Looks complete to you, doesn’t it? Well, it isn’t. To, um, identify the missing bit of information that is both PII and PHI, take a look at this LinkedIn post from Jack Appleby. (Thanks to packaging expert Mark Wilson for bringing this post to my attention.)
“A dream brand just sent me a gift package & invite… but they broke the two most important rules of influencer gifting…
“The package was a ridiculously cool collab hoodie + an invite to an event I’ve wanted to go to since I was just a little kid… but the hoodie is a medium… and I’m an XL… and my name was spelled wrong on the invitation.”
And no, I’m not talking about Jack Appleby’s name.
I’M TALKING ABOUT HIS HOODIE SIZE.
And yes, hoodie size in combination with other information is both PII (personally identifiable information) and PHI (protected health information). If your hoodie size is XXL, but your height is only 5’1”…that has some health implications.
Yet at the same time it’s also vital business information. It’s collected from prospects and new employees at trade shows and during employee onboarding. And as Appleby’s example shows, there are potentially severe consequences if you get it wrong.
But does your favorite compliance framework include specific and explicit clauses addressing hoodie size? I bet it doesn’t. And that could be a huge privacy hole.
(The hoodie in my selfie is from my 2022-2023 employer. And yes I still wear it. But I got rid of my IDEMIA, MorphoTrak, Motorola, and Printrak attire.)
The most widely known member of the suite is SOC 2® – SOC for Service Organizations: Trust Services Criteria. But you also have SOC 1, SOC 3, SOC for Cybersecurity, SOC for Supply Chain, SOC for Steak…whoops, I made that one up because I’m hungry as I write this. But the others are real.
Who runs the SOC suite
But the difference about the SOC suite is that it’s not governed by engineers or scientists or academics.
I’m talking about the AICPA, or the Association of International Certified Professional Accountants.
Which begs the question: why are a bunch of bean counters defining compliance frameworks for cybersecurity?
Why CPAs run the SOC suite
Ask Schneider Downs. As an accounting firm, they may have an obvious bias regarding this question. But their answers are convincing.
“CPAs are subject matter experts in risk management.” You see, my reference above to “bean counters” was derogatory and simplistic. Accounts need to understand financial data and the underlying risks, including vulnerabilities in cash flow, debt, and revenue. For example, if you’ve ever talked to a CxO, you know that revenue is never guaranteed.
“It was a natural progression to go from auditing against financial risk to auditing against cybersecurity risk.” Now this may seem odd on the surface, because you wouldn’t think mad Excel skills will help you detect deepfakes. But ignore the tools for a moment and look at a higher levels. Because of their risk management expertise, they can apply that knowledge to other types of risk, including non-financial ones. As Schneider Downs goes on to say…
“CPAs understand internal control concepts and the appropriate evidence required to support the operating effectiveness of controls.” You need financial controls at your company. You aren’t going to let the summer intern sign multi-million dollar checks. In the same way you need to identify and evaluate the internal controls related to the Trust Services Criteria (TSC) associated with SOC 2: security, availability, processing integrity, confidentiality, and privacy.
So that’s why the accountants are running your SOC 2 audit.
And don’t try to cheat when you pay them for the audit.
And one more thing
A few of you may have detected that the phrase “SOC it to me” is derived from a popular catchphrase from the old TV show Rowan & Martin’s Laugh-In.
This week, well-known privacy advocate Alvaro Bedoya is not happy.
““The president just illegally fired me. This is corruption plain and simple,” Bedoya, who was appointed [to the Federal Trade Commission] in 2021 by President Joe Biden and confirmed in May 2022, posted on X.
“He added, “The FTC is an independent agency founded 111 years ago to fight fraudsters and monopolists” but now “the president wants the FTC to be a lapdog for his golfing buddies.””
The other ousted FTC Commissioner, Rebecca Kelly Slaughter, had been appointed by…Donald Trump.
In business, it is best to use a three-legged stool.
A two-legged stool obviously tips over, and you fall to the ground.
A four-legged stool is too robust for these cost-conscious days, where the jettisoning of employees is policy at both the private and public level.
But a three-legged stool is just right, as project managers already know when they strive to balance time, cost, and quality.
Perhaps the three-legged stool was in the back of Yunique Demann’s mind when she wrote a piece for the Information Systems Audit and Control Association (ISACA) entitled “The New Triad of AI Governance: Privacy, Cybersecurity, and Legal.” If you only rely on privacy and cybersecurity, you will fall to the ground like someone precariously balanced on a two-legged stool.
