical check-off list?
Perhaps the better question to ask is this: what happens if the WRONG person obtains access to the data?
Could the fraudster cause financial loss to a government agency?
Threaten personal safety?
Commit civil or criminal violations?
Or, most frightening to agency heads who could be fired at any time, could the fraudster damage an agency’s reputation?
If some or all of these are true, then a high authenticator assurance level is VERY beneficial.
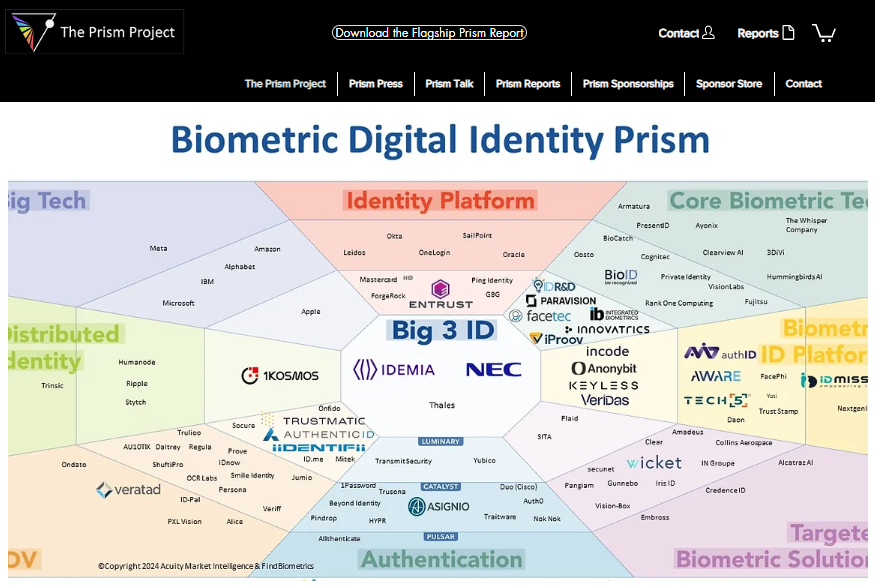
The Prism Project’s home page at https://www.the-prism-project.com/, illustrating the Biometric Digital Identity Prism as of March 2024. From Acuity Market Intelligence and FindBiometrics.
With over 100 firms in the biometric industry, their offerings are going to naturally differ—even if all the firms are TRYING to copy each other and offer “me too” solutions.
I’ve worked for over a dozen biometric firms as an employee or independent contractor, and I’ve analyzed over 80 biometric firms in competitive intelligence exercises, so I’m well aware of the vast implementation differences between the biometric offerings.
Some of the implementation differences provoke vehement disagreements between biometric firms regarding which choice is correct. Yes, we FIGHT.
Let’s look at three (out of many) of these implementation differences and see how they affect YOUR company’s content marketing efforts—whether you’re engaging in identity blog post writing, or some other content marketing activity.
The three biometric implementation choices
Firms that develop biometric solutions make (or should make) the following choices when implementing their solutions.
Presentation attack detection. Assuming the solution incorporates presentation attack detection (liveness detection), or a way of detecting whether the presented biometric is real or a spoof, the firm must decide whether to use active or passive liveness detection.
Age assurance. When choosing age assurance solutions that determine whether a person is old enough to access a product or service, the firm must decide whether or not age estimation is acceptable.
Biometric modality. Finally, the firm must choose which biometric modalities to support. While there are a number of modality wars involving all the biometric modalities, this post is going to limit itself to the question of whether or not voice biometrics are acceptable.
I will address each of these questions in turn, highlighting the pros and cons of each implementation choice. After that, we’ll see how this affects your firm’s content marketing.
(I)nstead of capturing a true biometric from a person, the biometric sensor is fooled into capturing a fake biometric: an artificial finger, a face with a mask on it, or a face on a video screen (rather than a face of a live person).
This tomfoolery is called a “presentation attack” (becuase you’re attacking security with a fake presentation).
