“Google has released its MedGemma and MedSigLIP models to the public, and they’re powerful enough to analyse chest X-rays, medical images, and patient histories like a digital second opinion.”
“In the United States, it is a criminal offense for a person to claim they are a health professional when they are not. But what about a non-person entity?”
In the announcement, Google asserted that their tools are privacy-preserving, allowing developers to control privacy. In fact, developers are frequently mentioned in the announcement. Yes, developers.
OH wait, that was Microsoft.
The implication: Google just provides the tool: developers are responsible for its use. And the long disclaimer includes this sentence:
“The outputs generated by these models are not intended to directly inform clinical diagnosis, patient management decisions, treatment recommendations, or any other direct clinical practice applications.”
We’ve faced this before
And we’ve addressed this also, regarding proper use of facial recognition ONLY as an investigative lead. Responsible vendors emphasize this:
“In a piece on the ethical use of facial recognition, Rank One Computing stated the following in passing:
“‘[Rank One Computing] is taking a proactive stand to communicate that public concerns should focus on applications and policies rather than the technology itself.’”
But just because ROC or Clearview AI or another vendor communicates that facial recognition should ONLY be used as an investigative lead…does that mean that their customers will listen?
Keeping the internet open is crucial, and part of being open means Reddit content needs to be accessible to those fostering human learning and researching ways to build community, belonging, and empowerment online. Reddit is a uniquely large and vibrant community that has long been an important space for conversation on the internet. Additionally, using LLMs, ML, and AI allow Reddit to improve the user experience for everyone.
In line with this, Reddit and OpenAI today announced a partnership to benefit both the Reddit and OpenAI user communities…
Perhaps some members of the Reddit user community may not feel the benefits when OpenAI is training on their data.
While people who joined Reddit presumably understood that anyone could view their data, they never imagined that a third party would then process its data for its own purposes.
Oh, but wait a minute. Reddit clarifies things:
This partnership…does not change Reddit’s Data API Terms or Developer Terms, which state content accessed through Reddit’s Data API cannot be used for commercial purposes without Reddit’s approval. API access remains free for non-commercial usage under our published threshold.
We get all sorts of great tools, but do we know how to use them? And what are the consequences if we don’t know how to use them? Could we lose the use of those tools entirely due to bad publicity from misuse?
According to a report released in September by the US Government Accountability Office, only 5 percent of the 196 FBI agents who have access to facial recognition technology from outside vendors have completed any training on how to properly use the tools.
It turns out that the study is NOT limited to FBI use of facial recognition services, but also addresses six other federal agencies: the Bureau of Alcohol, Tobacco, Firearms and Explosives (the guvmint doesn’t believe in the Oxford comma); U.S. Customs and Border Protection; the Drug Enforcement Administration; Homeland Security Investigations; the U.S. Marshals Service; and the U.S. Secret Service.
Initially, none of the seven agencies required users to complete facial recognition training. As of April 2023, two of the agencies (Homeland Security Investigations and the U.S. Marshals Service) required training, two (the FBI and Customs and Border Protection) did not, and the other three had quit using these four facial recognition services.
The FBI stated that facial recognition training was recommended as a “best practice,” but not mandatory. And when something isn’t mandatory, you can guess what happened:
GAO found that few of these staff completed the training, and across the FBI, only 10 staff completed facial recognition training of 196 staff that accessed the service. FBI said they intend to implement a training requirement for all staff, but have not yet done so.
Although not a requirement, FBI officials said they recommend (as a best practice) that some staff complete FBI’s Face Comparison and Identification Training when using Clearview AI. The recommended training course, which is 24 hours in length, provides staff with information on how to interpret the output of facial recognition services, how to analyze different facial features (such as ears, eyes, and mouths), and how changes to facial features (such as aging) could affect results.
However, this type of training was not recommended for all FBI users of Clearview AI, and was not recommended for any FBI users of Marinus Analytics or Thorn.
I should note that the report was issued in September 2023, based upon data gathered earlier in the year, and that for all I know the FBI now mandates such training.
Or maybe it doesn’t.
What about your state and local facial recognition users?
