It’s been years since I talked about Identity Assurance Levels (IALs) in any detail, but I wanted to delve into two of the levels and see when IAL3 is necessary, and when it is not.
The U.S. National Institute of Standards and Technology has defined “identity assurance levels” (IALs) that can be used when dealing with digital identities. It’s helpful to review how NIST has defined the IALs.
Assurance in a subscriber’s identity is described using one of three IALs:
IAL1: There is no requirement to link the applicant to a specific real-life identity. Any attributes provided in conjunction with the subject’s activities are self-asserted or should be treated as self-asserted (including attributes a [Credential Service Provider] CSP asserts to an [Relying Party] RP). Self-asserted attributes are neither validated nor verified.
IAL2: Evidence supports the real-world existence of the claimed identity and verifies that the applicant is appropriately associated with this real-world identity. IAL2 introduces the need for either remote or physically-present identity proofing. Attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL2 can support IAL1 transactions if the user consents.
IAL3: Physical presence is required for identity proofing. Identifying attributes must be verified by an authorized and trained CSP representative. As with IAL2, attributes could be asserted by CSPs to RPs in support of pseudonymous identity with verified attributes. A CSP that supports IAL3 can support IAL1 and IAL2 identity attributes if the user consents.
For purposes of this post, IAL1 is (if I may use a technical term) a nothingburger. It may be good enough for a Gmail account, but these days even social media accounts are more likely to require IAL2.
So what’s the practical difference between IAL2 and IAL3?
If we ignore IAL1 and concentrate on IAL2 and IAL3, we can see one difference between the two. IAL2 allows remote, unsupervised identity proofing, while IAL3 requires (in practice) that any remote identity proofing is supervised.
Much of my time at my previous employer Incode Technologies involved unsupervised remote identity proofing (IAL2). For example, if a woman wants to set up an account at a casino, she can complete the onboarding process to set up the account on her phone, without anyone from the casino being present to make sure she wasn’t faking her face or her ID. (Fraud detection is the “technologies” part of Incode Technologies, and that’s how they make sure she isn’t faking.)
SRIP provides remote supervision of in-person proofing using NextgenID’s Identity Stations, an all-in-one system designed to securely perform all enrollment processes and workflow requirements. The station facilitates the complete and accurate capture at IAL levels 1, 2 and 3 of all required personal identity documentations and includes a full complement of biometric capture support for face, fingerprint, and iris.
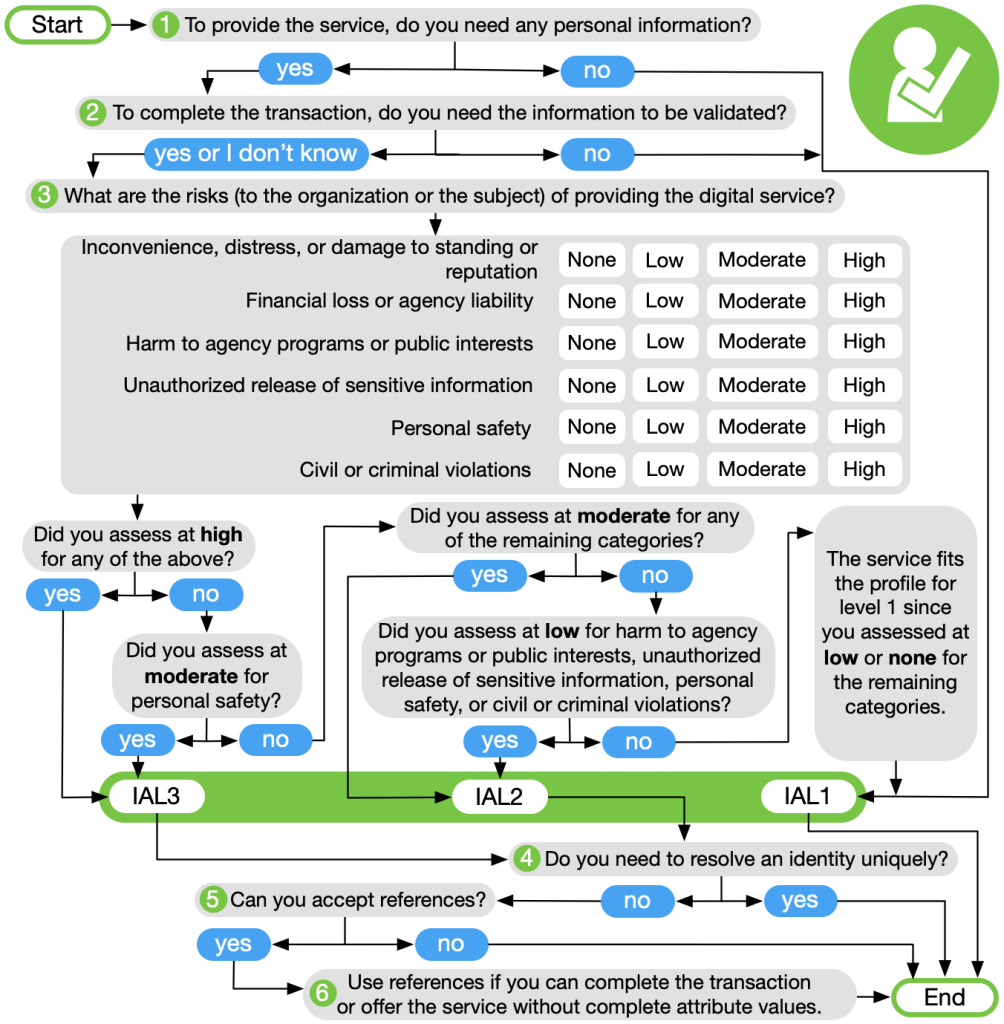
Now there are some other differences between IAL2 and IAL3 in terms of the proofing, so NIST came up with a handy dandy chart that allows you to decide which IAL level you need.