And an organization called iBeta is one of the testing facilities authorized to test in accordance with the standard and to determine whether a biometric reader can detect the “liveness” of a biometric sample.
(Friends, I’m not going to get into passive liveness and active liveness. That’s best saved for another day.)
Now I could cite a firm using active liveness detection to say why it’s great, or I could cite a firm using passive liveness detection to say why it’s great. But perhaps the most balanced assessment comes from facia, which offers both types of liveness detection. How does facia define the two types of liveness detection?
Active liveness detection, as the name suggests, requires some sort of activity from the user. If a system is unable to detect liveness, it will ask the user to perform some specific actions such as nodding, blinking or any other facial movement. This allows the system to detect natural movements and separate it from a system trying to mimic a human being….
Passive liveness detection operates discreetly in the background, requiring no explicit action from the user. The system’s artificial intelligence continuously analyses facial movements, depth, texture, and other biometric indicators to detect an individual’s liveness.
Pros and cons
Briefly, the pros and cons of the two methods are as follows:
While active liveness detection offers robust protection, requires clear consent, and acts as a deterrent, it is hard to use, complex, and slow.
Passive liveness detection offers an enhanced user experience via ease of use and speed and is easier to integrate with other solutions, but it incorporates privacy concerns (passive liveness detection can be implemented without the user’s knowledge) and may not be used in high-risk situations.
So in truth the choice is up to each firm. I’ve worked with firms that used both liveness detection methods, and while I’ve spent most of my time with passive implementations, the active ones can work also.
A perfect wishy-washy statement that will get BOTH sides angry at me. (Except perhaps for companies like facia that use both.)
If you need to know a person’s age, you can ask them. Because people never lie.
Well, maybe they do. There are two better age assurance methods:
Age verification, where you obtain a person’s government-issued identity document with a confirmed birthdate, confirm that the identity document truly belongs to the person, and then simply check the date of birth on the identity document and determine whether the person is old enough to access the product or service.
Age estimation, where you don’t use a government-issued identity document and instead examine the face and estimate the person’s age.
I changed my mind on age estimation
I’ve gone back and forth on this. As I previously mentioned, my employment history includes time with a firm produces driver’s licenses for the majority of U.S. states. And back when that firm was providing my paycheck, I was financially incentivized to champion age verification based upon the driver’s licenses that my company (or occasionally some inferior company) produced.
But as age assurance applications moved into other areas such as social media use, a problem occurred since 13 year olds usually don’t have government IDs. A few of them may have passports or other government IDs, but none of them have driver’s licenses.
But does age estimation work? I’m not sure if ANYONE has posted a non-biased view, so I’ll try to do so myself.
The pros of age estimation include its applicability to all ages including young people, its protection of privacy since it requires no information about the individual identity, and its ease of use since you don’t have to dig for your physical driver’s license or your mobile driver’s license—your face is already there.
The huge con of age estimation is that it is by definition an estimate. If I show a bartender my driver’s license before buying a beer, they will know whether I am 20 years and 364 days old and ineligible to purchase alcohol, or whether I am 21 years and 0 days old and eligible. Estimates aren’t that precise.
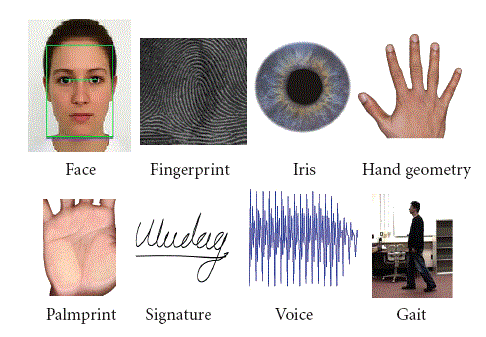
Fingerprints, palm prints, faces, irises, and everything up to gait. (And behavioral biometrics.) There are a lot of biometric modalities out there, and one that has been around for years is the voice biometric.
