This post concentrates on IDENTIFICATION perfection, or the ability to enjoy zero errors when identifying individuals.
The risk of claiming identification perfection (or any perfection) is that a SINGLE counter-example disproves the claim.
If you assert that your biometric solution offers 100% accuracy, a SINGLE false positive or false negative shatters the assertion.
If you claim that your presentation attack detection solution exposes deepfakes (face, voice, or other), then a SINGLE deepfake that gets past your solution disproves your claim.
And as for the pre-2009 claim that latent fingerprint examiners never make a mistake in an identification…well, ask Brandon Mayfield about that one.
In fact, I go so far as to avoid using the phrase “no two fingerprints are alike.” Many years ago (before 2009) in an International Association for Identification meeting, I heard someone justify the claim by saying, “We haven’t found a counter-example yet.” That doesn’t mean that we’ll NEVER find one.
At first glance, it appears that Motorola would be the last place to make a boneheaded mistake like that. After all, Motorola is known for its focus on quality.
But in actuality, Motorola was the perfect place to make such a mistake, since it was one of the champions of the “Six Sigma” philosophy (which targets a maximum of 3.4 defects per million opportunities). Motorola realized that manufacturing perfection is impossible, so manufacturers (and the people in Motorola’s weird Biometric Business Unit) should instead concentrate on reducing the error rate as much as possible.
So one misspelling could be tolerated, but I shudder to think what would have happened if I had misspelled “quality” a second time.
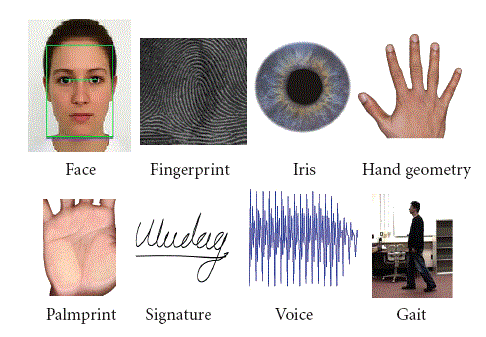
If you listen closely, you can hear about all sorts of wonderful biometric identifiers. They range from the common (such as fingerprint ridges and detail) to the esoteric (my favorite was the 2013 story about Japanese car seats that captured butt prints).
Forget about fingerprints and faces and irises and DNA and gait recognition and butt prints. Tongue prints are the answer!
Benefits of tongue print biometrics
To its credit, the article does point out two benefits of using tongue prints as a biometric identifier.
Consent and privacy. Unlike fingerprints and irises (and faces) which are always exposed and can conceivably be captured without the person’s knowledge, the subject has to provide consent before a tongue image is captured. For the most part, tongues are privacy-perfect.
Liveness. The article claims that “sticking out one’s tongue is an undeniable ‘proof of life.'” Perhaps that’s an exaggeration, but it is admittedly much harder to fake a tongue than it is to fake a finger or a face.
Are tongues unique?
But the article also makes these claims.
Two main attributes are measured for a tongue print. First is the tongue shape, as the shape of the tongue is unique to everyone.
The other notable feature is the texture of the tongue. Tongues consist of a number of ridges, wrinkles, seams and marks that are unique to every individual.
There is serious doubt (if not outright denial) that everyone has a unique face (although NIST is investigating this via the FRTE Twins Demonstration).
But at least these modalities are under study. Has anyone conducted a rigorous study to prove or disprove the uniqueness of tongues? By “rigorous,” I mean a study that has evaluated millions of tongues in the same way that NIST has evaluated millions of fingerprints, faces, and irises?
I did find this 2017 tongue identification pilot study but it only included a whopping 20 participants. And the study authors (who are always seeking funding anyway) admitted that “large-scale studies are required to validate the results.”
Conclusion
So if a police officer tells you to stick out your tongue for identification purposes, think twice.
I’ve talked about why NIST separated its FRVT efforts into FRTE and FATE.
But I haven’t talked bout how NIST did this.
And as you all know, the second most important question after why is how.
Why the great renaming took place
As I noted back in August, NIST chose to split its Face Recognition Vendor Test (FRVT) into two parts—FRTE (Face Recognition Technology Evaluation) and FATE (Face Analysis Technology Evaluation).
In essence, the Face Recognition Vendor Test had become a hodgepodge of different things. Some of the older tests were devoted to identification of individuals (face recognition), while some of the newer tests were looking at issues other than individual identification (face analysis).
Of course, this confusion between identification and non-identification is nothing new, which is why some of the people who read Gender Shades falsely concluded that if the three algorithms couldn’t classify people by sex or race, they couldn’t identify them as individuals.
But I digress. (I won’t do it again.)
NIST explained at the time:
Tracks that involve the processing and analysis of images will run under the FATE activity, and tracks that pertain to identity verification will run under FRTE.
To date, most of my personal attention (and probably most of yours) was paid to what was previously called FRVT 1:1 and FRVT 1:N.
These two tests are now part of FRTE, and were simply renamed to FRTE 1:1 and FRTE 1:N. They’ve even (for now) retained the same URLs, although that may change in the future.
Other tests that are now part of the FRTE bucket include:
The “Still Face and Iris 1:N Identification” effort (PDF) has apparently also been reclassified as an FRTE effort.
What is in FATE?
Obviously, presentation attack detection (PAD) testing falls into the FATE category, since this does not measure the identification of an individual, but whether a person is truly there or not. The first results have been released; I previously wrote about this here.
The next obvious category is age estimation testing, which again does not try to identify an individual, but estimate how old the person is. This testing has not yet started, but I talked about the concept of age estimation previously.
