(Part of the biometric product marketing expert series)
Any endeavor, scientific or non-scientific, tends to generate a host of acronyms that the practitioners love to use.
For people interested in fingerprint identification, I’ve written this post to delve into some of the acronyms associated with NIST MINEX testing, including ANSI, INCITS, FIPS, and PIV.
And, of course, NIST and MINEX.
After defining what the acronyms stand for, I’ll talk about the MINEX III test. Because fingerprints are still relevant.
Common MINEX acronyms
NIST
We have to start with NIST, of course. NIST is the National Institute of Standards and Technology, part of the U.S. Department of Commerce.

NIST was involved with fingerprints before NIST even existed. Back when NIST was still the NBS (National Bureau of Standards), it issued its first fingerprint interchange standard back in 1986. I’ve previously talked about the 1993 version of the standard in this post, “When 250ppi Binary Fingerprint Images Were Acceptable.”
But let’s move on to another type of interchange.
MINEX
It’s even more important that we define MINEX, which stands for Minutiae (M) Interoperability (IN) Exchange (EX).

You’ll recall that the 1993 (and previous, and subsequent) versions of the ANSI/NIST standard included a “Type 9” to record the minutiae generated by the vendor for each fingerprint. However, each vendor generated minutiae according to its own standard. Back in 1993 Cogent had its standard, NEC its standard, Morpho its standard, and Printrak its standard.
So how do you submit Cogent minutiae to a Printrak system? There are two methods:
First, you don’t submit them at all. Just ignore the Cogent minutiae, look at the Printrak image, and use an algorithm regenerate the minutiae to the Printrak standard. While this works with high quality tenprints, it won’t work with low quality latent (crime scene) prints that require human expertise.
The second method is to either convert the Cogent minutiae to the Printrak minutiae standard, or convert both standards into a common format.
Something like ANSI INCITS 378-2009 (S2019).
So I guess we need to define two more acronyms.
ANSI
Actually, I should have defined ANSI earlier, since I’ve already referred to it when talking about the ANSI/NIST data interchange formats.
ANSI is the American National Standards Institute. Unlike NIST, which is an agency of the U.S. government, ANSI is a private entity. Here’s how it describes itself:
The American National Standards Institute (ANSI) is a private, non-profit organization that administers and coordinates the U.S. voluntary standards and conformity assessment system. Founded in 1918, the Institute works in close collaboration with stakeholders from industry and government to identify and develop standards- and conformance-based solutions to national and global priorities….
ANSI is not itself a standards developing organization. Rather, the Institute provides a framework for fair standards development and quality conformity assessment systems and continually works to safeguard their integrity.
So ANSI, rather than creating its own standards, works with outside organizations such as NIST…and INCITS.
INCITS
Now that’s an eye-catching acronym, but INCITS isn’t trying to cause trouble. Really, they’re not. Believe me.
INCITS, or the InterNational Committee for Information Technology Standards, is another private organization. It’s been around since 1961, and like NIST has been known under different names in the past.
Back in 2004, INCITS worked with ANSI (and NIST, who created samples) to develop three standards: one for finger images (ANSI INCITS 381-2004), one for face recognition (ANSI INCITS 385-2004), and one for finger minutiae (ANSI INCITS 378-2004, superseded by ANSI INCITS 378-2009 (S2019)).

When entities used this vendor-agnostic minutiae format, then minutiae from any vendor could in theory be interchanged with those from any other vendor.
This came in handy when the FIPS was developed for PIV. Ah, two more acronyms.
FIPS and PIV
One year after the three ANSI INCITS standards were released, this happened (the acronyms are defined in the text):
Federal Information Processing Standard (FIPS) 201 entitled Personal Identity Verification of Federal Employees and Contractors establishes a standard for a Personal Identity Verification (PIV) system (Standard) that meets the control and security objectives of Homeland Security Presidential Directive-12 (HSPD-12). It is based on secure and reliable forms of identity credentials issued by the Federal Government to its employees and contractors. These credentials are used by mechanisms that authenticate individuals who require access to federally controlled facilities, information systems, and applications. This Standard addresses requirements for initial identity proofing, infrastructure to support interoperability of identity credentials, and accreditation of organizations issuing PIV credentials.

So the PIV, defined by a FIPS, based upon an ANSI INCITS standard, defined a way for multiple entities to create and support fingerprint minutiae that were interoperable.
But how do we KNOW that they are interoperable?
Let’s go back to NIST and MINEX.
Testing interoperability
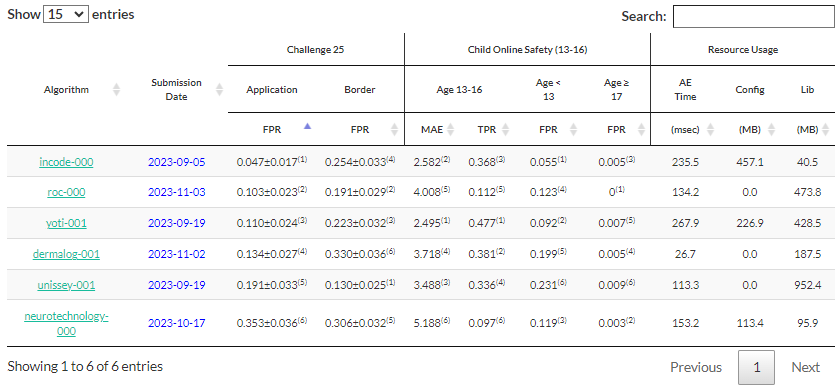
So NIST ended up in charge of figuring out whether these interoperable minutiae were truly interoperable, and whether minutiae generated by a Cogent system could be used by a Printrak system. Of course, by the time MINEX testing began Printrak no longer existed, and a few years later Cogent wouldn’t exist either.
You can read the whole history of MINEX testing here, but for now I’m going to skip ahead to MINEX III (which occurred many years after MINEX04, but who’s counting?).
- Like some other NIST tests we’ve seen before, vendors and other entities submit their algorithms, and NIST does the testing itself.
- In this case, all submitters include a template generation algorithm, and optionally can include a template matching algorithm.
- Then NIST tests each algorithm against every other algorithm. So the “innovatrics+0020” template generator is tested against itself, and is also tested against the “morpho+0115” algorithm, and all the other algorithms.

NIST then performs its calculations and comes up with summary values of interoperability, which can be sliced and diced a few different ways for both template generators and template matchers.

And this test, like some others, is an ongoing test, so perhaps in a few months someone will beat Innovatrics for the top pooled 2 fingers spot.
Are fingerprints still relevant?
And entities WILL continue to submit to the MINEX III test. While a number of identity/biometric professionals (frankly, including myself) seem to focus on faces rather than fingerprints, fingers still play a vital role in biometric identification, verification, and authentication.
Fingerprints are clearly a 21st century tool.
Even if one vendor continues its obsession with 1970s crime fighters.

And no, I’m NOT going to explain what the acronym FAP means. This post has too many acronyms already (TMAA).