I’ve discussed this topic before, and the partial title of the post (“We’ll Survive Voice Spoofing”) gives away how I feel about the matter, but I’ll present both sides of the issue.
No one can deny that voice spoofing exists and is effective, but many of the examples cited by the popular press are cases in which a HUMAN (rather than an ALGORITHM) was fooled by a deepfake voice. But voice recognition software can also be fooled.
Take a study from the University of Waterloo, summarized here, that proclaims: “Computer scientists at the University of Waterloo have discovered a method of attack that can successfully bypass voice authentication security systems with up to a 99% success rate after only six tries.”
If you re-read that sentence, you will notice that it includes the words “up to.” Those words are significant if you actually read the article.
In a recent test against Amazon Connect’s voice authentication system, they achieved a 10 per cent success rate in one four-second attack, with this rate rising to over 40 per cent in less than thirty seconds. With some of the less sophisticated voice authentication systems they targeted, they achieved a 99 per cent success rate after six attempts.
Other voice spoofing studies
Similar to Gender Shades, the University of Waterloo study does not appear to have tested hundreds of voice recognition algorithms. But there are other studies.
The 2021 NIST Speaker Recognition Evaluation (PDF here) tested results from 15 teams, but this test was not specific to spoofing.
A test that was specific to spoofing was the ASVspoof 2021 test with 54 team participants, but the ASVspoof 2021 results are only accessible in abstract form, with no detailed results.
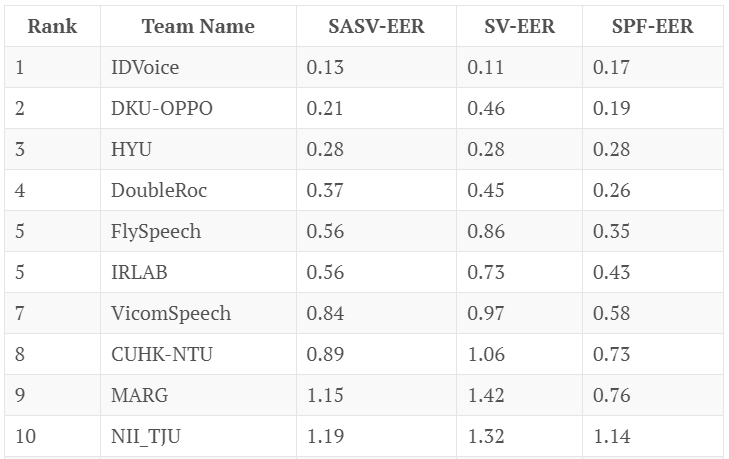
Another test, this one with results, is the SASV2022 challenge, with 23 valid submissions. Here are the top 10 performers and their error rates.
You’ll note that the top performers don’t have error rates anywhere near the University of Waterloo’s 99 percent.
So some firms will argue that voice recognition can be spoofed and thus cannot be trusted, while other firms will argue that the best voice recognition algorithms are rarely fooled.
What does this mean for your company?
Obviously, different firms are going to respond to the three questions above in different ways.
For example, a firm that offers face biometrics but not voice biometrics will convey how voice is not a secure modality due to the ease of spoofing. “Do you want to lose tens of millions of dollars?”
A firm that offers voice biometrics but not face biometrics will emphasize its spoof detection capabilities (and cast shade on face spoofing). “We tested our algorithm against that voice fake that was in the news, and we detected the voice as a deepfake!”
There is no universal truth here, and the message your firm conveys depends upon your firm’s unique characteristics.
And those characteristics can change.
Once when I was working for a client, this firm had made a particular choice with one of these three questions. Therefore, when I was writing for the client, I wrote in a way that argued the client’s position.
After I stopped working for this particular client, the client’s position changed and the firm adopted the opposite view of the question.
Therefore I had to message the client and say, “Hey, remember that piece I wrote for you that said this? Well, you’d better edit it, now that you’ve changed your mind on the question…”
Bear this in mind as you create your blog, white paper, case study, or other identity/biometric content, or have someone like the biometric content marketing expert Bredemarket work with you to create your content. There are people who sincerely hold the opposite belief of your firm…but your firm needs to argue that those people are, um, misinformed.