“As AI regulations evolve globally, legal expertise has become a strategic necessity in AI governance. The role of legal professionals now extends beyond compliance into one that is involved in shaping AI strategy and legally addressing ethical considerations…”
Discovered a song about privacy (by John Maus) and had to create a reel that used the song. Note the mDL privacy-preserving features toward the end of the reel.
He had purchased a feature-rich home security system and received an alarm while he was traveling. That’s all—an alarm, with no context.
“The security company then asked me, ‘Should we dispatch the police?’ At that moment, the reality hit: I was expected to make a decision that could impact my family’s safety, and I had no information to base that decision on. It was a gut-wrenching experience. The very reason I invested in security—peace of mind—had failed me.”
I’ve discussed identity and privacy regarding people.
I’ve discussed identity and privacy regarding non-person entities.
But I missed something in between.
Earlier this week I was discussing a particular veterinary software use case with an undisclosed person when I found myself asking how the data processing aspects of the use case complied with HIPAA, the U.S. Health Insurance Portability and Accountability Act.
Then I caught myself, realizing that HIPAA (previously discussed here) does not apply to dogs, cats, cows, or other animals. They are considered property, and we all know how U.S. laws have treated property in the past.
So you can violate an animal’s privacy all you want and not run afoul of HIPAA.
But you could run afoul of some other law. As Barb Rand noted back in 2013, 35 states (at the time) had “statutes that address the confidentiality of veterinary patient records.”
And when animal records are commingled with human records—for example, for emotional support animals—protected health information rules do kick in.
Unless the animal is intelligent enough to manage their own prescriptions without human assistance.
When I interact with the worldwide company NEC, I am usually dealing with automated biometric identification systems (ABIS).
Of course, ABIS is only a small part of what NEC does. It’s also involved in healthcare.
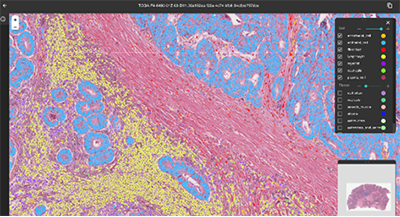
Consider…artificial intelligence and deep learning-powered digital pathology (“a field involving the digitization and computational analysis of pathology slides”).
“NEC Corporation (NEC; TSE: 6701) and Biomy, Inc. (Biomy) have signed a Memorandum of Understanding (MoU) for a joint marketing partnership to develop and expand artificial intelligence/deep learning (AI/DL)-based analytical platforms in the field of digital pathology. Through this partnership, the two companies aim to promote precision medicine for cancer patients and contribute to the advancement of the healthcare industry.”
So what is Biomy contributing?
“Biomy, which aims to realize personalized medicine through pathological AI technology, has developed DeepPathFinder™, a proprietary, cloud-based, AI/DL automated digital pathology analytical platform.”
And NEC?
“NEC has positioned healthcare and life sciences as a core pillar of its growth strategy. With a strong foundation in image analysis and other AI technologies, NEC has a long history of providing medical information systems such as electronic medical records to healthcare institutions.”
As I’ve said before, healthcare must deal with privacy concerns (protected health information, or PHI) similar to those NEC addresses in its other biometric product line (personally identifiable information, or PII). I personally can’t do nefarious things if I fraudulently acquire your digital pathology slide, but some bad actors could. Presumably the Biomy product is well protected.
Thinking about “de plane” used in the Fantasy Island television series (image CC BY-SA 3.0) makes me think about travel. Mr. Roarke’s and Tattoo’s guests didn’t have to worry about identifying themselves to disembark from the plane and enter the island. But WE certainly do…and different countries and entities need to adopt standards to facilitate this.
I’ve previously observed that standards often don’t emerge, like Athena, from ivory towers. They emerge when a very powerful entity or person (for example, Microsoft or Taylor Swift) says that THIS is the standard, and waits for the world to comply.
Of course, there can be issues when MULTIPLE powerful entities or people try to champion competing standards.
SITA, the global leader in air transport technology, and IDEMIA Public Security, a world leader in digital technologies, biometrics, and security have announced a collaboration to advance interoperability, trust, and data security through a globally recognized Digital Travel Ecosystem.
Add Indico to the partnership, and perhaps the parties may be on to something.