It is very possible that NIST will add additional FRTE and FATE tests in the future. These may be brand new tests, or variations of existing tests. For example, when all of us started wearing face masks a couple of years ago, NIST simulated face masks on its existing facial images and created the data for the face mask test described above.
What do you think NIST should test next, either in the FRTE or the FATE category?
More on morphing
And yes, I’m concluding this post with this video. By the way, this is the full version that (possibly intentionally) caused a ton of controversy and was immediately banned for nearly a quarter century. The morphing starts at 5:30. The crotch-grabbing starts right after the 7:00 mark.
Perhaps because of the lack of controversy with Godley & Creme’s earlier effort, Ashley Clark prefers it to the later Michael Jackson/John Landis effort.
Whereas Godley & Creme used editing technology to embrace and reflect the ambiguous murk of thwarted love, Jackson and Landis imposed an artificial sheen on the complexity of identity; a sheen that feels poignant if not outright tragic in the wake of Jackson’s ultimate appearance and fate. Really, it did matter if he was black or white.
One of the main application areas of facial morphing for criminal purposes is forging identity documents. The attack targets face-based identity verification systems and procedures. Most often it involves passports; however, any ID document with a photo can be compromised.
One well-known case happened in 2018 when a group of activists merged together a photo of Federica Mogherini, the High Representative of the European Union for Foreign Affairs and Security Policy, and a member of their group. Using this morphed photo, they managed to obtain an authentic German passport.
I mentioned something in passing in Bredemarket’s recent go-to-market post that I think needs a little more highlighting. So here is a deeper dive into the 22 types of content that product marketers create. (Well, at least 22. I’m probably missing some.)
And by the way, I have created all 22 of these types of content, from blog posts and battlecards to smartphone application content and scientific book chapters. And I can create it for you.
Why is it that so many business-to-business (B2B) marketers confuse product marketing with content marketing?
Because it requires a lot of discipline. That’s why.
B2B marketers who get it right understand the difference between these two fundamentally different types of marketing, what their purposes are and how to use them correctly.
Some firms (especially startups) don’t have the luxury to enforce such definitions. They don’t have separate teams to create awareness content, consideration content, and conversion content. They have one team (or perhaps one person) to create all that content PLUS other stuff that I’ll discuss later.
For example, during my most recent stint as a product marketing employee at a startup, the firm had no official content marketers, so the product marketers had to create a lot of non-product related content. So we product marketers were the de facto content marketers for the company too. (Sadly, we didn’t get two salaries for filling two roles.)
Why did the product marketers end up as content marketers? It turns out that it makes sense—after all, people who write about your product in the lower funnel stages can also write about your product in the upper funnel stages, and also can certainly write about OTHER things, such as company descriptions, speaker submissions, and speaker biographies.
As a result, I’ve written a ton of stuff over my last 29 years in identity/biometrics. It didn’t take a great leap for me to self-identify as the identity content marketing expert and the biometric content marketing expert (and other expert definitions; I’m an expert in creating expert titles).
I’ve compiled a summary of the types of content that I’ve created over the years, not only for Bredemarket’s clients, but also for my employers at Incode Technologies, IDEMIA, MorphoTrak, Motorola, and Printrak.
Not all of these were created when I was in a formal product marketing role, but depending upon your product or service, you may need any of these content types to support the marketing of your product/service.
It’s helpful to divide the list into two parts: the external (customer-facing) content, and the internal (company-only) content.
10 types of external content I have created
External content is what most people think of when they talk about product marketing or content marketing. After all, this is the visible stuff that the prospects see, and which can move them toward a purchase (conversion). The numbers after some content types indicate the quantities of pieces of collateral that I have created.
Articles
Blog Posts (500+, including this one)
Briefs/Data/Literature Sheets
Case Studies (12+)
Proposals (100+)
Scientific Book Chapters
Smartphone Application Content
Social Media (Facebook, Instagram, LinkedIn, Threads, TikTok, Twitter)
Web Page Content
White Papers and E-Books
Here’s an video showing some of the external content that I have created for Bredemarket.
While external content is sexy, internal content is extremely important, since it’s what equips the people inside a firm to promote your product or service. The numbers after some content types indicate the quantities of pieces of collateral that I have created.
Battlecards (80+)
Competitive Analyses
Event/Conference/Trade Show Demonstration Scripts
Plans
Playbooks
Proposal Templates
Quality Improvement Documents
Requirements
Strategic Analyses
And here are 3 more types
Some content can either be external or internal. Again, numbers indicate the quantities of pieces of collateral I have created.
Email Newsletters (200+)
FAQs
Presentations
Content I can create for you
Does your firm need help creating one of these types of content?
Maybe two?
Maybe 22?
I can create content full-time for you
If your firm needs to create a lot of content types for your products, then consider hiring me as your full-time Senior Product Marketing Manager. My LinkedIn profile is here, documenting my 29 years of experience in identity/biometric technology as a product marketer, a strategist, and in other roles.
(D)igital security engineers at the University of Wisconsin–Madison have found these systems are not quite as foolproof when it comes to a novel analog attack. They found that speaking through customized PVC pipes — the type found at most hardware stores — can trick machine learning algorithms that support automatic speaker identification systems.
The project began when the team began probing automatic speaker identification systems for weaknesses. When they spoke clearly, the models behaved as advertised. But when they spoke through their hands or talked into a box instead of speaking clearly, the models did not behave as expected.
(Shimaa) Ahmed investigated whether it was possible to alter the resonance, or specific frequency vibrations, of a voice to defeat the security system. Because her work began while she was stuck at home due to COVID-19, Ahmed began by speaking through paper towel tubes to test the idea. Later, after returning to the lab, the group hired Yash Wani, then an undergraduate and now a PhD student, to help modify PVC pipes at the UW Makerspace. Using various diameters of pipe purchased at a local hardware store, Ahmed, Yani and their team altered the length and diameter of the pipes until they could produce the same resonance as they voice they were attempting to imitate.