For example, during my most recent stint as a product marketing employee at a startup, the firm had no official content marketers, so the product marketers had to create a lot of non-product related content. So we product marketers were the de facto content marketers for the company too. (Sadly, we didn’t get two salaries for filling two roles.)
Why did the product marketers end up as content marketers? It turns out that it makes sense—after all, people who write about your product in the lower funnel stages can also write about your product in the upper funnel stages, and also can certainly write about OTHER things, such as company descriptions, speaker submissions, and speaker biographies.
Identity/biometrics firms don’t just create social media channels for the firms themselves. Sometimes they create social media channels dedicated to specific products and services.
That’s the good news.
Here’s the bad news.
[REDACTED]
As I write this, it’s March 3. A firm hasn’t updated one of its product-oriented social media channels since February 20.
That’s February 20, 2020…back when most of us were still working in offices.
It’s not like the product no longer exists…but to the casual viewer it seems like it. As I noted in a previous post, a 2020 survey showed that 76% of B2B buyers make buying decisions primarily based on the winning vendor’s online content.
Before you can fully understand the difference between personally identifiable information (PII) and protected health information (PHI), you need to understand the difference between biometrics and…biometrics. (You know sometimes words have two meanings.)
Designed by Google Gemini.
The definitions of biometrics
To address the difference between biometrics and biometrics, I’ll refer to something I wrote over two years ago, in late 2021. In that post, I quoted two paragraphs from the International Biometric Society that illustrated the difference.
Since the IBS has altered these paragraphs in the intervening years, I will quote from the latest version.
The terms “Biometrics” and “Biometry” have been used since early in the 20th century to refer to the field of development of statistical and mathematical methods applicable to data analysis problems in the biological sciences.
Statistical methods for the analysis of data from agricultural field experiments to compare the yields of different varieties of wheat, for the analysis of data from human clinical trials evaluating the relative effectiveness of competing therapies for disease, or for the analysis of data from environmental studies on the effects of air or water pollution on the appearance of human disease in a region or country are all examples of problems that would fall under the umbrella of “Biometrics” as the term has been historically used….
The term “Biometrics” has also been used to refer to the field of technology devoted to the identification of individuals using biological traits, such as those based on retinal or iris scanning, fingerprints, or face recognition. Neither the journal “Biometrics” nor the International Biometric Society is engaged in research, marketing, or reporting related to this technology. Likewise, the editors and staff of the journal are not knowledgeable in this area.
In brief, what I call “broad biometrics” refers to analyzing biological sciences data, ranging from crop yields to heart rates. Contrast this with what I call “narrow biometrics,” which (usually) refers only to human beings, and only to those characteristics that identify human beings, such as the ridges on a fingerprint.
The definition of “personally identifiable information” (PII)
Information that can be used to distinguish or trace an individual’s identity, either alone or when combined with other information that is linked or linkable to a specific individual.
Note the key words “alone or when combined.” The ten numbers “909 867 5309” are not sufficient to identify an individual alone, but can identify someone when combined with information from another source, such as a telephone book.
What types of information can be combined to identify a person? The U.S. Department of Defense’s Privacy, Civil Liberties, and Freedom of Information Directorate provides multifarious examples of PII, including:
Social Security Number.
Passport number.
Driver’s license number.
Taxpayer identification number.
Patient identification number.
Financial account number.
Credit card number.
Personal address.
Personal telephone number.
Photographic image of a face.
X-rays.
Fingerprints.
Retina scan.
Voice signature.
Facial geometry.
Date of birth.
Place of birth.
Race.
Religion.
Geographical indicators.
Employment information.
Medical information.
Education information.
Financial information.
Now you may ask yourself, “How can I identify someone by a non-unique birthdate? A lot of people were born on the same day!”