Of course, training for federal facial recognition users is only a small part of the story, since most of the law enforcement activity takes place at the state and local level. State and local users need training so that they can understand:
The anatomy of the face, and how it affects comparisons between two facial images.
How cameras work, and how this affects comparisons between two facial images.
How poor quality images can adversely affect facial recognition.
How facial recognition should ONLY be used as an investigative lead.
If facial recognition users had been trained, none of the false arrests over the last few years would have taken place.
The users would have realized that the poor images were not of sufficient quality to determine a match.
The users would have realized that even if they had been of sufficient quality, facial recognition must only be used as an investigative lead, and once other data had been checked, the cases would have fallen apart.
But the false arrests gave the privacy advocates the ammunition they needed.
Not to insist upon proper training in the use of facial recognition.
Like nuclear or biological weapons, facial recognition’s threat to human society and civil liberties far outweighs any potential benefits. Silicon Valley lobbyists are disingenuously calling for regulation of facial recognition so they can continue to profit by rapidly spreading this surveillance dragnet. They’re trying to avoid the real debate: whether technology this dangerous should even exist. Industry-friendly and government-friendly oversight will not fix the dangers inherent in law enforcement’s discriminatory use of facial recognition: we need an all-out ban.
(And just wait until the anti-facial recognition forces discover that this is not only a plot of evil Silicon Valley, but also a plot of evil non-American foreign interests located in places like Paris and Tokyo.)
Because the anti-facial recognition forces want us to remove the use of technology and go back to the good old days…of eyewitness misidentification.
Eyewitnesses are often expected to identify perpetrators of crimes based on memory, which is incredibly malleable. Under intense pressure, through suggestive police practices, or over time, an eyewitness is more likely to find it difficult to correctly recall details about what they saw.
Identity and biometrics firms can achieve quantifiable benefits with prospects by blogging. Over 40 identity and biometrics firms are already blogging. Is yours?
These firms (and probably many more) already recognize the value of identity blog post writing, and some of them are blogging frequently to get valuable content to their prospects and customers.
Is your firm on the list? If so, how frequently do you update your blog?
In most cases, I can provide your blog post via my standard package, the Bredemarket 400 Short Writing Service. I offer other packages and options if you have special needs.
Get in touch with Bredemarket
Authorize Bredemarket, Ontario California’s content marketing expert, to help your firm produce words that return results.
To discuss your identity/biometrics blog post needs further,book a meeting with me at calendly.com/bredemarket. On the questionnaire, select the Identity/biometrics industry and Blog post content.
In the security world (biometrics, access control, cybersecurity, and other areas), there has been a lot of discussion about the national origins and/or ownership of various security products.
If a particular product originates in country X, then will the government of country X require the product to serve the national interests of country X?
Marketing materials that state that a particular product is the best “among Western vendors” (which may or may not explain why this is important – see the second caveat here for examples).
European Union regulations that serve to diminish American influence.
The policies of certain countries (China, Iran, North Korea, Russia) that serve to eliminate American influence entirely.
Clearview AI, Ukraine, and Russia
Clearview AI is a U.S. company, but its relationship with the U.S. government is, in Facebook terms, “complicated.”
It’s complicated primarily because “the U.S. government” consists of a number of governments at the federal, state, and local level, and a number of agencies within these governments that sometimes work at cross-purposes with one another. Some U.S. government agencies love Clearview AI, while others hate it.
However, according to Reuters, the Ukrainian government can be counted in the list of governments that love Clearview AI.
Ukraine is receiving free access to Clearview AI’s powerful search engine for faces, letting authorities potentially vet people of interest at checkpoints, among other uses, added Lee Wolosky, an adviser to Clearview and former diplomat under U.S. presidents Barack Obama and Joe Biden.
Here is an example of a company that is supporting certain foreign policies of the government in which it resides. Depending upon your own national origin, you may love this example, or you may hate this example.
Of course, even some who support U.S. actions in Ukraine may not support Clearview AI’s actions in Ukraine. But that’s another story.