At this point, the agency understands that some level of proofing is required. Step 3 is intended to look at the potential impacts of an identity proofing failure to determine if IAL2 or IAL3 is the most appropriate selection. The primary identity proofing failure an agency may encounter is accepting a falsified identity as true, therefore providing a service or benefit to the wrong or ineligible person. In addition, proofing, when not required, or collecting more information than needed is a risk in and of itself. Hence, obtaining verified attribute information when not needed is also considered an identity proofing failure. This step should identify if the agency answered Step 1 and 2 incorrectly, realizing they do not need personal information to deliver the service. Risk should be considered from the perspective of the organization and to the user, since one may not be negatively impacted while the other could be significantly harmed. Agency risk management processes should commence with this step.
Even with the complexity of the flowchart, some determinations can be pretty simple. For example, if any of the six risks listed under question 3 are determined to be “high,” then you must use IAL3.
But the whole exercise is a lot to work through, and you need to work through it yourself. When I pasted the PNG file for the flowchart above into this blog post, I noticed that the filename is “IAL_CYOA.png.” And we all know what “CYOA” means.
But if you do the work, you’ll be better informed on the procedures you need to use to verify the identities of people.
One footnote: although NIST is a U.S. organization, its identity assurance levels (including IAL2 and IAL3) are used worldwide, including by the World Bank. So everyone should be familiar with them.
After a lack of appearances in the Bredemarket blog (none since November), Pangiam is making an appearance again, based on announcements by Biometric Update and Trueface itself about a new revision of the Trueface facial recognition SDK.
The new revision includes a number of features, including a new model for masked faces and some technical improvements.
So what is this revision called?
Version 1.0.
“Wait,” you’re asking yourself. “Version 1.0 is the NEW version? It sounds like the ORIGINAL version. Shouldn’t the new version be 2.0?”
Well, no. The original version was V0. Trueface is now ready to release V1.
Well, almost ready.
If you go to the Trueface SDK reference page, you’ll see that Trueface releases are categorized as “alpha,” “beta,” and “stable.”
When I viewed the page on the afternoon of March 28, the latest stable release was 0.33.14634.
If you want to use the version 1.0 that is being “introduced” (Pangiam’s word), you have to go to the latest beta release, which was 1.0.16286.
And if you want to go bleeding edge alpha, you can get release 1.1.16419.
(Again, this was on the afternoon of March 28, and may change by the time you read this.)
Now most biometric vendors don’t expose this much detail about their software. Some don’t even provide any release information, especially for products with long delivery times where the version that a customer will eventually get doesn’t even have locked-down requirements yet. But Pangiam has chosen to provide this level of detail.
Oh, and Pangiam/Trueface also actively participates in the ongoing NIST FRVT testing. Information on the 1:1 performance of the trueface-003 algorithm can be found here. Information on the 1:N performance of the trueface-000 algorithm can be found here.
(When I wrote this in 2022 I used the then-current FRVT terminology. I’ve updated to FRTE as warranted.)
As I’ve noted before, there are a number of facial recognition companies that claim to be the #1 NIST facial recognition vendor. I’m here to help you cut through the clutter so you know who the #1 NIST facial recognition vendor truly is.
You can confirm this information yourself by visiting the NIST FRTE 1:1 Verification and FRTE 1:N Identification pages. The old FRVT, by the way, stood for “Face Recognition Vendor Test”—and has subsequently been replaced by FRTE, “Face Recognition Technology Evaluation.”
Now how can ALL dozen-plus of these entities be number 1?
Easy.
The NIST 1:1 and 1:N tests include many different accuracy and performance measurements, and each of the entities listed above placed #1 in at least one of these measurements. And all of the databases, database sizes, and use cases measure very different things.
Visage Technologies was #1 in the 1:1 performance measurements for template generation time, in milliseconds, for 480×720 and 960×1440 data.
Meanwhile, NEC was #1 in the 1:N Identification (T>0) accuracy measurements for gallery border, probe border with a delta T greater than or equal to 10 years, N = 1.6 million.