Eventually, the team developed an algorithm that can calculate the PVC pipe dimensions needed to transform the resonance of almost any voice to imitate another. In fact, the researchers successfully fooled the security systems with the PVC tube attack 60 percent of the time in a test set of 91 voices, while unaltered human impersonators were able to fool the systems only 6 percent of the time.
We evaluate two state-of-the-art ASI models: (1) the x-vector network [51] implemented by Shamsabadi et al. [45], and (2) the emphasized channel attention, propagation and aggregation time delay neural network (ECAPATDNN) [17], implemented by SpeechBrain.1 Both models were trained on VoxCeleb dataset [15, 36, 37], a benchmark dataset for ASI. The x-vector network is trained on 250 speakers using 8 kHz sampling rate. ECAPA-TDNN is trained on 7205 speakers using 16 kHz sampling rate. Both models report a test accuracy within 98-99%.
So what we know is that this test, which used these two ASI models trained on a particular dataset, demonstrated an ability to fool systems 60 percent of the time.
But…
What does this mean for other ASI algorithms, including the commercial algorithms in use today?
And what does it mean when other datasets are used?
In other words (and I’m adapting my own text here), how do the results of this study affect “current automatic speaker identification products”?
The answer is “We don’t know.”
So pipe down…until we actually test commercial algorithms for this technique.
But I’m sure that the UW-Madison researchers and I agree on one thing: more research is needed.
I know that I’m the guy who likes to say that it’s all semantics. After all, I’m the person who has referred to five-page long documents as “battlecards.”
But sometimes the semantics are critically important. Take the terms “factors” and “modalities.” On the surface they sound similar, but in practice there is an extremely important difference between factors of authentication and modalities of authentication. Let’s discuss.
What is a factor?
To answer the question “what is a factor,” let me steal from something I wrote back in 2021 called “The five authentication factors.”
Something You Know. Think “password.” And no, passwords aren’t dead. But the use of your mother’s maiden name as an authentication factor is hopefully decreasing.
Something You Have. I’ve spent much of the last ten years working with this factor, primarily in the form of driver’s licenses. (Yes, MorphoTrak proposed driver’s license systems. No, they eventually stopped doing so. But obviously IDEMIA North America, the former MorphoTrust, has implemented a number of driver’s license systems.) But there are other examples, such as hardware or software tokens.
Something You Are. I’ve spent…a long time with this factor, since this is the factor that includes biometrics modalities (finger, face, iris, DNA, voice, vein, etc.). It also includes behavioral biometrics, provided that they are truly behavioral and relatively static.
Something You Do. The Cybersecurity Man chose to explain this in a non-behavioral fashion, such as using swiping patterns to unlock a device. This is different from something such as gait recognition, which supposedly remains constant and is thus classified as behavioral biometrics.
Somewhere You Are. This is an emerging factor, as smartphones become more and more prevalent and locations are therefore easier to capture. Even then, however, precision isn’t always as good as we want it to be. For example, when you and a few hundred of your closest friends have illegally entered the U.S. Capitol, you can’t use geolocation alone to determine who exactly is in Speaker Pelosi’s office.
(By the way, if you search the series of tubes for reading material on authentication factors, you’ll find a lot of references to only three authentication factors, including references from some very respectable sources. Those sources are only 60% right, since they leave off the final two factors I listed above. It’s five factors of authentication, folks. Maybe.)
The one striking thing about the five factors is that while they can all be used to authenticate (and verify) identities, they are inherently different from one another. The ridges of my fingerprint bear no relation to my 16 character password, nor do they bear any relation to my driver’s license. These differences are critical, as we shall see.
What is a modality?
In identity usage, a modality refers to different variations of the same factor. This is most commonly used with the “something you are” (biometric) factor, but it doesn’t have to be.
[M]any businesses and individuals (are adopting) biometric authentication as it been established as the most secure authentication method surpassing passwords and pins. There are many modalities of biometric authentication to pick from, but which method is the best?
After looking at fingerprints, faces, voices, and irises, Aware basically answered its “best” question by concluding “it depends.” Different modalities have their own strengths and weaknesses, depending upon the use case. (If you wear thick gloves as part of your daily work, forget about fingerprints.)
ID R&D goes a step further and argues that it’s best to use multimodal biometrics, in which the two biometrics are face and voice. (By an amazing coincidence, ID R&D offers face and voice solutions.)
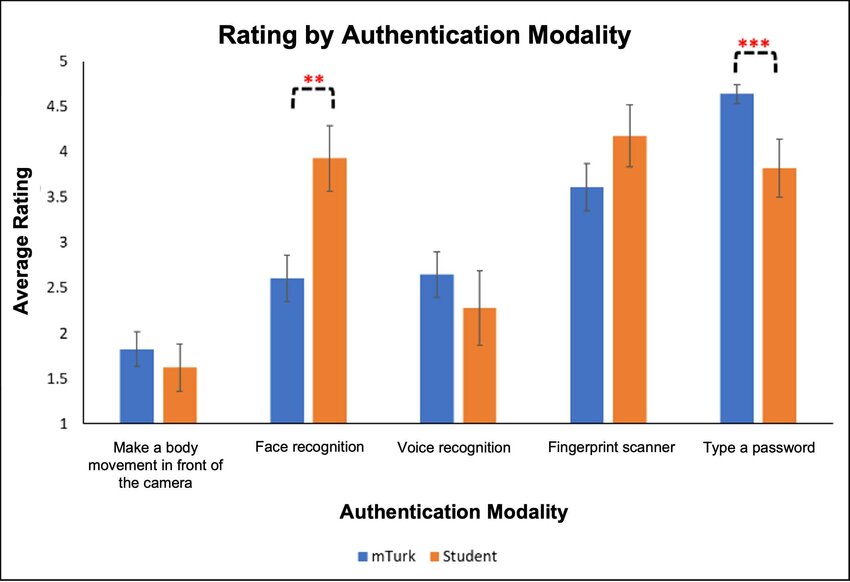
The three modalities in the middle—face, voice, and fingerprint—are all clearly biometric “something you are” modalities.