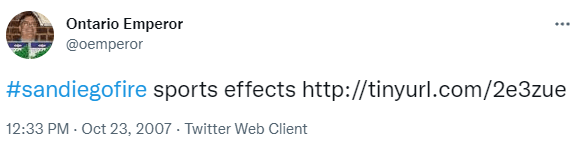
Back on October 23, 2007, I used my then-active Twitter account to tweet about the #sandiegofire. The San Diego fire was arguably the first mass adoption of hashtags, building upon pioneering work by Stowe Boyd and Chris Messina and acted upon by Nate Ritter and others.
The tinyurl link directed followers to my post detailing how the aforementioned San Diego Fire was displacing sports teams, including the San Diego Chargers. (Yes, kids, the Chargers used to play in San Diego.)
So while I was there at the beginning of hashtags, I’m proudest of the post that I wrote a couple of months later, entitled “Hashtagging Challenges When Events Occur at Different Times in Different Locations.” It describes the challenges of talking about the Rose Parade when someone is viewing the beginning of the parade while someone else is viewing the end of the parade at the same time. (This post was cited on PBWorks long ago, referenced deep in a Stowe Boyd post, and cited elsewhere.)
Hashtag use in business
Of course, hashtags have changed a lot since 2007-2008. After some resistance, Twitter formally supported the use of hashtags, and Facebook and other services followed, leading to mass adoption beyond the Factory Joes of the world.
Ignoring personal applications for the moment, hashtags have proven helpful for business purposes, especially when a particular event is taking place. No, not a fire in a major American city, but a conference of some sort. Conferences of all types have rushed to adopt hashtags so that conference attendees will promote their conference attendance. The general rule is that the more techie the conference, the more likely the attendees will use the conference-promoted hashtag.
I held various social media responsibilities during my years at MorphoTrak and IDEMIA, some of which were directly connected to the company’s annual user conference, and some of which were connected to the company’s attendance at other events. Obviously we pulled out the stops for our own conferences, including adopting hashtags that coincided with the conference theme.
And then when the conference organizers adopt a hashtag, they fervently hope that people will actually USE the adopted hashtag. As I said before, this isn’t an issue for the technical conferences, but it can be an issue at the semi-technical conferences. (“Hey, everybody! Gather around the screen! Someone used the conference hashtag…oh wait a minute, that’s my burner account.”)
A pleasant surprise with exhibitor/speaker adoption of the #connectID hashtag
Well, I think that we’ve finally crossed a threshold in the biometric world, and hashtags are becoming more and more acceptable.
As I previously mentioned, I’m not attending next week’s connect:ID conference in Washington DC, but I’m obviously interested in the proceedings.
I was pleasantly surprised to see that nearly two dozen exhibitors and speakers were using the #connectID hashtag (or referenced via the hashtag) as of the Friday before the event, including Acuity Market Intelligence, Aware, BIO-key, Blink Identity, Clearview AI, HID Global, IDEMIA, Integrated Biometrics, iProov, Iris ID, Kantara, NEC and NEC NSS, Pangiam, Paravision, The Paypers, WCC, WorldReach Software/Entrust, and probably some others by the time you read this, as well as some others that I may have missed.
And the event hasn’t even started yet.
At least some of the companies will have the presence of mind to tweet DURING the event on Tuesday and Wednesday.
Will yours be one of them?
But company adoption is only half the battle
While encouraging to me, adoption of a hashtag by a conference’s organizers, exhibitors, and speakers is only the beginning.
The true test will take place when (if) the ATTENDEES at the conference also choose to adopt the conference hashtag.
According to Terrapin (handling the logistics of conference organization), more than 2,500 people are registered for the conference. While the majority of these people are attending the free exhibition, over 750 of them are designated as “conference delegates” who will attend the speaking sessions.
How many of these people will tweet or post about #connectID?
I have not been to an identity trade show in years, and sadly I won’t be in Washington DC next week for connect:ID…although I’ll be thinking about it.
I’ve only been to connect:ID once, in 2015. Back in those days I was a strategic marketer with MorphoTrak, and we were demonstrating the MorphoWay. No, not the Morpho Way; the MorphoWay.