But the combination of information is powerful, as researchers discovered in a 2015 study cited by the New York Times.
In the study, titled “Unique in the Shopping Mall: On the Reidentifiability of Credit Card Metadata,” a group of data scientists analyzed credit card transactions made by 1.1 million people in 10,000 stores over a three-month period. The data set contained details including the date of each transaction, amount charged and name of the store.
Although the information had been “anonymized” by removing personal details like names and account numbers, the uniqueness of people’s behavior made it easy to single them out.
In fact, knowing just four random pieces of information was enough to reidentify 90 percent of the shoppers as unique individuals and to uncover their records, researchers calculated. And that uniqueness of behavior — or “unicity,” as the researchers termed it — combined with publicly available information, like Instagram or Twitter posts, could make it possible to reidentify people’s records by name.
Now biometrics only form part of the multifarious list of data cited above, but clearly biometric data can be combined with other data to identify someone. An easy example is taking security camera footage of the face of a person walking into a store, and combining that data with the same face taken from a database of driver’s license holders. In some jurisdictions, some entities are legally permitted to combine this data, while others are legally prohibited from doing so. (A few do it anyway. But I digress.)
Because narrow biometric data used for identification, such as fingerprint ridges, can be combined with other data to personally identify an individual, organizations that process biometric data must undertake strict safeguards to protect that data. If personally identifiable information (PII) is not adequately guarded, people could be subject to fraud and other harms.
The definition of “protected health information” (PHI)
Protected Health Information. The Privacy Rule protects all “individually identifiable health information” held or transmitted by a covered entity or its business associate, in any form or media, whether electronic, paper, or oral. The Privacy Rule calls this information “protected health information (PHI).”12
“Individually identifiable health information” is information, including demographic data, that relates to:
the individual’s past, present or future physical or mental health or condition,
the provision of health care to the individual, or
the past, present, or future payment for the provision of health care to the individual,
and that identifies the individual or for which there is a reasonable basis to believe it can be used to identify the individual.13 Individually identifiable health information includes many common identifiers (e.g., name, address, birth date, Social Security Number).
The Privacy Rule excludes from protected health information employment records that a covered entity maintains in its capacity as an employer and education and certain other records subject to, or defined in, the Family Educational Rights and Privacy Act, 20 U.S.C. §1232g.
Now there’s obviously an overlap between personally identifiable information (PII) and protected health information (PHI). For example, names, dates of birth, and Social Security Numbers fall into both categories. But I want to highlight two things are are explicitly mentioned as PHI that aren’t usually cited as PII.
Physical or mental health data. This could include information that a medical professional captures from a patient, including biometric (broad biometric) information such as heart rate or blood pressure.
Health care provided to an individual. This not only includes written information such as prescriptions, but oral information (“take two aspirin and call my chatbot in the morning”). Yes, chatbot. Deal with it. Dr. Marcus Welby and his staff retired a long time ago.
Robert Young (“Marcus Welby”) and Jane Wyatt (“Margaret Anderson” on a different show). By ABC TelevisionUploaded by We hope at en.wikipedia – eBay itemphoto informationTransferred from en.wikipedia by SreeBot, Public Domain, https://commons.wikimedia.org/w/index.php?curid=16472486
Because broad biometric data used for analysis, such as heart rates, can be combined with other data to personally identify an individual, organizations that process biometric data must undertake strict safeguards to protect that data. If protected health information (PHI) is not adequately guarded, people could be subject to fraud and other harms.
Simple, isn’t it?
Actually, the parallels between identity/biometrics and healthcare have fascinated me for decades, since the dedicated hardware to capture identity/biometric data is often similar to the dedicated hardware to capture health data. And now that we’re moving away from dedicated hardware to multi-purpose hardware such as smartphones, the parallels are even more fascinating.
Some firms make claims and don’t support them, while others support their claims with quantified benefits. But does quantifying help or harm the firms that do it? This pudding post answers this question…and then twists toward the identity/biometrics market at the end.