But the modality on the left, “Make a body movement in front of the camera,” is not a biometric modality (despite its reference to the body), but is an example of “something you do.”
Passwords, of course, are “something you know.”
In fact, each authentication factor has multiple modalities.
For example, a few of the modalities associated with “something you have” include driver’s licenses, passports, hardware tokens, and even smartphones.
Why multifactor is (usually) more robust than multimodal
Modalities within a single authentication factor are more closely related than modalities within multiple authentication factors. As I mentioned above when talking about factors, there is no relationship between my fingerprint, my password, and my driver’s license. However, there is SOME relationship between my driver’s license and my passport, since the two share some common information such as my legal name and my date of birth.
What does this mean?
If I’ve fraudulently created a fake driver’s license in your name, I already have some of the information that I need to create a fake passport in your name.
If I’ve fraudulently created a fake iris, there’s a chance that I might already have some of the information that I need to create a fake face.
However, if I’ve bought your Coinbase password on the dark web, that doesn’t necessarily mean that I was able to also buy your passport information on the dark web (although it is possible).
Can an identity content marketing expert help you navigate these issues?
As you can see, you need to be very careful when writing about modalities and factors.
You need a biometric content marketing expert who has worked with many of these modalities.
Actually, you need an identity content marketing expert who has worked with many of these factors.
So if you are with an identity company and need to write a blog post, LinkedIn article, white paper, or other piece of content that touches on multifactor and multimodal issues, why not engage with Bredemarket to help you out?
If you’re interested in receiving my help with your identity written content, contact me.
Iris recognition continues to make the news. Let’s review what iris recognition is and its benefits (and drawbacks), why Apple made the news last month, and why Worldcoin is making the news this month.
What is iris recognition?
There are a number of biometric modalities that can identify individuals by “who they are” (one of the five factors of authentication). A few examples include fingerprints, faces, voices, and DNA. All of these modalities purport to uniquely (or nearly uniquely) identify an individual.
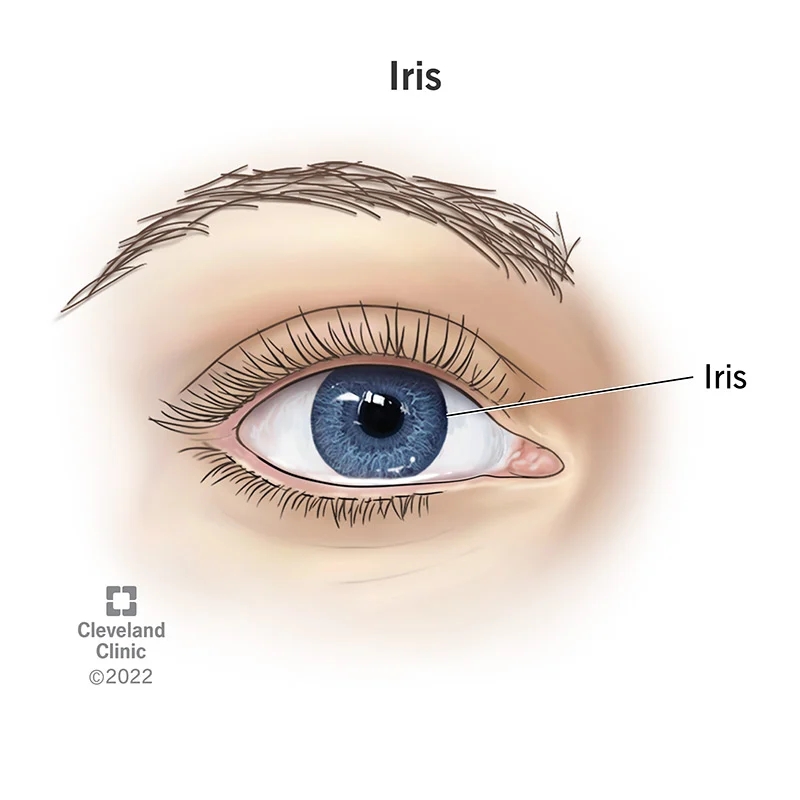
One other way to identify individuals is via the irises in their eyes. I’m not a doctor, but presumably the Cleveland Clinic employs medical professionals who are qualified to define what the iris is.
The iris is the colored part of your eye. Muscles in your iris control your pupil — the small black opening that lets light into your eye.
But why use irises rather than, say, fingerprints and faces? The best person to answer this is John Daugman. (At this point several of you are intoning, “John Daugman.” With reason. He’s the inventor of iris recognition.)
(I)ris patterns become interesting as an alternative approach to reliable visual recognition of persons when imaging can be done at distances of less than a meter, and especially when there is a need to search very large databases without incurring any false matches despite a huge number of possibilities. Although small (11 mm) and sometimes problematic to image, the iris has the great mathematical advantage that its pattern variability among different persons is enormous.
Daugman, John, “How Iris Recognition Works.” IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 1, JANUARY 2004. Quoted from page 21. (PDF)
Or in non-scientific speak, one benefit of iris recognition is that you know it is accurate, even when submitting a pair of irises in a one-to-many search against a huge database. How huge? We’ll discuss later.