As an aside, you’ll notice how big MorphoWay is…which renders it impractical for use in U.S. airports, since space is valuable and therefore security features need a minimum footprint. MorphoWay has a maximum footprint…just ask the tradespeople who were responsible for getting it on and off the trade show floor.
I still remember several other things from this conference. For example, in those days one of Safran’s biometric competitors was 3M. Of course both Safran and 3M have exited the biometric industry, but at the time they were competing against each other. Companies always make a point of checking out the other companies at these conferences, but when I went to 3M’s booth, the one person I knew best (Teresa Wu) was not at the booth. Later that year, Teresa would leave 3M and (re)join Safran, where she remains to this day.
Yes, there is a lot of movement of people between firms. Looking over the companies in the connect:ID 2021 Exhibitor Directory, I know people at a number of these firms. Obviously people from IDEMIA, of course (IDEMIA was the company that bought Safran’s identity business), but I also know people at other companies, all of whom who were former coworkers at IDEMIA or one of its predecessor companies:
Aware.
Clearview AI.
GET Group North America.
HID Global.
Integrated Biometrics.
iProov.
NEC.
Paravision.
Rank One Computing.
SAFR/RealNetworks.
Thales.
Probably some others that I missed.
And I know people at some of the other companies, organizations, and governmental entities that are at connect:ID this year.
Some of these entities didn’t even exist when I was at connect:ID six years ago, and some of these entities (such as Thales) have entered the identity market due to acquisitions (in Thales’ case, the acquisition of Gemalto, which had acquired 3M’s biometric business).
So while I’m not crossing the country next week, I’m obviously thinking of everything that will be going on there.
Incidentally, this is one of the last events of the trade show season, which is starting to wind down for the year. But it will ramp up again next spring (for you Northern Hemisphere folks).
This post examines a number of issues regarding the use of facial recognition. Specifically, it looks at various ways to use facial recognition to identify people who participated in the U.S. Capitol attack.
Let’s start with the technological issues before we look at the legal ones. Specifically, we’ll look at three possible ways to construct databases (galleries) to use for facial recognition, and the benefits and drawbacks of each method.
What a facial recognition system does, and what it doesn’t do
The purpose of a one-to-many facial recognition system is to take a facial image (a “probe” image), process it, and compare it to a “gallery” of already-processed facial images. The system then calculates some sort of mathematical likelihood that the probe matches some of the images in the gallery.
That’s it. That’s all the system does, from a technological point of view.
Although outside of the scope of this particular post, I do want to say that a facial recognition system does NOT determine a match. Now the people USING the system could make the decision that one or more of the images in the gallery should be TREATED as a match, based upon mathematical considerations. However, when using a facial recognition system in the United States for criminal purposes, the general procedure is for a trained facial examiner to use his/her expertise to compare the probe image with selected gallery images. This trained examiner will then make a determination, regardless of what the technology says.
But forget about that for now. I want to concentrate on another issue—adding data to the gallery.
Options for creating a facial recognition “gallery”
As I mentioned earlier, the “gallery” is the database against which the submitted facial image (the “probe”) is compared. In a one-to-many comparison, the probe image is compared against all or some of the images in the gallery. (I’m skipping over the “all or some” issue for now.)
So where do you get facial images to put in the gallery?
For purposes of this post, I’m going to describe three sources for gallery images.
Government facial images of people who have been convicted of crimes.
Government facial images of people who have not necessarily been convicted of crimes, such as people who have been granted driver’s licenses or passports.
Publicly available facial images.
Before delving into these three sources of gallery images, I’m going to present a use case. A few of you may recognize it.
Let’s say that there is an important government building located somewhere, and that access to the building is restricted for security reasons. Now let’s say that some people breach that access and illegally enter the building. Things happen, and the people leave. (Again, why they left and weren’t detained immediately is outside the scope of this post.)
Now that a crime has been committed, the question arises—how do you use facial recognition to solve the crime?
A gallery of government criminal facial images
Let’s look at a case in which the images of people who trespassed at the U.S. Capitol…
Whoops, I gave it away! Yes, for those of you who didn’t already figure it out, I’m specifically talking about the people who entered the U.S. Capitol on Wednesday, January 6. (This will NOT be the only appearance of Captain Obvious in this post.)
