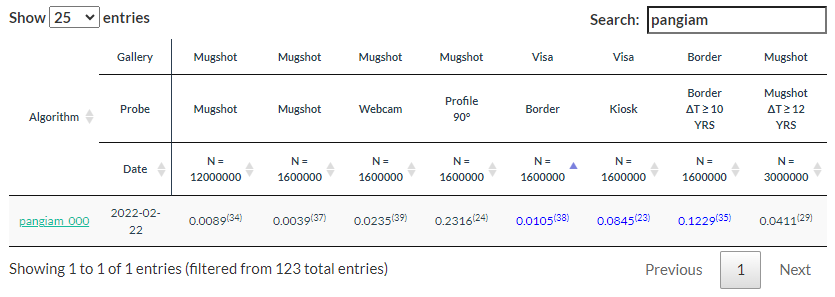
(Part of the biometric product marketing expert series)
Before you can fully understand the difference between personally identifiable information (PII) and protected health information (PHI), you need to understand the difference between biometrics and…biometrics. (You know sometimes words have two meanings.)

The definitions of biometrics
To address the difference between biometrics and biometrics, I’ll refer to something I wrote over two years ago, in late 2021. In that post, I quoted two paragraphs from the International Biometric Society that illustrated the difference.
Since the IBS has altered these paragraphs in the intervening years, I will quote from the latest version.
The terms “Biometrics” and “Biometry” have been used since early in the 20th century to refer to the field of development of statistical and mathematical methods applicable to data analysis problems in the biological sciences.
Statistical methods for the analysis of data from agricultural field experiments to compare the yields of different varieties of wheat, for the analysis of data from human clinical trials evaluating the relative effectiveness of competing therapies for disease, or for the analysis of data from environmental studies on the effects of air or water pollution on the appearance of human disease in a region or country are all examples of problems that would fall under the umbrella of “Biometrics” as the term has been historically used….
The term “Biometrics” has also been used to refer to the field of technology devoted to the identification of individuals using biological traits, such as those based on retinal or iris scanning, fingerprints, or face recognition. Neither the journal “Biometrics” nor the International Biometric Society is engaged in research, marketing, or reporting related to this technology. Likewise, the editors and staff of the journal are not knowledgeable in this area.
From https://www.biometricsociety.org/about/what-is-biometry.
In brief, what I call “broad biometrics” refers to analyzing biological sciences data, ranging from crop yields to heart rates. Contrast this with what I call “narrow biometrics,” which (usually) refers only to human beings, and only to those characteristics that identify human beings, such as the ridges on a fingerprint.
The definition of “personally identifiable information” (PII)
Now let’s examine an issue related to narrow biometrics (and other things), personally identifiable information, or PII. (It’s also represented as personal identifiable information by some.) I’ll use a definition provided by the U.S. National Institute of Standards and Technology, or NIST.
Information that can be used to distinguish or trace an individual’s identity, either alone or when combined with other information that is linked or linkable to a specific individual.
From https://csrc.nist.gov/glossary/term/PII.
Note the key words “alone or when combined.” The ten numbers “909 867 5309” are not sufficient to identify an individual alone, but can identify someone when combined with information from another source, such as a telephone book.
Yes, a telephone book. Deal with it.

What types of information can be combined to identify a person? The U.S. Department of Defense’s Privacy, Civil Liberties, and Freedom of Information Directorate provides multifarious examples of PII, including:
- Social Security Number.
- Passport number.
- Driver’s license number.
- Taxpayer identification number.
- Patient identification number.
- Financial account number.
- Credit card number.
- Personal address.
- Personal telephone number.
- Photographic image of a face.
- X-rays.
- Fingerprints.
- Retina scan.
- Voice signature.
- Facial geometry.
- Date of birth.
- Place of birth.
- Race.
- Religion.
- Geographical indicators.
- Employment information.
- Medical information.
- Education information.
- Financial information.
Now you may ask yourself, “How can I identify someone by a non-unique birthdate? A lot of people were born on the same day!”
But the combination of information is powerful, as researchers discovered in a 2015 study cited by the New York Times.
In the study, titled “Unique in the Shopping Mall: On the Reidentifiability of Credit Card Metadata,” a group of data scientists analyzed credit card transactions made by 1.1 million people in 10,000 stores over a three-month period. The data set contained details including the date of each transaction, amount charged and name of the store.
Although the information had been “anonymized” by removing personal details like names and account numbers, the uniqueness of people’s behavior made it easy to single them out.
In fact, knowing just four random pieces of information was enough to reidentify 90 percent of the shoppers as unique individuals and to uncover their records, researchers calculated. And that uniqueness of behavior — or “unicity,” as the researchers termed it — combined with publicly available information, like Instagram or Twitter posts, could make it possible to reidentify people’s records by name.
From https://archive.nytimes.com/bits.blogs.nytimes.com/2015/01/29/with-a-few-bits-of-data-researchers-identify-anonymous-people/.
So much for anonymization. And privacy.
Now biometrics only form part of the multifarious list of data cited above, but clearly biometric data can be combined with other data to identify someone. An easy example is taking security camera footage of the face of a person walking into a store, and combining that data with the same face taken from a database of driver’s license holders. In some jurisdictions, some entities are legally permitted to combine this data, while others are legally prohibited from doing so. (A few do it anyway. But I digress.)
Because narrow biometric data used for identification, such as fingerprint ridges, can be combined with other data to personally identify an individual, organizations that process biometric data must undertake strict safeguards to protect that data. If personally identifiable information (PII) is not adequately guarded, people could be subject to fraud and other harms.
The definition of “protected health information” (PHI)
In this case, I’ll refer to information published by the U.S. Department of Health and Human Services.
Protected Health Information. The Privacy Rule protects all “individually identifiable health information” held or transmitted by a covered entity or its business associate, in any form or media, whether electronic, paper, or oral. The Privacy Rule calls this information “protected health information (PHI).”12
“Individually identifiable health information” is information, including demographic data, that relates to:
the individual’s past, present or future physical or mental health or condition,
the provision of health care to the individual, or
the past, present, or future payment for the provision of health care to the individual,
and that identifies the individual or for which there is a reasonable basis to believe it can be used to identify the individual.13 Individually identifiable health information includes many common identifiers (e.g., name, address, birth date, Social Security Number).
The Privacy Rule excludes from protected health information employment records that a covered entity maintains in its capacity as an employer and education and certain other records subject to, or defined in, the Family Educational Rights and Privacy Act, 20 U.S.C. §1232g.
From https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html
Now there’s obviously an overlap between personally identifiable information (PII) and protected health information (PHI). For example, names, dates of birth, and Social Security Numbers fall into both categories. But I want to highlight two things are are explicitly mentioned as PHI that aren’t usually cited as PII.
- Physical or mental health data. This could include information that a medical professional captures from a patient, including biometric (broad biometric) information such as heart rate or blood pressure.
- Health care provided to an individual. This not only includes written information such as prescriptions, but oral information (“take two aspirin and call my chatbot in the morning”). Yes, chatbot. Deal with it. Dr. Marcus Welby and his staff retired a long time ago.

Because broad biometric data used for analysis, such as heart rates, can be combined with other data to personally identify an individual, organizations that process biometric data must undertake strict safeguards to protect that data. If protected health information (PHI) is not adequately guarded, people could be subject to fraud and other harms.
Simple, isn’t it?
Actually, the parallels between identity/biometrics and healthcare have fascinated me for decades, since the dedicated hardware to capture identity/biometric data is often similar to the dedicated hardware to capture health data. And now that we’re moving away from dedicated hardware to multi-purpose hardware such as smartphones, the parallels are even more fascinating.