Not to be confused with the 1:N Identification (T>0) accuracy measurements for gallery visa, probe border, N = 1.6 million, where the #1 algorithm was not from NEC.
And not to be confused with the 1:N Investigation (R = 1, T = 0) accuracy measurements for gallery border, probe border with a delta T greater than or equal to 10 years, N = 1.6 million, where the #1 algorithm was not from NEC.
And can I add a few more caveats?
First caveat: Since all of these tests are ongoing tests, you can probably find a slightly different set of #1 algorithms if you look at the January data, and you will probably find a slightly different set of #1 algorithms when the March data is available.
Second caveat: These are the results for the unqualified #1 NIST categories. You can add qualifiers, such as “#1 non-Chinese vendor” or “#1 western vendor” or “#1 U.S. vendor” to vault a particular algorithm to the top of the list.
Third caveat: You can add even more qualifiers, such as “within the top five NIST vendors” and (one I admit to having used before) “a top tier NIST vendor in multiple categories.” This can mean whatever you want it to mean. (As can “dramatically improved” algorithm, which may mean that you vaulted from position #300 to position #200 in one of the categories.)
Fourth caveat: Even if a particular NIST test applies to your specific use case, #1 performance on a NIST test does not guarantee that a facial recognition system supplied by that entity will yield #1 performance with your database in your environment. The algorithm sent to NIST may or may not make it into a production system. And even if it does, performance against a particular NIST test database may not yield the same results as performance against a Rhode Island criminal database, a French driver’s license database, or a Nigerian passport database. For more information on this, see Mike French’s LinkedIn article “Why agencies should conduct their own AFIS benchmarks rather than relying on others.”
So now that you know who the #1 NIST facial recognition vendor is, do you feel more knowledgeable?
Although I’ll grant that a NIST accuracy or performance claim is better than some other claims, such as self-test results.
As many of you know, there have been many claims about bias in facial recognition, which have even led to the formation of an Algorithmic Justice League.
Whoops, wrong Justice League. But you get the idea. “Gender Shades” and stuff like that, which I’ve written about before.
Back to Hall’s article, which makes a number of excellent points about bias in facial recognition, including the studies performed by NIST (referenced later in this post), but I loved one comparison that Baker wrote about.
So technical improvements may narrow but not entirely eliminate disparities in face recognition. Even if that’s true, however, treating those disparities as a moral issue still leads us astray. To see how, consider pharmaceuticals. The world is full of drugs that work a bit better or worse in men than in women. Those drugs aren’t banned as the evil sexist work of pharma bros. If the gender differential is modest, doctors may simply ignore the difference, or they may recommend a different dose for women. And even when the differential impact is devastating—such as a drug that helps men but causes birth defects when taken by pregnant women—no one wastes time condemning those drugs for their bias. Instead, they’re treated like any other flawed tool, minimizing their risks by using a variety of protocols from prescription requirements to black box warnings.
As an (tangential) example of this, I recently read an article entitled “To begin addressing racial bias in medicine, start with the skin.” This article does not argue that we should ban dermatology because conditions are more often misdiagnosed in people with darker skin. Instead, the article argues that we should improve dermatology to reduce these biases.
In the same manner, the biometric industry and stakeholder should strive to minimize bias in facial recognition and other biometrics, not ban it. See NIST’s study (NISTIR 8280, PDF) in this regard, referenced in Baker’s article.
In addition to what Baker said, let me again note that when judging the use of facial recognition, it should be compared against the alternatives. While I believe that alternatives should be offered, even passwords, consider that automated facial recognition supported by trained examiner review is much more accurate than witness (mis)identification. I don’t think we want to solely rely on that.
Because falsely imprisoning someone due to non-algorithmic witness misidentification is as bad as kryptonite.
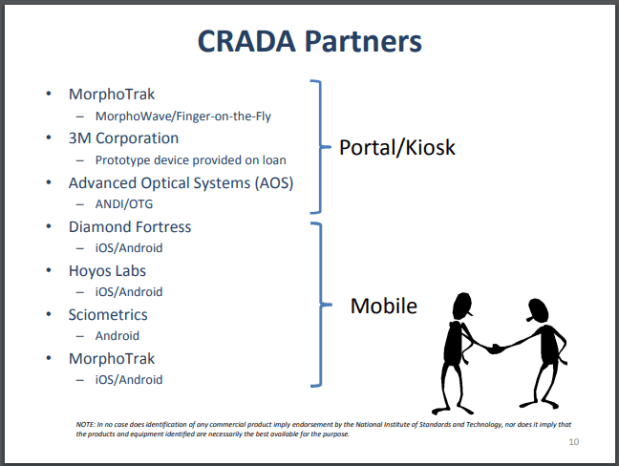
I’ve worked in the general area of contactless fingerprint capture for years, initially while working for a NIST CRADA partner. While most of the NIST CRADA partners are still pursuing contactless fingerprint technology, there are also new entrants.
