(Part of the biometric product marketing expert series)
Are you an executive with a small or medium sized identity/biometrics firm?
If so, you want to share the story of your identity firm. But what are you going to say?
How will you figure out what makes your firm better than all the inferior identity firms that compete with you?
How will you get the word out about why your identity firm beats all the others?
Are you getting tired of my repeated questions?
Are you ready for the answers?
Your identity firm differs from all others
Over the last 29 years, I (John E. Bredehoft of Bredemarket) have worked for and with over a dozen identity firms, either as an employee or as a consultant.
You’d think that since I have worked for so many different identity firms, it’s an easy thing to start working with a new firm by simply slapping down the messaging that I’ve created for all the other identity firms.
Nothing could be further from the truth.

Every identity firm needs different messaging.
- The messaging that I created in my various roles at IDEMIA and its corporate predecessors was dramatically different than the messaging I created as a Senior Product Marketing Manager at Incode Technologies, which was also very different from the messaging that I created for my previous Bredemarket clients.
- IDEMIA benefits such as “servicing your needs anywhere in the world” and “applying our decades of identity experience to solve your problems” are not going to help with a U.S.-only firm that’s only a decade old.
- Similarly, messaging for a company that develops its own facial recognition algorithms will necessarily differ from messaging for a company that chooses the best third-party facial recognition algorithms on the market.
So which messaging is right?
It depends on who is paying me.
How your differences affect your firm’s messaging
When creating messaging for your identity firm, one size does not fit all, for the reasons listed above.
The content of your messaging will differ, based upon your differentiators.
- For example, if you were the U.S.-only firm established less than ten years ago, your messaging would emphasize the newness of your solution and approach, as opposed to the stodgy legacy companies that never updated their ideas.
- And if your firm has certain types of end users, such as law enforcement users, your messaging would probably feature an abundance of U.S. flags.
In addition, the channels that you use for your messaging will differ.
Identity firms will not want to market on every single social media channel. They will only market on the channels where their most motivated buyers are present.
- That may be your own website.
- Or LinkedIn.
- Or Facebook.
- Or Twitter.
- Or Instagram.
- Or YouTube.
- Or TikTok.
- Or a private system only accessible to people with a Top Secret Clearance.
- Or display advertisements located in airports.
It may be more than one of these channels, but it probably won’t be all of them.
But before you work on your content or channels, you need to know what to say, and how to communicate it.
How to know and communicate your differentiators
As we’ve noted, your firm is different than all others.
- How do you know the differences?
- How do you know what you want to talk about?
- How do you know what you DON’T want to talk about?
Here are three methods to get you started on knowing and communicating your differentiators in your content.
Method One: The time-tested SWOT analysis
If you talk to a marketer for more than two seconds about positioning a company, the marketer will probably throw the acronym “SWOT” back at you. I’ve mentioned the SWOT acronym before.
For those who don’t know the acronym, SWOT stands for
- Strengths. These are internal attributes that benefit your firm. For example, your firm is winning a lot of business and growing in customer count and market share.
- Weaknesses. These are also internal attributes, but in this case the attributes that detract from your firm. For example, you have very few customers.
- Opportunities. These are external factors that enhance your firm. One example is a COVID or similar event that creates a surge in demand for contactless solutions.
- Threats. The flip side is external factors that can harm your firm. One example is increasing privacy regulations that can slow or halt adoption of your product or service.
If you’re interested in more detail on the topic, there are a number of online sources that discuss SWOT analyses. Here’s TechTarget’s discussion of SWOT.
The common way to create the output from a SWOT analysis is to create four boxes and list each element (S, W, O, and T) within a box.
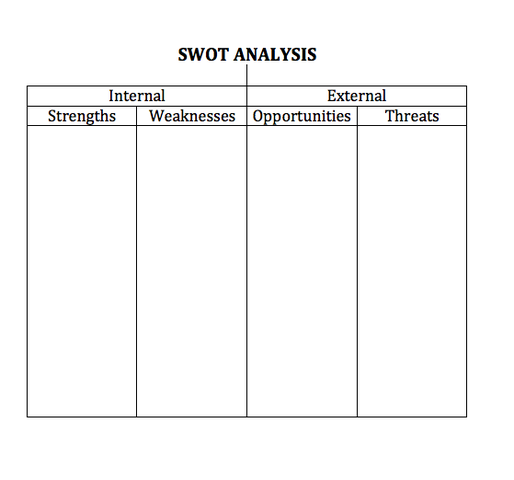
Once this is done, you’ll know that your messaging should emphasize the strengths and opportunities, and downplay or avoid the weaknesses and threats.
Or alternatively argue that the weaknesses and threats are really strengths and opportunities. (I’ve done this before.)
Method Two: Think before you create
Personally, I believe that a SWOT analysis is not enough. Before you use the SWOT findings to create content, there’s a little more work you have to do.
I recommend that before you create content, you should hold a kickoff of the content creation process and figure out what you want to do before you do it.
During that kickoff meeting, you should ask some questions to make sure you understand what needs to be done.
I’ve written about kickoffs and questions before, and I’m not going to repeat what I already said. If you want to know more:
- The Bredemarket post “Excuse me, but I have a lot of questions…” explains how I kick off an engagement with a client. Or at least how I kicked off engagements as of September 2021. I’ve tweaked the process a little bit since. But you get the general idea.
- The Bredemarket post and e-book “Six Questions Your Content Creator Should Ask You” explains the first six questions that I ask during a kickoff, and why I ask them. The first question, by the way, is “Why?”
Method Three: Send in the reinforcements

Now that you’ve locked down the messaging, it’s time to actually create the content that differentiates your identity firm from all the inferior identity firms in the market. While some companies can proceed right to content creation, others may run into one of two problems.
- The identity firm doesn’t have any knowledgeable writers on staff. To create the content, you need people who understand the identity industry, and who know how to write. Some firms lack people with this knowledge and capability.
- The identity firm has knowledgeable writers on staff, but they’re busy. Some companies have too many things to do at once, and any knowledgeable writers that are on staff may be unavailable due to other priorities.

This is where you supplement you identity firm’s existing staff with one or more knowledgeable writers who can work with you to create the content that leaves your inferior competitors in the dust.
What is next?

So do you need a knowledgeable biometric content marketing expert to create your content?
One who has been in the biometric industry for 29 years?
One who has been writing short and long form content for more than 29 years?
Are you getting tired of my repeated questions again?
Well then I’ll just tell you that Bredemarket is the answer to your identity/biometric content marketing needs.
Are you ready to take your identity firm to the next level with a compelling message that increases awareness, consideration, conversion, and long-term revenue? Let’s talk today!
- Email me at john.bredehoft@bredemarket.com.
- Book a meeting with me at calendly.com/bredemarket.
- Contact me at bredemarket.com/contact/.