Anyway, let’s see how the images of people who trespassed at the U.S. Capitol can be compared against a gallery of images of criminals.
From here on in, we need to not only look at technological issues, but also legal issues. Technology does not exist in a vacuum; it can (or at least should) only be used in accordance with the law.
So we have a legal question: can criminal facial images be lawfully used to identify people who have committed crimes?
In most cases, the answer is yes. The primary reason that criminal databases are maintained in the first place is to identify repeat offenders. If someone habitually trespasses into government buildings, the government would obviously like to know when the person trespasses into another government building.
But why did I say “in most cases”? Because there are cases in which a previously-created criminal record can no longer be used.
The record is sealed or expunged. This could happen, for example, if a person committed a crime as a juvenile. After some time, the record could be sealed (prohibiting most access) or expunged (removed entirely). If a record is sealed or expunged, then data in the record (including facial images) shouldn’t be available in the gallery.
The criminal is pardoned. If someone is pardoned of a crime, then it’s legally the same as if the crime were never committed at all. In that case, the pardoned person’s criminal record may (or may not) be removed from the criminal database. If it is removed, then again the facial image shouldn’t be in the gallery.
The crime happened a long time ago. Decades ago, it cost a lot of money to store criminal records, and due to budgetary constraints it wasn’t worthwhile to keep on storing everything. In my corporate career, I’ve encountered a lot of biometric requests for proposal (RFPs) that required conversion of old data to the new biometric system…with the exception of the old stuff. It stands to reason that if the old arrest record from 1960 is never converted to the new system, then that facial image won’t be in the gallery.
So, barring those exceptions, a search of our probe image from the U.S. Capitol could potentially hit against records in the gallery of criminal facial images.
Great, right?
Well, there’s a couple of issues to consider.
First, there are a lot of criminal databases out there. For those who imagine that the FBI, and the CIA, and the BBC, BB King, and Doris Day (yes) have a single massive database with every single criminal record out there…well, they don’t.
There are multiple federal criminal databases out there, and it took many years to get two of the major ones (from the FBI and the Department of Homeland Security) to talk to each other.
And every state has its own criminal database; some records are submitted to the FBI, and some aren’t.
Oh, and there are also local databases. For many years, one of my former employers was the automated fingerprint identification system provider for Bullhead City, Arizona. And there are a lot of Bullhead City-sized databases; one software package, AFIX Tracker (now owned by Aware) has over 500 installations.
So it you want to search criminal databases, you’re going to have to search a bunch of them. Between the multiple federal databases, the state and territory databases, and the local databases, there are hundreds upon hundreds of databases to search. That could take a while.
Which brings us to the second issue, in which we put on our Captain Obvious hat. If a person has never committed a crime, the person’s facial image is NOT in a criminal database. While biometric databases are great at identifying repeat offenders, they’re not so good at identifying first offenders. (They’re great at identifying second offenders, when someone is arrested for a crime and matches against an unidentified biometric record from a previous crime.)
So even if you search all the criminal databases, you’re only going to find the people with previous records. Those who were trespassing at the U.S. Capitol for the first time are completely invisible to a criminal database.
So something else is needed.
A gallery of government non-criminal facial images
Faced with this problem, you may ask yourself (yes), “What if the government had a database of people who hadn’t committed crimes? Could that database be used to identify the people who stormed the U.S. Capitol?”
Well, various governments DO have non-criminal facial databases. The two most obvious examples are the state databases of people who have driver’s licenses or state ID cards, and the federal database of people who have passports.
(This is an opportune time to remind my non-U.S. readers that the United States does not have national ID cards, and any attempt to create a national ID card is fought fiercely.)
I’ll point out the Captain Obvious issue right now: if someone never gets a passport or driver’s license, they’re not going to be in a facial database. This is of course a small subset of the population, but it’s a potential issue.
There’s a much bigger issue regarding the legal ability to use driver’s license photos in criminal investigation. As of 2018, 31 states allowed the practice…which means that 19 didn’t.