In the pre-COVID days, the primary advantage of contactless fingerprint capture was speed. As I noted in an October 2021 post:
Actually this effort launched before that, as there were efforts in 2004 and following years to capture a complete set of fingerprints within 15 seconds; those efforts led, among other things, to the smartphone software we are seeing today.
By 2016, several companies had entered into cooperative research and development agreements with NIST to develop contactless fingerprint capture software, either for dedicated devices or for smartphones. Most of those early CRADA participants are still around today, albeit under different names.
I’ve previously written posts about two of these CRADA partners, Telos ID (previously Diamond Fortress) and Sciometrics (the supplier for Integrated Biometrics).
But these aren’t the only players in the contactless fingerprint market. There are always new entrants in a market where there is opportunity.
A month before I wrote my post about Integrated Biometrics/Sciometrics’ SlapShot, a company called Tech5 released its own product.
T5-AirSnap Finger uses a smartphone’s built-in camera to perform finger detection, enhancement, image processing and scaling, generating images that can be transmitted for identity verification or registration within seconds, according to the announcement. The resulting images are suitable for use with standard AFIS solutions, and comparison against legacy datasets…
Parthe has noted the importance of smartphone-based contactless fingerprint capture:
“We all carry these awesome computers in our hands,” Parthe explains. “It’s a perfectly packaged hardware device that is ideal for any capture technology. Smartphones are powerful compute devices on the edge, with a nice integrated camera with auto-focus and flash. And now phones also come with multiple cameras which can help with better focus and depth estimation. This allows the users to take photos of their fingers and the software takes care of the rest. I’d just like to point out here that we’re talking about using the phone’s camera to capture biometrics and using a smartphone to take the place of a dedicated reader. We’re not talking about the in-built fingerprint acquisition we’re all familiar with on many devices which is the means of accessing the device itself.”
I’ve made a similar point before. While dedicated devices may not completely disappear, multi-purpose devices that we already have are the preferable way to go.
For more information about T5-AirSnap Finger, visit this page.
Tech5’s results for NIST’s Proprietary Fingerprint Template (PFT) Evaluation III, possibly using an algorithm similar to that in T5-AirSnap Finger, are detailed here.
This report, currently published in draft form, reviews the methods that forensic laboratories use to interpret evidence containing a mixture of DNA from two or more people.
The problem of mixtures is more pronounced in DNA analysis than in analysis of other biometrics. You aren’t going to encounter two overlapping irises or two overlapping faces in the real world. (Well, not normally.)
You can certainly encounter overlapping voices (in a recorded conversation) or overlapping fingerprints (when two or more people touched the same item).
But there are methods to separate one biometric sample from another.
It’s a little more complicated when you’re dealing with DNA.
Distinguishing one person’s DNA from another in these mixtures, estimating how many individuals contributed DNA, determining whether the DNA is even relevant or is from contamination, or whether there is a trace amount of suspect or victim DNA make DNA mixture interpretation inherently more challenging than examining single-source samples. These issues, if not properly considered and communicated, can lead to misunderstandings regarding the strength and relevance of the DNA evidence in a case.
As some of you know, I have experience with “rapid DNA” instruments that provide a mostly-automated way to analyze DNA samples. Because these instruments are mostly automated and designed for use by non-scientific personnel, they are not able to analyze all of the types of DNA that would be analyzed by a forensic laboratory.
Therefore, this draft document is silent on the topic of rapid DNA, despite the fact that co-author Peter Vallone has years of experience in rapid DNA.
I am not a scientist, but in my view the absence of any reference to rapid DNA strongly suggests that it’s premature at this time to apply these instruments to DNA mixtures, such as rape cases in which both the assailant’s and the victim’s DNA are present in a sample.
Granted, there may be rape cases in which the DNA of the assailant may be present with no mixture.
You have to be REALLY careful before claiming that rapid DNA instruments can be used to wipe out the backlog of rape test kits. However, rapid DNA can be used to clear less complicated DNA cases so that the laboratories can concentrate on the more complex cases.
For those who have never looked at FRVT before, it does not merely report the accuracy results of searches against one database, but reports accuracy results for searches against eight different databases of different types and of different sizes (N).
Mugshot, Mugshot, N = 12000000
Mugshot, Mugshot, N = 1600000
Mugshot, Webcam, N = 1600000
Mugshot, Profile, N = 1600000
Visa, Border, N = 1600000
Visa, Kiosk, N = 1600000
Border, Border 10+YRS, N = 1600000
Mugshot, Mugshot 12+YRS, N = 3000000
This is actually good for the vendors who submit their biometric algorithms, because even if the algorithm performs poorly on one of the databases, it may perform wonderfully on one of the other seven. That’s how so many vendors can trumpet that their algorithm is the best. When you throw in other qualifiers such as “top five,” “best non-Chinese vendor,” and even “vastly improved,” you can see how dozens of vendors can issue “NIST says we’re the best” press releases.
Not that I knock the practice; after all, I myself have done this for years. But you need to know how to interpret these press releases, and what they’re really saying. Remember this when you read the vendor announcement toward the end of this post.