Brandon Mayfield and fingerprints
Remember that Daugman’s paper was released roughly two months before Brandon Mayfield was misidentified in a fingerprint comparison. (Everyone now intone “Brandon Mayfield.”)
While some of the issues associated with Mayfield’s misidentification had nothing to do with forensic science (Al Jazeera spends some time discussing bias, and Itiel Dror also looked at bias post-Mayfield), this still shows that fingerprints are remarkably similar and that it takes care to properly identify people.
Police agencies, witnesses, and faces
And of course there are recent examples of facial misidentifications (both by police agencies and witnesses), again not necessarily forensic science related, and again showing the similarity of faces from two different people.
At the root of iris recognition’s accuracy is the data-richness of the iris itself. The IrisAccess system captures over 240 degrees of freedom or unique characteristics in formulating its algorithmic template. Fingerprints, facial recognition and hand geometry have far less detailed input in template construction.
Enough about claims. What about real results? The IREX 10 test, independently administered by the U.S. National Institute of Standards and Technology, measures the identification (one-to-many) accuracy of submitted algorithms. At the time I am writing this, the ten most accurate algorithms provide false negative identification rates (FNIR) between 0.0022 ± 0.0004 and 0.0037 ± 0.0005 when two eyes are used. (Single eye accuracy is lower.) By the time you see this, the top ten algorithms may have changed, because the vendors are always improving.
IREX10 two-eye accuracy, top ten algorithms as of July 28, 2023. (Link)
While the IREX10 one-to-many tests are conducted against databases of less than a million records, it is estimated that iris one-to-many accuracy remains high even with databases of a billion people—something we will return to later in this post.
Iris drawbacks
OK, so if irises are so accurate, why aren’t we dumping our fingerprint readers and face readers and just using irises?
In short, because of the high friction in capturing irises. You can use high-resolution cameras to capture fingerprints and faces from far away, but as of now iris capture usually requires you to get very close to the capture device.
Iris image capture circa 2020 from the U.S. Federal Bureau of Investigation. (Link)
Which I guess is better than the old days when you had to put your eye right up against the capture device, but it’s still not as friendly (or intrusive) as face capture, which can be achieved as you’re walking down a passageway in an airport or sports stadium.
Irises and Apple Vision Pro
So how are irises being used today? You may or may not have hard last month’s hoopla about the Apple Vision Pro, which uses irises for one-to-one authetication.
I’m not going to spend a ton of time delving into this, because I just discussed Apple Vision Pro in June. In fact, I’m just going to quote from what I already said.
In short, as you wear the headset (which by definition is right on your head, not far away), the headset captures your iris images and uses them to authenticate you.
It’s a one-to-one comparison, not the one-to-many comparison that I discussed earlier in this post, but it is used to uniquely identify an individual.
But iris recognition doesn’t have to be used for identification.
Irises and Worldcoin
“But wait a minute, John,” you’re saying. “If you’re not using irises to determine if a person is who they say they are, then why would anyone use irises?”
Over the past several years, I’ve analyzed a variety of identity firms. Earlier this year I took a look at Worldcoin….Worldcoin’s World ID emphasizes privacy so much that it does not conclusively prove a person’s identity (it only proves a person’s uniqueness)…
That’s the only thing that I’ve said about Worldcoin, at least publicly. (I looked at Worldcoin privately earlier in 2023, but that report is not publicly accessible and even I don’t have it any more.)
The Worldcoin Foundation today announced that Worldcoin, a project co-founded by Sam Altman, Alex Blania and Max Novendstern, is now live and in a production-grade state.
The launch includes the release of the World ID SDK and plans to scale Orb operations to 35+ cities across 20+ countries around the world. In tandem, the Foundation’s subsidiary, World Assets Ltd., minted and released the Worldcoin token (WLD) to the millions of eligible people who participated in the beta; WLD is now transactable on the blockchain….
“In the age of AI, the need for proof of personhood is no longer a topic of serious debate; instead, the critical question is whether or not the proof of personhood solutions we have can be privacy-first, decentralized and maximally inclusive,” said Worldcoin co-founder and Tools for Humanity CEO Alex Blania. “Through its unique technology, Worldcoin aims to provide anyone in the world, regardless of background, geography or income, access to the growing digital and global economy in a privacy preserving and decentralized way.”
Worldcoin does NOT positively identify people…but it can still pay you
A very important note: Worldcoin’s purpose is not to determine identity (that a person is who they say they are). Worldcoin’s purpose is to determine uniqueness: namely, that a person (whoever they are) is unique among all the billions of people in the world. Once uniqueness is determined, the person can get money money money with an assurance that the same person won’t get money twice.
Iris biometrics outperform other biometric modalities and already achieved false match rates beyond 1.2× 10−141.2×10−14 (one false match in one trillion[9]) two decades ago[10]—even without recent advancements in AI. This is several orders of magnitude more accurate than the current state of the art in face recognition.
I remember the day that my car skidded down Monterey Pass Road in Monterey Park, California, upside down, my seatbelt saving my brain from…um…very bad things. (I promised myself that I’d make this post NON-gory.)
I was returning from lunch to my employer farther south on Monterey Pass Road when a car hit me from the side, flipping my car over so that it skidded down Monterey Pass Road, upside down. Only my seat belt saved my from certain death.
Now some of you who know me are asking, “John, you’ve lived in Ontario and Upland for the past several decades. Why were you 30 miles away, in Monterey Park?”