So while searches of driver’s license databases offer a good way to identify Capitol trespassers, it’s not perfect either.
A gallery of publicly available facial images
Which brings us to our third way to populate a gallery of facial images to identify Capitol trespassers.
It turns out that governments are not the only people that store facial images. You can find facial images everywhere. My own facial image can be found in countless places, including a page on the Bredemarket website itself.
There are all sorts of sites that post facial images that can be accessible to the public. A few of these sites include Facebook, Google (including YouTube), LinkedIn (part of Microsoft), Twitter, and Venmo. (We’ll return to those companies later.)
In many cases, these image are tied to (non-verified) identities. For example, if you go to my LinkedIn page, you will see an image that purports to be the image of John Bredehoft. But LinkedIn doesn’t know with 100% certainty that this is really an image of John Bredehoft. Perhaps “John Bredehoft” exists, but the posted picture is not that of John Bredehoft. Or perhaps “John Bredehoft” doesn’t exist and is a synthetic identity.
But regardless, there are billions of images out there, tied to billions of purported identities.
What if you could compare the probe images from the U.S. Capitol against a gallery of those billions of images—many more images than held by any government?
Clearview AI’s…facial-recognition app has seen a spike in use as police track down the pro-Trump insurgents who descended on the Capitol on Wednesday….
Clearview AI CEO Hoan Ton-That confirmed to Gizmodo that the app saw a 26% jump in search volume on Jan. 7 compared to its usual weekday averages….
Detectives at the Miami Police Department are using Clearview’s tech to identify rioters in images and videos of the attack and forwarding suspect leads to the FBI, per the Times. Earlier this week, the Wall Street Journal reported that an Alabama police department was also employing Clearview’s tech to ID faces in footage and sending potential matches along to federal investigators.
But now we need to return to the legal question: is “publicly available” equivalent to “publicly usable”?
Certain companies, including the aforementioned Facebook, Google (including YouTube), LinkedIn (part of Microsoft), Twitter, and Venmo, maintain that Clearview AI does NOT have permission to use their publicly available data. Not because of government laws, but because of the companies’ own policies. Here’s what two of the companies said about a year ago:
“Scraping people’s information violates our policies, which is why we’ve demanded that Clearview stop accessing or using information from Facebook or Instagram,” Facebook’s spokesperson told Business Insider….
“YouTube’s Terms of Service explicitly forbid collecting data that can be used to identify a person. Clearview has publicly admitted to doing exactly that, and in response, we sent them a cease-and-desist letter.”
For its part, Clearview AI maintains that its First Amendment government rights supersede the terms of service of the companies.
But other things come in play in addition to terms of service. Lawsuits filed in 2020 allege that Clearview AI’s practices violate the California Consumer Privacy Act of 2018, and the even more stringent Illinois Biometric Information Privacy Act of 2008. BIPA is so stringent that even Google is affected by it; as I’ve previously noted, Google’s Nest Hello Video Doorbell’s “familiar face” alerts is not available in Illinois.
Between corporate complaints and aggrieved citizens, the jury is literally still out on Clearview AI’s business model. So while it may work technologically, it may not work legally.
And one more thing
Of course, people are asking themselves, why do we even need to use facial recognition at all? After all, some of the trespassers actually filmed themselves trespassing. And when people see the widely-distributed pictures of the trespassers, they can be identified without using facial recognition.
Yes, to a point.
While it seems intuitive that eyewitnesses can easily identify people in photos, it turns out that such identifications can be unreliable. As the California Innocence Project reminds us:
One of the main causes of wrongful convictions is eyewitness misidentifications. Despite a high rate of error (as many as 1 in 4 stranger eyewitness identifications are wrong), eyewitness identifications are considered some of the most powerful evidence against a suspect.
The California Innocence Project then provides an example of a case in which someone was inaccurately identified due to an eyewitness misidentification. Correction: it provided 11 examples, including ones in which the witnesses were presented to the viewer in a controlled environment (six-pack lineups, similar backgrounds).
The FBI project, in which people look at images captured from the U.S. Capitol itself, is NOT a controlled environment.