In this post I’m going to delve more into attribute-based access control (ABAC), comparing it to role-based access control (RBAC, or what Printrak BIS used), and directing you to a separate source that examines ABAC’s implementation.
(Delve. Yes, I said it. I told you I was temperamental. I may say more about the “d” word in a subsequent post.)
But first I’m going to back up a bit.
Role-based access control
As I noted in a LinkedIn post yesterday:
Back when I managed the Omnitrak and Printrak BIS products (now part of IDEMIA‘s MBIS), the cool kids used role-based access control.
My product management responsibilities included the data and application tours, so user permissions fell upon me. Printrak BIS included hundreds of specific permissions that governed its use by latent, tenprint, IT, and other staff. But when a government law enforcement agency onboarded a new employee, it would take forever to assign the hundreds of necessary permissions to the new hire.
Enter roles, as a part of role-based access control (RBAC).
If we know, for example, that the person is a latent trainee, we can assign the necessary permissions to a “latent trainee” role.
- The latent trainee would have permission to view records and perform primary latent verification.
- The latent trainee would NOT have permission to delete records or perform secondary latent verification.
As the trainee advanced, their role could change from “latent trainee” to “latent examiner” and perhaps to “latent supervisor” some day. One simple change, and all the proper permissions are assigned.
But what of the tenprint examiner who expresses a desire to do latent work? That person can have two roles: “tenprint examiner” and “latent trainee.”
Role-based access control certainly eased the management process for Printrak BIS’ government customers.
But something new was brewing…
Attribute-based access control
As I noted in my LinkedIn post, the National Institute of Standards and Technology released guidance in 2014 (since revised). The document is NIST Special Publication 800-162, Guide to Attribute Based Access Control (ABAC) Definition and Considerations, and is available at https://doi.org/10.6028/NIST.SP.800-162.
Compared to role-based access control, attribute-based access control is a teeny bit more granular.
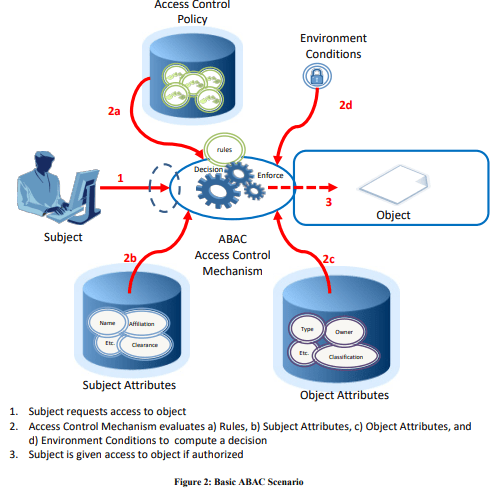
Attributes are characteristics of the subject, object, or environment conditions. Attributes contain information given by a name-value pair.
A subject is a human user or NPE, such as a device that issues access requests to perform operations on objects. Subjects are assigned one or more attributes. For the purpose of this document, assume that subject and user are synonymous.
An object is a system resource for which access is managed by the ABAC system, such as devices, files, records, tables, processes, programs, networks, or domains containing or receiving information. It can be the resource or requested entity, as well as anything upon which an operation may be performed by a subject including data, applications, services, devices, and networks.
An operation is the execution of a function at the request of a subject upon an object. Operations include read, write, edit, delete, copy, execute, and modify.
Policy is the representation of rules or relationships that makes it possible to determine if a requested access should be allowed, given the values of the attributes of the subject, object, and possibly environment conditions.
So before you can even start to use ABAC, you need to define your subjects and objects and everything else.
Frontegg provides some excellent examples of how ABAC is used in practical terms. Here’s a government example:
For example, a military officer may access classified documents only if they possess the necessary clearance, are currently assigned to a relevant project, and are accessing the information from a secure location.
While (in my completely biased opinion) Printrak BIS was the greatest automated fingerprint identification system of its era, it couldn’t do anything like THAT. A Printrak BIS user could have a “clearance” role, but Printrak BIS had no way of knowing whether a person is assigned to an appropriate project or case, and Printrak BIS’ location capabilities were rudimentary at best. (If I recall correctly, we had some capability to restrict operations to particular computer terminals.)
As you can see, ABAC goes far beyond whether a PERSON is allowed to do things. It recognizes that people may be allowed to do things, but only under certain circumstances.
Implementing attribute-based access control
As I noted, it takes a lot of front-end work to define an ABAC implementation. I’m not going to delve into that complexity, but Gabriel L. Manor did, touching upon topics such as:
- Policy as Code
- Unstructured vs. Structured Rules
- Policy configuration using the Open Policy Administration Layer (OPAL)
You can read Manor’s thoughts here (“How to Implement Attribute-Based Access Control (ABAC) Authorization?“).
And there are probably ways to simplify some of this.