Well, back in 1991, after working for Rancho Cucamonga companies for several years, I ended up commuting to a company in Monterey Park, California, at least an hour’s drive one way from my home. Driving toward downtown Los Angeles in the morning, and away from downtown Los Angeles in the afternoon. If you know, you know.
After I left the Monterey Park company, I consulted or worked for companies in Pomona, Brea, Anaheim, Irvine, and other cities. But for most of the next three decades, I was still driving at least an hour one-way every day to get from home to work.
As I’ll note later in this post, some people are still commuting today. And for all I know I may commute again also.
I learn the acronym WFH
That all stopped in March 2020 when a worldwide pandemic sent all non-essential personnel at IDEMIA’s Anaheim office to work from home (WFH). Now there were some IDEMIA employees, such as salespeople, who had been working from home for years, but this was the first time that a whole bunch of us were doing it.
Some of us had to upgrade our home equipment: mesh networks, special face illumination lighting, and other things. And now, instead of having a couple of people participating in meetings remotely, ALL of us were doing so. (Before 2020, the two words “Zoom background” would be incomprehensible to me. After 2020, I understood those words intimately.)
This new work practice continued after I left IDEMIA, as I started Bredemarket, joined Incode Technologies for a little over a year, and returned (for now) to Bredemarket again.
The U.S. Marine Corps supported WFH (for certain positions) in 2010, long before COVID. This image was released by the United States Marine Corps with the ID 100324-M-6847A-001 (next). This tag does not indicate the copyright status of the attached work. A normal copyright tag is still required. See Commons:Licensing.العربية ∙ বাংলা ∙ Deutsch ∙ Deutsch (Sie-Form) ∙ English ∙ español ∙ euskara ∙ فارسی ∙ français ∙ italiano ∙ 日本語 ∙ 한국어 ∙ македонски ∙ മലയാളം ∙ Plattdüütsch ∙ Nederlands ∙ polski ∙ پښتو ∙ português ∙ slovenščina ∙ svenska ∙ Türkçe ∙ українська ∙ 简体中文 ∙ 繁體中文 ∙ +/−, Public Domain, https://commons.wikimedia.org/w/index.php?curid=23181833
WFH benefits
There are two benefits to working from home:
First, it preserves your brain. Not just from the horrible results of a commuting automobile accident. For the last three-plus years, I’ve gotten more rest and sleep since I’m not waking up before 6am and getting home after 6pm. And I’m not sitting in traffic on the 57, waiting for an accident to clear.
Second, it provides the best talent to your employer. Why? Because it can hire you. I just spent over a year working for a company headquartered in San Francisco, and I didn’t have to move to San Francisco to do it. In fact, when my product marketing team reached its apex, we had two people in Southern California, one in England, and one in Sweden. None of us had to move to San Francisco to work there, and my company was not restricted to hiring people who could get to San Francisco every day.
But that doesn’t stop some companies from insisting on office work
In-office presence controversy predates COVID (remember Marissa Mayer and Yahoo?), and now that COVID has receded, the “return to office” drumbeat has gotten louder.
Now I’m not saying I’ll never work on-site again. Maybe someday I’ll even accept an on-site position in Monterey Park.
But I’m not that thrilled about going down Monterey Pass Road again.
In the meantime…
…since I’m NOT full-time employed, and since my home office is well equipped (I have Nespresso!), I have the time to make YOUR company’s messaging better.
If you can use Bredemarket’s expertise for your biometric, identity, technology, or general blog posts, case studies, white papers, or other written content, contact me.
I’ll admit that I previously thought that age estimation was worthless, but I’ve since changed my mind about the necessity for it. Which is a good thing, because the U.S. National Institute of Standards and Technology (NIST) is about to add age estimation to its Face Recognition Vendor Test suite.
What is age estimation?
Before continuing, I should note that age estimation is not a way to identify people, but a way to classify people. For once, I’m stepping out of my preferred identity environment and looking at a classification question. Not “gender shades,” but “get off my lawn” (or my tricycle).
Age estimation uses facial features to estimate how old a person is, in the absence of any other information such as a birth certificate. In a Yoti white paper that I’ll discuss in a minute, the Western world has two primary use cases for age estimation:
First, to estimate whether a person is over or under the age of 18 years. In many Western countries, the age of 18 is a significant age that grants many privileges. In my own state of California, you have to be 18 years old to vote, join the military without parental consent, marry (and legally have sex), get a tattoo, play the lottery, enter into binding contracts, sue or be sued, or take on a number of other responsibilities. Therefore, there is a pressing interest to know whether the person at the U.S. Army Recruiting Center, a tattoo parlor, or the lottery window is entitled to use the service.
Second, to estimate whether a person is over or under the age of 13 years. Although age 13 is not as great a milestone as age 18, this is usually the age at which social media companies allow people to open accounts. Thus the social media companies and other companies that cater to teens have a pressing interest to know the teen’s age.
Why was I against age estimation?
Because I felt it was better to know an age, rather than estimate it.
My opinion was obviously influenced by my professional background. When IDEMIA was formed in 2017, I became part of a company that produced government-issued driver’s licenses for the majority of states in the United States. (OK, MorphoTrak was previously contracted to produce driver’s licenses for North Carolina, but…that didn’t last.)
With a driver’s license, you know the age of the person and don’t have to estimate anything.
And estimation is not an exact science. Here’s what Yoti’s March 2023 white paper says about age estimation accuracy:
Our True Positive Rate (TPR) for 13-17 year olds being correctly estimated as under 25 is 99.93% and there is no discernible bias across gender or skin tone. The TPRs for female and male 13-17 year olds are 99.90% and 99.94% respectively. The TPRs for skin tone 1, 2 and 3 are 99.93%, 99.89% and 99.92% respectively. This gives regulators globally a very high level of confidence that children will not be able to access adult content.