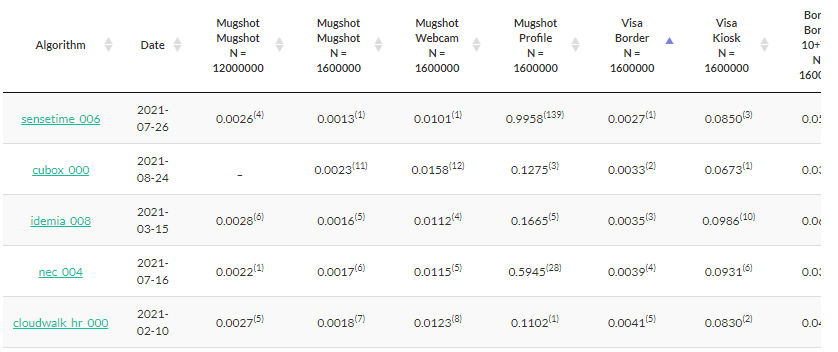
Anyway, I went to check the current results, which when you originally visit the page are sorted in the order of the fifth database, the Visa Border database. And this is what I saw this morning (October 27):
For the most part, the top five for the Visa Border test contain the usual players. North Americans will be most familiar with IDEMIA and NEC, and Cloudwalk and Sensetime have been around for a while.
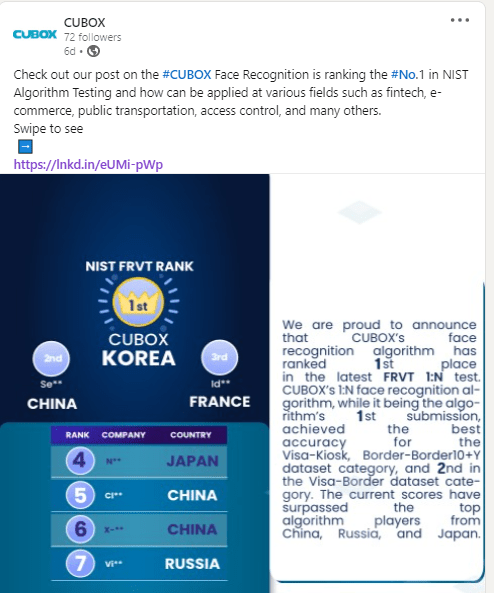
A new algorithm from a not-so-new provider
But I had never noticed Cubox in the NIST testing before. And the number attached to the Cubox algorithm, “000,” indicates that this is Cubox’s first submission.
And Cubox did exceptionally well, especially for a first submission.
As you can see by the superscripts attached to each numeric value, Cubox had the second most accurate algorithm for the Visa Border test, the most accurate algorithm for the Visa Kiosk test, and placed no lower than 12th in the six (of eight) tests in which it participated. Considering that 302 algorithms have been submitted over the years, that’s pretty remarkable for a first-time submission.
Well, as an ex-IDEMIA employee, my curious nature kicked in.
The Cubox that submitted an algorithm to NIST is a South Korean firm with the website cubox.aero, self-described as “The Leading Provider in Biometrics” (aren’t they all?) with fingerprint and face solutions. Cubox competes in the access control and border control markets.
Cubox’s ten-year history and “overseas” page details its growth in its markets, and its solutions that it has provided in South Korea, Mongolia, and Vietnam.
And although Cubox hasn’t trumpeted its performance on its own website (at least in the English version; I don’t know about the Korean version), Cubox has publicized its accomplishment on a LinkedIn post.
But before you get excited about the NIST results from Cubox, Sensetime, or any of the algorithm providers, remember that the NIST test is just a test. NIST cautions people about this, I have cautioned people about this (see the fourth point in this post), and Mike French has also discussed this.
However, it is also important to remember that NIST does not test operational systems, but rather technology submitted as software development kits or SDKs. Sometimes these submissions are labeled as research (or just not labeled), but in reality it cannot be known if these algorithms are included in the product that an agency will ultimately receive when they purchase a biometric system. And even if they are “thesame”, the operational architecture could produce different results with the same core algorithms optimized for use in a NIST study.
The very fact that test results vary between the NIST databases explicitly tells you that a number one ranking on one database does not mean that you’ll get a number one ranking on every database. And as French reminds us, when you take an operational algorithm in an operational system with a customer database, the results may be quite different.
Which is why French recommends that any government agency purchasing a biometric system should conduct its own test, with vendor operational systems (rather than test systems) loaded with the agency’s own data.
Incidentally, if your agency needs a forensic expert to help with a biometric procurement or implementation, check out the consulting services offered by French’s company, Applied Forensic Services.
Let me kick off this post by quoting from another post that I wrote:
I’ve always been of the opinion that technology is moving away from specialized hardware to COTS hardware. For example, the fingerprint processing and matching that used to require high-end UNIX computers with custom processor boards in the 1990s can now be accomplished on consumer-grade smartphones.