The “me too” players in the GCP market
Whoops.
In that heading above, I made a huge mistake by introducing an acronym without explaining it. So I’d better correct my error.
GCP stands for Glowing Carbonated Pudding.
I can’t assume that you already knew this acronym, because I just made it up. But I can assure you that the GCP market is a huge market…at least in my brain. All the non-existent kids love the scientifically advanced and maximally cool pudding that glows in the dark and has tiny bubbles in it.
Glowing Carbonated Pudding. Designed by Google Bard. Yeah, Google Bard creates images now.
Now if you had studied this non-existent market like I have, you’ll realize from the outset that most of the players don’t really differentiate their offerings. Here are a few examples of firms with poor product marketing:
Jane Spain GCP: “Trust us to provide good GCP.”
Betty Brazil GCP: “Trust us to provide really good GCP.”
Clara Canada GCP: “Trust us to provide great GCP.”
You can probably figure out what happened here.
The CEO at Betty Brazil told the company’s product marketers, “Do what Jane Spain did but do it better.”
After that Clara Canada’s CEO commanded, “Do what Betty Brazil did but do it better.” (I’ll let you in on a little secret. Clara Canada’s original slogan refereneced “the best GCP,” but Legal shot that down.)
But another company, Wendy Wyoming, decided to differentiate itself, and cited independent research as its differentiator.
Wendy Wyoming Out of This World GCP satisfies you, and we have independent evidence to prove it!
The U.S. National Institute of Standards and Technology, as part of its Pudding User Made (PUM, not FRTE) Test, confirmed that 80% of all Wendy Wyoming Out of This World GCP mixes result in pudding that both glows and is carbonated. (Mix WW3, submitted November 30, 2023; not omnigarde-003)
Treat your child to science-backed cuisine with Wendy Wyoming Out of This World GCP!Wendy Wyoming is a top tier (excluding Chinese mixes) GCP provider.
But there are other competitors…
The indirect competitor who questions the quantified benefits
There are direct competitors that provide the same product as Wendy Wyoming, Jane Spain, and everyone else.
And then there are indirect competitors who provide non-GCP alternatives that can substitute for GCPs.
For example, Polly Pennsylvania is NOT a GCP provider. It makes what the industry calls a POPS, or a Plain Old Pudding Sustenance. Polly Pennsylvania questions everything about GCP…and uses Wendy Wyoming’s own statistics against it.
Designed by Google Bard.
Fancy technologies have failed us.
If you think that one of these GCP puddings will make your family happy, think again. A leading GCP provider has publicly admitted that 1 out of every 5 children who buy a GCP won’t get a GCP. Either it won’t glow, or it’s not carbonated. Do you want to make your kid cry?
Treat your child to the same pudding that has satisfied many generations. Treat your child to Polly Pennsylvania Perfect POPS.
Pennsylvania Perfect remembers.
So who wins?
It looks like Polly Pennsylvania and Wendy Wyoming have a nasty fight on their hands. One that neck-deep marketers like to call a “war.” Except that nobody dies. (Sadly, that’s not true.)
Some people think that Wendy Wyoming wins because 4 out of 5 of their customers receive true GCP.
Others think that Polly Pennsylvaia wins because 5 out of 5 of their customers get POPS pudding.
But it’s clear who lost.
All the Jane Spains and Betty Brazils who didn’t bother to create a distinctive message.
Don’t be Jane Spain. Explain why your product is the best and all the other products aren’t.
Copying the competition doesn’t differentiate you. Trust me.
The “hungry people” (target audience) for THIS post
Oh, and if you didn’t figure it out already, this post was NOT intended for scientific pudding manufacturers. It was intended for identity/biometric firms who can use some marketing and writing help. Hence the references to NIST and the overused word “trust.”
If you’re hungry to kickstart your identity/biometric firm’s written content, click on the image below to learn about Bredemarket’s services.
We get all sorts of great tools, but do we know how to use them? And what are the consequences if we don’t know how to use them? Could we lose the use of those tools entirely due to bad publicity from misuse?