The goal is to create “an open, secure, and interoperable framework that ensures a travelers’ digital identity is trusted globally, without the need for direct integrations between issuers and verifiers.” It is intentionally decentralized, giving the traveler control over their identity.
Perhaps it’s a fantasy to think that others will buy in. Will they?
Consulting firms (and other firms) make a big deal about the amazing processes we use when we onboard clients. (In Bredemarket’s case, I ask questions.)
But often we don’t talk about what we do when we OFFBOARD clients. And that’s equally important.
So let’s go inside the wildebeest habitat and see how Bredemarket handles client offboarding.
In 2023 I signed a contract with a client in which I would bill them at an hourly rate. This was a short-term contract, but it was subsequently renewed.
Recently the client chose not to renew the contract for another extended period.
On the surface, that would appear to be the end of it. I had completed all projects assigned to me, and I had been paid for all projects assigned to me.
So what could go wrong?
(Don’t) Tell all the people
Plenty could go wrong.
During the course of my engagement with the client, I had enjoyed access to:
Confidential information FROM the client.
Confidential information that I sent TO the client, as part of the work for hire arrangement.
Access to client systems. (In this particular instance I only had access to a single system with non-confidential information, but other clients have granted me access to storage systems and even software.)
And all of this data was sitting in MY systems, including three storage systems, one CRM system, and one email system.
By Unnamed photographer for Office of War Information. – U.S. Office of War Information photo, via Library of Congress website [1], converted from TIFF to .jpg and border cropped before upload to Wikimedia Commons., Public Domain, https://commons.wikimedia.org/w/index.php?curid=8989847.
Now of course I had signed a non-disclosure agreement with the client, so I legally could not use any of that data even if I wanted to do so.
But the data was still sitting there, and I had to do something about it.
Take It As It Comes
But I already knew what I had to do, because I had done this before.
Long-time readers of the Bredemarket blog will recall an announcement that I made on April 22, 2022, in which I stated that I would no longer “accept client work for solutions that identify individuals using (a) friction ridges (including fingerprints and palm prints) and/or (b) faces.” (I also stopped accepting work for solutions involving driver’s licenses and passports.)
I didn’t say WHY I was refusing this work; I saved that tidbit for a mailing to my mailing list.
So, why I am making these changes at Bredemarket?
I have accepted a full-time position as a Senior Product Marketing Manager with an identity company. (I’ll post the details later on my personal LinkedIn account…)…
If you are a current Bredemarket customer with a friction ridge/face identification solution, then I already sent a communication to you with details on wrapping up our business. Thank you for your support over the last 21 months. I’ll probably see you at the conferences that my employer-to-be attends.
That communication to then-current Bredemarket customers detailed, among other things, how I was going to deal with the confidential information I held from them.
So I dusted off the pertinent parts of that communication and repurposed it to send to my 2023-2024 client. I’ve reproduced non-redacted portions of that communication below. Although I don’t explicitly name my information storage systems in this public post, as I noted above these include three storage systems, one CRM system, and one email system.
Bredemarket will follow the following procedures to protect your confidential information.
Bredemarket will delete confidential information provided to Bredemarket by your company by (REDACTED). This includes information presently stored on (REDACTED).
Bredemarket will delete draft and final documents created by Bredemarket that include company confidential information by (REDACTED). This includes information presently stored on (REDACTED).
If your company has provided Bredemarket with access to your company OneDrive, Outlook, or Sites, Bredemarket will delete the ability to access these company properties by (REDACTED). This includes deletion from my laptop computer, my mobile phone, and my web browser. Bredemarket further recommends that you revoke Bredemarket’s access to these systems.
If your company has provided Bredemarket with access to all or part of your company Google Drive, Bredemarket recommends that you revoke Bredemarket’s access to this system.
I will inform you when this process is complete.
So I executed the offboarding process for my former client, ensuring that the client’s confidential information remains protected.
Love Me Two Times
Of course, I hope the client comes back to Bredemarket someday, in some capacity.
But perhaps you can take advantage of the opportunity. Since your competitor no longer contracts with Bredemarket, perhaps YOU can.
To learn WHY you should work with Bredemarket, click the image below and read about my CPA (Content-Proposal-Analysis) expertise.
Bredemarket’s “CPA.”
Postscript
No, I’m not going to post videos of the relevant Doors songs on here. Jim’s Oedpidal complex isn’t business-friendly.