Further evidence of this was promoted in advance of #connectID by Integrated Biometrics.
And yes, for those following Integrated Biometrics’ naming conventions, there IS a 1970s movie called “Slap Shot,” but I don’t think it has anything to do with crime solving. Unless you count hockey “enforcers” as law enforcement. And the product apparently wasn’t named by Integrated Biometrics anyway.
SlapShot supports the collection of Fingerprint and facial images suitable for use with state of the art matching algorithms. Fingerprints can now be captured by advanced software that enables the camera in your existing smart phones to generate images with a quality capable of precise identification. Facial recognition and metadata supplement the identification process for any potential suspect or person of interest.
This groundbreaking approach turns almost any smart phone into a biometric capture device, and with minimal integration, your entire force can leverage their existing smart phones to capture fingerprints for identification and verification, receiving matching results in seconds from a centralized repository.
Great, you say! But there’s one more thing. Two more things, actually:
SlapShot functions on Android devices that support Lollipop or later operating systems and relies on the device’s rear high-resolution camera. Images captured from the camera are automatically processed on the device in the background and converted into EBTS files. Once the fingerprint image is taken, the fingerprint matcher in the cloud returns results instantly.
The SlapShot SDK allows developers to capture contactless fingerprints and other biometrics within their own apps via calls to the SlapShot APIs.
Note that SlapShot is NOT intended for end users, but for developers to incorporate into existing applications. Also note that it is (currently) ONLY supported on Android, not iOS.
But this does illustrate the continuing move away from dedicated devices, including Integrated Biometrics’ own line of dedicated devices, to multi-use devices that can also perform forensic capture and perform or receive forensic matching results.
And no, Integrated Biometrics is not cannibalizing its own market. I say this for two reasons.
First, there are still going to be customers who will want dedicated devices, for a variety of reasons.
Second, if Integrated Biometrics doesn’t compete in the smartphone contactless fingerprint capture market, it will lose sales to the companies that DO compete in this market.
Contactless fingerprint capture has been pursued by multiple companies for years, ever since the NIST CRADA was issued a few years ago. (Integrated Biometrics’ partner Sciometrics was one of those early CRADA participants, along with others.) Actually this effort launched before that, as there were efforts in 2004 and following years to capture a complete set of fingerprints within 15 seconds; those efforts led, among other things, to the smartphone software we are seeing today. Not only from Integrated Biometrics/Sciometrics, but also from other CRADA participants. (Don’t forget this one.)
While he does not explicitly talk about the myriad of facial recognition algorithms that were NOT addressed in the study, he does have some additional details about the test dataset.
The three algorithms that were tested
Here’s what FindBiometrics says about the three algorithms that were tested in the Israeli study.
The researchers described (the master faces) as master keys that could unlock the three facial recognition systems that were used to test the theory. In that regard, they challenged the Dlib, FaceNet, and SphereFace systems, and their nine master faces were able to impersonate more than 40 percent of the 5,749 people in the LFW set.
While it initially sounds impressive to say that three facial recognition algorithms were fooled by the master faces, bear in mind that there are hundreds of facial recognition algorithms tested by NIST alone, and (as I said earlier) the test has NOT been duplicated against any algorithms other than the three open source algorithms mentioned.
…let’s look at the algorithms themselves and evaluate the claim that results for the three algorithms Dlib, FaceNet, and SphereFace can naturally be extrapolated to ALL facial recognition algorithms….NIST’s subsequent study…evaluated 189 algorithms specially for 1:1 and 1:N use cases….“Tests showed a wide range in accuracy across developers, with the most accurate algorithms producing many fewer errors.”
In short, just because the three open source algorithms were fooled by master faces doesn’t mean that commercial grade algorithms would also be fooled by master faces. Maybe they would be fooled…or maybe they wouldn’t.
What about the dataset?
The three open source algorithms were tested against the dataset from Labeled Faces in the Wild. As I noted in my prior post, the LFW people emphasize some important caveats about their dataset, including the following:
Many groups are not well represented in LFW. For example, there are very few children, no babies, very few people over the age of 80, and a relatively small proportion of women. In addition, many ethnicities have very minor representation or none at all.
In the FindBiometrics article, Weiss provides some additional detail about dataset representation.
…there is good reason to question the researchers’ conclusion. Only two of the nine master faces belong to women, and most depicted white men over the age of 60. In plain terms, that means that the master faces are not representative of the global public, and they are not nearly as effective when applied to anyone that falls outside one particular demographic.
That discrepancy can largely be attributed to the limitations of the LFW dataset. Women make up only 22 percent of the dataset, and the numbers are even lower for children, the elderly (those over the age of 80), and for many ethnic groups.
Valid points to be sure, although the definition of a “representative” dataset varies depending upon the use case. For example, a representative dataset for a law enforcement database in the city of El Paso, Texas will differ from a representative dataset for an airport database catering to Air France customers.
So what conclusion can be drawn?