Our TPR for 6-11 year olds being correctly estimated as under 13 is 98.35%. The TPRs for female and male 6-11 year olds are 98.00% and 98.71% respectively. The TPRs for skin tone 1, 2 and 3 are 97.88%, 99.24% and 98.18% respectively so there is no material bias in this age group either.
Yoti’s facial age estimation is performed by a ‘neural network’, trained to be able to estimate human age by analysing a person’s face. Our technology is accurate for 6 to 12 year olds, with a mean absolute error (MAE) of 1.3 years, and of 1.4 years for 13 to 17 year olds. These are the two age ranges regulators focus upon to ensure that under 13s and 18s do not have access to age restricted goods and services.
While this is admirable, is it precise enough to comply with government regulations? Mean absolute errors of over a year don’t mean a hill of beans. By the letter of the law, if you are 17 years and 364 days old and you try to vote, you are breaking the law.
Why did I change my mind?
Over the last couple of months I’ve thought about this a bit more and have experienced a Jim Bakker “I was wrong” moment.
How many 13 year olds do you know that have driver’s licenses? Probably none.
How many 13 year olds do you know that have government-issued REAL IDs? Probably very few.
How many 13 year olds do you know that have passports? Maybe a few more (especially after 9/11), but not that many.
Even at age 18, there is no guarantee that a person will have a government-issued REAL ID.
So how are 18 year olds, or 13 year olds, supposed to prove that they are old enough for services? Carry their birth certificate around?
You’ll note that Yoti didn’t target a use case for 21 year olds. This is partially because Yoti is a UK firm and therefore may not focus on the strict U.S. laws regarding alcohol, tobacco, and casino gambling. But it’s also because it’s much, much more likely that a 21 year old will have a government-issued ID, eliminating the need for age estimation.
Sometimes.
In some parts of the world, no one has government IDs
Over the past several years, I’ve analyzed a variety of identity firms. Earlier this year I took a look at Worldcoin. While Worldcoin’s World ID emphasizes privacy so much that it does not conclusively prove a person’s identity (it only proves a person’s uniqueness), and makes no attempt to provide the age of the person with the World ID, Worldcoin does have something to say about government issued IDs.
Online services often request proof of ID (usually a passport or driver’s license) to comply with Know your Customer (KYC) regulations. In theory, this could be used to deduplicate individuals globally, but it fails in practice for several reasons.
KYC services are simply not inclusive on a global scale; more than 50% of the global population does not have an ID that can be verified digitally.
IDs are issued by states and national governments, with no global system for verification or accountability. Many verification services (i.e. KYC providers) rely on data from credit bureaus that is accumulated over time, hence stale, without the means to verify its authenticity with the issuing authority (i.e. governments), as there are often no APIs available. Fake IDs, as well as real data to create them, are easily available on the black market. Additionally, due to their centralized nature, corruption at the level of the issuing and verification organizations cannot be eliminated.
Same source as above.
Now this (in my opinion) doesn’t make the case for Worldcoin, but it certainly casts some doubt on a universal way to document ages.
So we’d better start measuring the accuracy of age estimation.
If only there were an independent organization that could measure age estimation, in the same way that NIST measures the accuracy of fingerprint, face, and iris identification.
You know where this is going.
How will NIST test age estimation?
Yes, NIST is in the process of incorporating an age estimation test in its battery of Face Recognition Vendor Tests.
Facial age verification has recently been mandated in legislation in a number of jurisdictions. These laws are typically intended to protect minors from various harms by verifying that the individual is above a certain age. Less commonly some applications extend benefits to groups below a certain age. Further use-cases seek only to determine actual age. The mechanism for estimating age is usually not specified in legislation. Face analysis using software is one approach, and is attractive when a photograph is available or can be captured.
In 2014, NIST published a NISTIR 7995 on Performance of Automated Age Estimation. The report showed using a database with 6 million images, the most accurate age estimation algorithm have accurately estimated 67% of the age of a person in the images within five years of their actual age, with a mean absolute error (MAE) of 4.3 years. Since then, more research has dedicated to further improve the accuracy in facial age verification.
Note that this was in 2014. As we have seen above, Yoti asserts a dramatically lower error rate in 2023.
NIST is just ramping up the testing right now, but once it moves forward, it will be possible to compare age estimation accuracy of various algorithms, presumably in multiple scenarios.
Well, for those algorithm providers who choose to participate.
Does your firm need to promote its age estimation solution?
Does your company have an age estimation solution that is superior to all others?
Do you need an experienced identity professional to help you spread the word about your solution?
(UPDATE OCTOBER 23, 2023: “SIX QUESTIONS YOUR CONTENT CREATOR SHOULD ASK YOU IS SO 2022. DOWNLOAD THE NEWER “SEVEN QUESTIONS YOUR CONTENT CREATOR SHOULD ASK YOU” HERE.)
But since you care about YOUR self-promotion rather than mine, I’ll provide three tips for writing and promoting your own LinkedIn post.
How I promoted my content
Before I wrote the blog post or the LinkedIn post, I used my six questions to guide me. For my specific example, here are the questions and the answers.
Question
Primary Answer
Secondary Answer (if applicable)
Why?
I want full-time employment
I want consulting work
How?
State identity and marketing qualifications, ask employers to hire me
State identity and marketing qualifications, ask consulting clients to contract with me
What?
Blog post (jebredcal), promoted by a personal LinkedIn post
Blog post (jebredcal), promoted by a Bredemarket Identity Firm Services LinkedIn post
You’ll notice that I immediately broke a cardinal rule by having both a primary goal and a secondary goal. When you perform your own self-promotion, you will probably want to make things less messy by having only a single goal.
