Not enough attention is paid to the critical importance of zip codes for U.S. tech product marketing job applicants. Identity experts know that geolocation can serve as one of the five factors of authentication. But geolocation (via zip code) can also serve as a factor of disqualification.
This video doesn’t directly have to do with Bredemarket—my clients ARE remote-friendly—but since it involves my status as a biometric product marketing expert I thought I’d share it here.
For more detail, see my LinkedIn post from earlier this morning.
In my circles, people generally understand ‘biometrics’ to refer to one of several ways to identify an individual.
But for the folks at Merriam-Webster, this is only a secondary definition of the word “biometrics.” From their perspective, biometrics is primarily biometry, which can refer to “the statistical analysis of biological observations and phenomena” or to “measurement (as by ultrasound or MRI) of living tissue or bodily structures.” In other words, someone’s health, not someone’s identity.
Fun fact: if you go to the International Biometric Society and ask it for its opinion on the most recent FRVT 1:N tests, it won’t have an answer for you.
So Abbott salespeople, real or imagined, won’t be interested in what I’ve been doing for the last 30 years. ‘Cause you know sometimes words have two meanings.
But those of you who use biometrics (and other factors) for individualization WILL be interested. Click on the image to find out more.
Drive content results with Bredemarket Identity Firm Services.
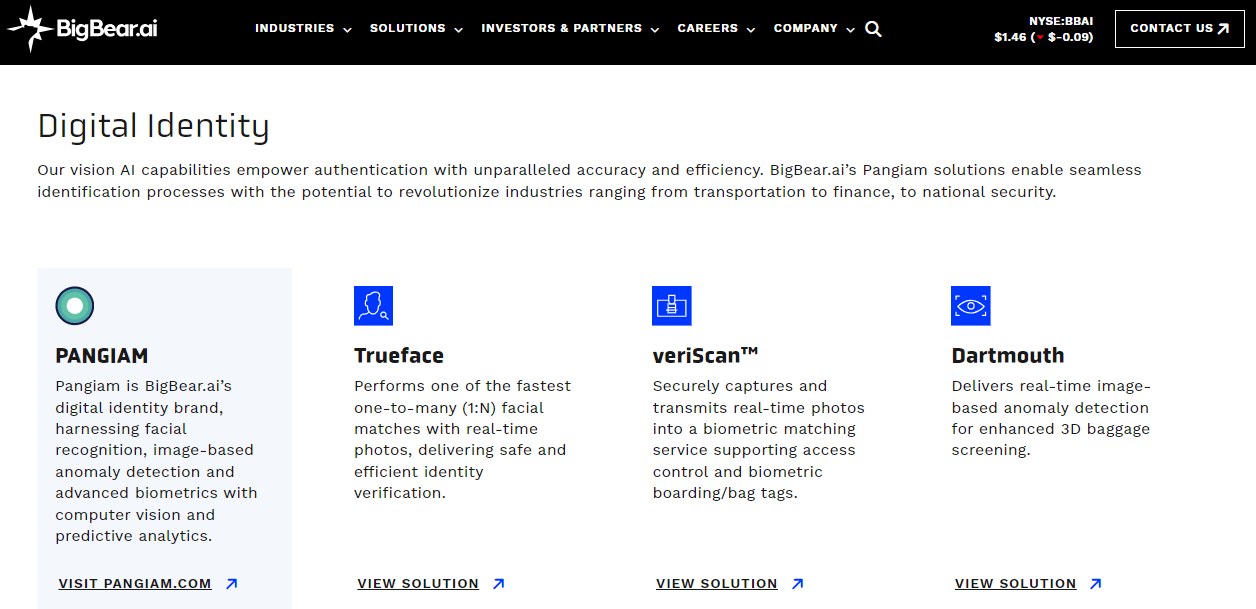
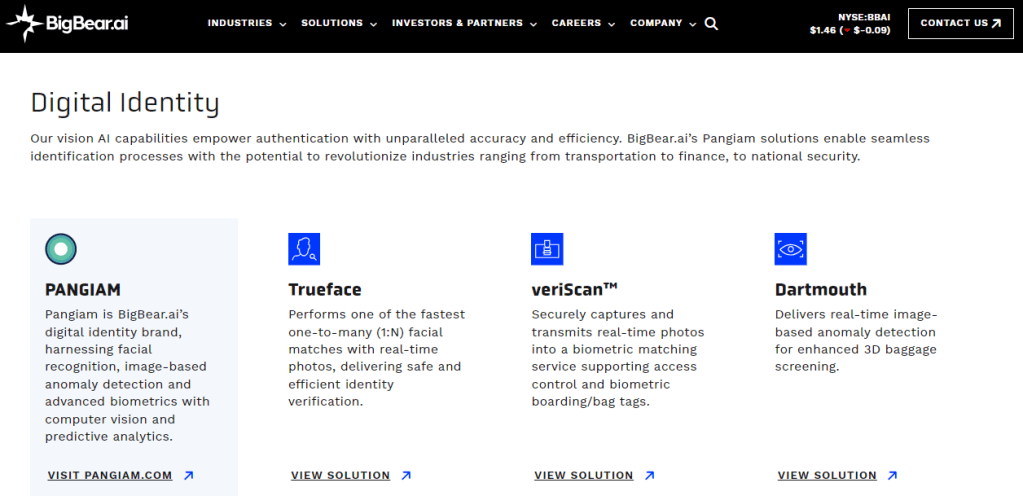
Pangiam is BigBear.ai’s digital identity brand, harnessing facial recognition, image-based anomaly detection and advanced biometrics with computer vision and predictive analytics.
Trueface Performs one of the fastest one-to-many (1:N) facial matches with real-time photos, delivering safe and efficient identity verification.
veriScan™ Securely captures and transmits real-time photos into a biometric matching service supporting access control and biometric boarding/bag tags.
Dartmouth Delivers real-time image-based anomaly detection for enhanced 3D baggage screening.
All these products, including Dartmouth, were developed before the BigBear.ai acquisition. (Where is Pangiam Bridge?)
Go-to-market initiatives have ONLY two audiences: the external prospects who are the hungry people (hopefully) wanting the product, and the internal staff in the company who deliver the product.
“Morpho worked with Microsoft Corporation to develop a cloud service for Morpho’s flagship Biometric Identification Solution (MorphoBIS). Morpho Cloud is hosted on Microsoft Azure Government, the cloud platform with a contractual commitment to support several U.S. government standards for data security, including the FBI’s CJIS Security Policy. Backed by the Microsoft Azure Government platform, Morpho Cloud complies with the stringent security standards for storage, transmission, monitoring, and recovery of digital information.”
Then there was the time I was performing U.S. go-to-market activities for a global identity/biometric offering.
The product marketing launch went great…
…until the home office received a communication from a competitor.
A competitor with a previously existing product with a name VERY similar to that of our subsequently launched solution.
Oops.
We definitely made a mistake by not thoroughly checking the name.
Of course, with the way that some companies want to imitate the things their competitors do, I’m sure some firms perform this intentionally, rather than accidentally.