Perhaps it’s just me, but scientific entities that conduct studies are always motivated by the need for additional funding. After a study is concluded, it seems that the entities always conclude that “more research is needed”…which can be self-serving, because as long as more research is needed, the scientific entities can continue to receive necessary funding. Imagine the scientific entity that would dare to say “Well, all necessary research has been conducted. We’re closing down our research center.”
But in this case, there IS a need to perform additional research, to test the master faces against different algorithms and against different datasets. Then we’ll know whether this statement from the FindBiometrics article (emphasis mine) is actually true:
Any face-based identification system would be extremely vulnerable to spoofing…
Modern “journalism” often consists of reprinting a press release without subjecting it to critical analysis. Sadly, I see a lot of this in publications, including both biometric and technology publications.
This post looks at the recently announced master faces study results, the datasets used (and the datasets not used), the algorithms used (and the algorithms not used), and the (faulty) conclusions that have been derived from the study.
Oh, and it also informs you of a way to make sure that you don’t make the same mistakes when talking about biometrics.
In facial recognition, there is a concept called “master faces” (similar concepts can be found for other biometric modalities). The idea behind master faces is that such data can potentially match against MULTIPLE faces, not just one. This is similar to a master key that can unlock many doors, not just one.
This can conceivably happen because facial recognition algorithms do not match faces to faces, but match derived features from faces to derived features from faces. So if you can create the right “master” feature set, it can potentially match more than one face.
Ever thought you were being gaslighted by industry claims that facial recognition is trustworthy for authentication and identification? You have been.
The article goes on to discuss an Israeli research project that demonstrated some true “master faces” vulnerabilities. (Emphasis mine.)
One particular approach, which they write was based on Dlib, created nine master faces that unlocked 42 percent to 64 percent of a test dataset. The team also evaluated its work using the FaceNet and SphereFace, which like Dlib, are convolutional neural network-based face descriptors.
They say a single face passed for 20 percent of identities in Labeled Faces in the Wild, an open-source database developed by the University of Massachusetts. That might make many current facial recognition products and strategies obsolete.
Sounds frightening. After all, the study not only used dlib, FaceNet, and SphereFace, but also made reference to a test set from Labeled Faces in the Wild. So it’s obvious why master faces techniques might make many current facial recognition products obsolete.
Right?
Let’s look at the datasets
It’s always more impressive to cite an authority, and citations of the University of Massachusetts’ Labeled Faces in the Wild (LFW) are no exception. After all, this dataset has been used for some time to evaluate facial recognition algorithms.
But what does Labeled Faces in the Wild say about…itself? (I know this is a long excerpt, but it’s important.)
DISCLAIMER:
Labeled Faces in the Wild is a public benchmark for face verification, also known as pair matching. No matter what the performance of an algorithm on LFW, it should not be used to conclude that an algorithm is suitable for any commercial purpose. There are many reasons for this. Here is a non-exhaustive list:
Face verification and other forms of face recognition are very different problems. For example, it is very difficult to extrapolate from performance on verification to performance on 1:N recognition.
Many groups are not well represented in LFW. For example, there are very few children, no babies, very few people over the age of 80, and a relatively small proportion of women. In addition, many ethnicities have very minor representation or none at all.
While theoretically LFW could be used to assess performance for certain subgroups, the database was not designed to have enough data for strong statistical conclusions about subgroups. Simply put, LFW is not large enough to provide evidence that a particular piece of software has been thoroughly tested.
Additional conditions, such as poor lighting, extreme pose, strong occlusions, low resolution, and other important factors do not constitute a major part of LFW. These are important areas of evaluation, especially for algorithms designed to recognize images “in the wild”.
For all of these reasons, we would like to emphasize that LFW was published to help the research community make advances in face verification, not to provide a thorough vetting of commercial algorithms before deployment.
While there are many resources available for assessing face recognition algorithms, such as the Face Recognition Vendor Tests run by the USA National Institute of Standards and Technology (NIST), the understanding of how to best test face recognition algorithms for commercial use is a rapidly evolving area. Some of us are actively involved in developing these new standards, and will continue to make them publicly available when they are ready.
So there are a lot of disclaimers in that text.
LFW is a 1:1 test, not a 1:N test. Therefore, while it can test how one face compares to another face, it cannot test how one face compares to a database of faces. The usual law enforcement use case is to compare a single face (for example, one captured from a video camera) against an entire database of known criminals. That’s a computationally different exercise from the act of comparing a crime scene face against a single criminal face, then comparing it against a second criminal face, and so forth.
The people in the LFW database are not necessarily representative of the world population, the population of the United States, the population of Massachusetts, or any population at all. So you can’t conclude that a master face that matches against a bunch of LFW faces would match against a bunch of faces from your locality.
Captured faces exhibit a variety of quality levels. A face image captured by a camera three feet from you at eye level in good lighting will differ from a face image captured by an overhead camera in poor lighting. LFW doesn’t have a lot of these latter images.