According to a report released in September by the US Government Accountability Office, only 5 percent of the 196 FBI agents who have access to facial recognition technology from outside vendors have completed any training on how to properly use the tools.
It turns out that the study is NOT limited to FBI use of facial recognition services, but also addresses six other federal agencies: the Bureau of Alcohol, Tobacco, Firearms and Explosives (the guvmint doesn’t believe in the Oxford comma); U.S. Customs and Border Protection; the Drug Enforcement Administration; Homeland Security Investigations; the U.S. Marshals Service; and the U.S. Secret Service.
Initially, none of the seven agencies required users to complete facial recognition training. As of April 2023, two of the agencies (Homeland Security Investigations and the U.S. Marshals Service) required training, two (the FBI and Customs and Border Protection) did not, and the other three had quit using these four facial recognition services.
The FBI stated that facial recognition training was recommended as a “best practice,” but not mandatory. And when something isn’t mandatory, you can guess what happened:
GAO found that few of these staff completed the training, and across the FBI, only 10 staff completed facial recognition training of 196 staff that accessed the service. FBI said they intend to implement a training requirement for all staff, but have not yet done so.
Although not a requirement, FBI officials said they recommend (as a best practice) that some staff complete FBI’s Face Comparison and Identification Training when using Clearview AI. The recommended training course, which is 24 hours in length, provides staff with information on how to interpret the output of facial recognition services, how to analyze different facial features (such as ears, eyes, and mouths), and how changes to facial features (such as aging) could affect results.
However, this type of training was not recommended for all FBI users of Clearview AI, and was not recommended for any FBI users of Marinus Analytics or Thorn.
I should note that the report was issued in September 2023, based upon data gathered earlier in the year, and that for all I know the FBI now mandates such training.
Or maybe it doesn’t.
What about your state and local facial recognition users?
Of course, training for federal facial recognition users is only a small part of the story, since most of the law enforcement activity takes place at the state and local level. State and local users need training so that they can understand:
The anatomy of the face, and how it affects comparisons between two facial images.
How cameras work, and how this affects comparisons between two facial images.
How poor quality images can adversely affect facial recognition.
How facial recognition should ONLY be used as an investigative lead.
If facial recognition users had been trained, none of the false arrests over the last few years would have taken place.
The users would have realized that the poor images were not of sufficient quality to determine a match.
The users would have realized that even if they had been of sufficient quality, facial recognition must only be used as an investigative lead, and once other data had been checked, the cases would have fallen apart.
But the false arrests gave the privacy advocates the ammunition they needed.
Not to insist upon proper training in the use of facial recognition.
Like nuclear or biological weapons, facial recognition’s threat to human society and civil liberties far outweighs any potential benefits. Silicon Valley lobbyists are disingenuously calling for regulation of facial recognition so they can continue to profit by rapidly spreading this surveillance dragnet. They’re trying to avoid the real debate: whether technology this dangerous should even exist. Industry-friendly and government-friendly oversight will not fix the dangers inherent in law enforcement’s discriminatory use of facial recognition: we need an all-out ban.
(And just wait until the anti-facial recognition forces discover that this is not only a plot of evil Silicon Valley, but also a plot of evil non-American foreign interests located in places like Paris and Tokyo.)
Because the anti-facial recognition forces want us to remove the use of technology and go back to the good old days…of eyewitness misidentification.
Eyewitnesses are often expected to identify perpetrators of crimes based on memory, which is incredibly malleable. Under intense pressure, through suggestive police practices, or over time, an eyewitness is more likely to find it difficult to correctly recall details about what they saw.
Apologies in advance, but if you’re NOT interested in fingerprints, you’ll want to skip over this Bredemarket identity/biometrics post, my THIRD one about fingerprint uniqueness and/or similarity or whatever because the difference between uniqueness and similarity really isn’t important, is it?