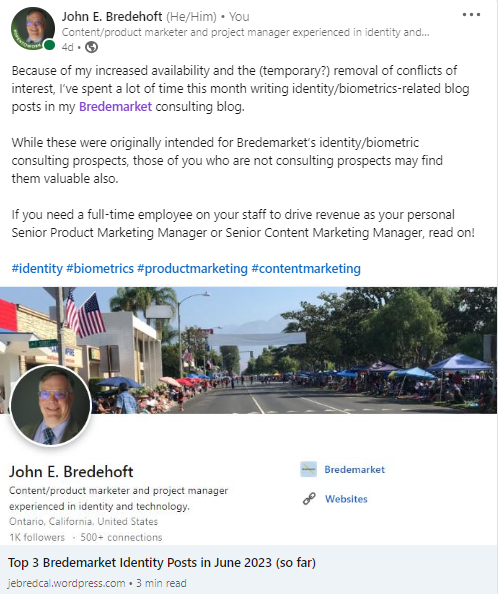
After the introduction (pictured above) with its “If you need a full-time employee” call to action, I then shared three identity-related blog posts from the Bredemarket blog to establish my “biometric content marketing expert” (and “identity content marketing expert”) credentials. I then closed with a dual call to action for employers and potential consulting clients. (I told you it is messy to have two goals.)
If you want to see my jebredcal post “Top 3 Bredemarket Identity Posts in June 2023 (so far),” click here.
So how did I get the word out about this personal blog post? I chose LinkedIn. (In my case, hiring managers probably aren’t going to check my two Instagram accounts.)
It was simple to write the LinkedIn text, since I repurposed the introduction of the blog post itself. I added four hashtags, and then the post went live. You can see it here.
And by the way, feel free to like the LinkedIn post, comment on it, or even reshare it. I’ll explain why below.
Third, the “LinkedIn Love” promotion
So how did I promote it? Via the “LinkedIn Love” concept. (Some of you know where I learned about LinkedIn Love.)
To get LinkedIn love, I asked a few trusted friends in the identity industry to like, comment, or reshare the post. This places the post on my friends’ feeds, where their identity contacts will see it.
A few comments:
I don’t do this for every post, or else I will have no friends. In fact, this is the first time that I’ve employed “LinkedIn Love” in months.
I only asked friends in the identity industry, since these friends have followers who are most likely to hire a Senior Product Marketing Manager or Senior Content Marketing Manager.
I only asked a few friends in the identity industry, although eventually some friends that I didn’t ask ended up engaging with the post anyway.
I have wonderful friends. After several of them gave “LinkedIn Love,” The post received significant engagement. As of Friday morning, the post had acquired over 1,700 impresions. That’s many, many more than my posts usually acquire.
I don’t know if this activity will directly result in full-time employment or increased consulting work. But it certainly won’t hurt.
Three steps to promote YOUR content
But the point of this post isn’t MY job search. It’s YOURS (or whatever it is you want to promote).
For example, one of my friends who is also seeking full-time employment wanted to know how to use a LinkedIn post to promote THEIR OWN job search.
Now you don’t need to use my six questions. You don’t need to create a blog post before creating the LinkedIn post. And you certainly don’t need to create two goals. (Please don’t…unless you want to.)
In fact, you can create and promote your own LinkedIn post in just THREE steps.
Step One: What do you want to say?
My six questions obviously aren’t the only method to collect your thoughts. There are many, many other tools that achieve the same purpose. The important thing is to figure out what you want to say.
Start at the end. What action do you want the reader to take after reading your LinkedIn post? Do you want them to read your LinkedIn profile, or download your resume, or watch your video, or join your mailing list, or email or call you? Whatever it is, make sure your LinkedIn post includes the appropriate “call to action.”
Work on the rest. Now that you know how your post will end, you can work on the rest of the post. Persuade your reader to follow your call to action. Explain how you will benefit them. Address the post to the reader, your customer (for example, a potential employer), and adopt a customer focus.
Step Two: Say it.
If you don’t want to write the post yourself, then ask a consultant, a friend, or even a generative AI tool to write something for you. (Just because I’m a “get off my lawn” guy regarding generative AI doesn’t mean that you have to be.)
(And before you ask, there are better consultants than Bredemarket for THIS writing job. My services are designed and priced for businesses, not individuals.)
After your post is written by you or someone (or something) else, have one of your trusted friends review it and see if the written words truly reflect how amazing and outstanding you are.
Once you’re ready, post it to LinkedIn. Don’t delay, even if it isn’t perfect. (Heaven knows this blog post isn’t perfect, but I posted it anyway.) Remember that if you don’t post your promotional LinkedIn post, you are guaranteed to get a 0% response to it.
Step Three: Promote it.
Your trusted friends will come in handy for the promotion part—if they have LinkedIn accounts. Privately ask your trusted friends to apply “LinkedIn Love” to your post in the same way that my trusted friends did it for me.
By the way—if I know you, and you’d like me to promote your LinkedIn post, contact me via LinkedIn (or one of the avenues on the Bredemarket contact page) and I’ll do what I can.
And even if I DON’T know you, I can promote it anyway.
I’ve never met Mary Smith in my life, but she says that she read my Bredemarket blog post “Applying the “Six Questions” to LinkedIn Self-promotion.” Because she selects such high-quality reading material, I’m resharing Mary’s post about how she wants to be the first human to visit Venus. If you can help her realize her dream, scroll to the bottom of her post and donate to her GoFundMe.
Hey, whatever it takes to get the word out.
Let me know if you use my tips…or if you have better ways to achieve the same purpose.