I should mention one more thing about LFW. The researchers allow testers to access the database itself, essentially making LFW an “open book test.” And as any student knows, if a test is open book, it’s much easier to get an A on the test.
Now let’s take a look at another test that was mentioned by the LFW folks itself: namely, NIST’s Face Recognition Vendor Test.
This is actually a series of tests that has evolved over the years; NIST is now conducting ongoing tests for both 1:1 and 1:N (unlike LFW, which only conducts 1:1 testing). This is important because most of the large-scale facial recognition commercial applications that we think about are 1:N applications (see my example above, in which a facial image captured at a crime scene is compared against an entire database of criminals).
In addition, NIST uses multiple data sets that cover a number of use cases, including mugshots, visa photos, and faces “in the wild” (i.e. not under ideal conditions).
It’s also important to note that NIST’s tests are also intended to benefit research, and do not necessarily indicate that a particular algorithm that performs well for NIST will perform well in a commercial implementation. (If the algorithm is even available in a commercial implementation: some of the algorithms submitted to NIST are research algorithms only that never made it to a production system.) For the difference between testing an algorithm in a NIST test and testing an algorithm in a production system, please see Mike French’s LinkedIn article on the topic. (I’ve cited this article before.)
With those caveats, I will note that NIST’s FRVT tests are NOT open book tests. Vendors and other entities give their algorithms to NIST, NIST tests them, and then NIST tells YOU what the results were.
So perhaps it’s more robust than LFW, but it’s still a research project.
Let’s look at the algorithms
Now that we’ve looked at two test datasets, let’s look at the algorithms themselves and evaluate the claim that results for the three algorithms Dlib, FaceNet, and SphereFace can naturally be extrapolated to ALL facial recognition algorithms.
This isn’t the first time that we’ve seen such an attempt at extrapolation. After all, the MIT Media Lab’s Gender Shades study (which evaluated neither 1:1 nor 1:N use cases, but algorithmic attempts to identify gender and race) itself only used three algorithms. Yet the popular media conclusion from this study was that ALL facial recognition algorithms are racist.
Compare this with NIST’s subsequent study, which evaluated 189 algorithms specially for 1:1 and 1:N use cases. While NIST did find some race/sex differences in algorithms, these were not universal: “Tests showed a wide range in accuracy across developers, with the most accurate algorithms producing many fewer errors.”
In other words, just because an earlier test of three algorithms demonstrated issues in determining race or gender, that doesn’t mean that the current crop of hundreds of algorithms will necessarily demonstrate issues in identifying individuals.
So let’s circle back to the master faces study. How do the results of this study affect “current facial recognition products”?
The answer is “We don’t know.”
Has the master faces experiment been duplicated against the leading commercial algorithms tested by Labeled Faces in the Wild? Apparently not.
Has the master faces experiment been duplicated against the leading commercial algorithms tested by NIST? Well, let’s look at the various ways you can define the “leading” commercial algorithms.
For example, here’s the view of the test set that IDEMIA would want you to see: the 1:N test sorted by the “Visa Border” column (results as of August 6, 2021):
Now you can play with the sort order in many different ways, but the question remains: have the Israeli researchers, or anyone else, performed a “master faces” test (preferably a 1:N test) on the IDEMIA, Paravision, Sensetime, NtechLab, Anyvision, or ANY other commercial algorithm?
Maybe a future study WILL conclude that even the leading commercial algorithms are vulnerable to master face attacks. However, until such studies are actually performed, we CANNOT conclude that commercial facial recognition algorithms are vulnerable to master face attacks.
So naturally journalists approach the results critically…not
But I’m sure that people are going to make those conclusions anyway.
While Matt Schneier doesn’t go to the extreme of saying that all facial recognition algorithms are now defunct, he does classify the research as “fascinating” WITHOUT commenting on its limitations or applicability. Schneier knows security, but he didn’t vet this one.
Gizmodo, on the other hand, breathlessly declares (in “‘Master Face’: Researchers Say They’ve Found a Wildly Successful Bypass for Face Recognition Tech”) that “you’d be safe to add (the study) to the growing body of literature that suggests facial recognition is bad news for everybody except cops and large corporations.” Apparently Gizmodo never read the NIST gender/race test results that I cited earlier.
Does anyone even UNDERSTAND these studies? (Or do they choose NOT to understand them?)
How can you avoid the same mistakes when communicating about biometrics?
As you can see, people often write about biometric topics without understanding them fully.
Even biometric companies sometimes have difficulty communicating about biometric topics in a way that laypeople can understand. (Perhaps that’s the reason why people misconstrue these studies and conclude that “all facial recognition is racist” and “any facial recognition system can be spoofed by a master face.”)
Are you about to publish something about biometrics that requires a sanity check? (Hopefully not literally, but you know what I mean.)
Well, why not turn to a biometric content marketing expert? Use the identity/biometric blog expert to write your blog post, the identity/biometric case study expert to write your case study, or the identity/biometric white paper expert to…well, you get the idea. (And all three experts are the same person!)