Yes, one more post about the study whose principal author was Gabe Guo, the self-styled “inventor of cross-fingerprint recognition.”
I also wrote something only on LinkedIn (and Facebook) that cited a CNN article that quoted Christophe Champod and Simon Cole. (Interestingly enough, my last post on Cole concerned how words matter, which is appropriate in this discussion.) Unfortunately, the person who wrote the CNN headline (“Are fingerprints unique? Not really, AI-based study finds”) didn’t pay attention to a word that Champod and Simon Cole said.
But don’t miss this
Well, two other people have weighed in on the paper: Glenn Langenburg and Eric Ray, co-presenters on the Double Loop Podcast. (“Double loop” is a fingerprint thing.)
So who are Langenburg and Ray? You can read their full biographies here, but both of them are certified latent print examiners. This certification, administered by the International Association for Identification, is designed to ensure that the certified person is knowledgeable about both latent (crime scene) fingerprints and known fingerprints, and how to determine whether or not two prints come from the same person. If someone is going to testify in court about fingerprint comparison, this certification is recognized as a way to designate someone as an expert on the subject, as opposed to a college undergraduate. (As of today, the list of IAI certified latent print examiners as of December 2023 can be found here in PDF form.)
Podcast episode 264 dives into the Columbia study in detail, including what the study said, what it didn’t say, and what the publicity for the study said that doesn’t match the study.
Eric and Glenn respond to the recent allegations that a computer science undergraduate at Columbia University, using Artificial Intelligence, has “proven that fingerprints aren’t unique” or at least…that’s how the media is mischaracterizing a new published paper by Guo, et al. The guys dissect the actual publication (“Unveiling intra-person fingerprint similarity via deep contrastive learning” in Science Advances, 2024 by Gabe Guo, et al.). They state very clearly what the paper actually does show, which is a far cry from the headlines and even public dissemination originating from Columbia University and the author. The guys talk about some of the important limitations of the study and how limited the application is to real forensic investigations. They then explore some of the media and social media outlets that have clearly misunderstood this paper and seem to have little understanding of forensic science. Finally, Eric and Glenn look at some quotes and comments from knowledgeable sources who also have recognized the flaws in the paper, the authors’ exaggerations, and lack of understanding of the value of their findings.
Yes, the episode is over an hour long, but if you want to hear a good discussion of the paper that goes beyond the headlines, I strongly recommend that you listen to it.
TL;DR
If you’re in a TL;DR frame of mind, I’ll just offer one tidbit: “uniqueness” and “similarity” are not identical. Frankly, they’re not even similar.
This post concentrates on IDENTIFICATION perfection, or the ability to enjoy zero errors when identifying individuals.
The risk of claiming identification perfection (or any perfection) is that a SINGLE counter-example disproves the claim.
If you assert that your biometric solution offers 100% accuracy, a SINGLE false positive or false negative shatters the assertion.
If you claim that your presentation attack detection solution exposes deepfakes (face, voice, or other), then a SINGLE deepfake that gets past your solution disproves your claim.
And as for the pre-2009 claim that latent fingerprint examiners never make a mistake in an identification…well, ask Brandon Mayfield about that one.
In fact, I go so far as to avoid using the phrase “no two fingerprints are alike.” Many years ago (before 2009) in an International Association for Identification meeting, I heard someone justify the claim by saying, “We haven’t found a counter-example yet.” That doesn’t mean that we’ll NEVER find one.
At first glance, it appears that Motorola would be the last place to make a boneheaded mistake like that. After all, Motorola is known for its focus on quality.
But in actuality, Motorola was the perfect place to make such a mistake, since it was one of the champions of the “Six Sigma” philosophy (which targets a maximum of 3.4 defects per million opportunities). Motorola realized that manufacturing perfection is impossible, so manufacturers (and the people in Motorola’s weird Biometric Business Unit) should instead concentrate on reducing the error rate as much as possible.
So one misspelling could be tolerated, but I shudder to think what would have happened if I had misspelled “quality” a second time.