The COVID-19 pandemic may be a fading memory, but contactless biometrics remains popular.
Back in the 1980s, you had to touch something to get the then-new “livescan” machines to capture your fingerprints. While you no longer had messy ink-stained fingers, you still had to put your fingers on a surface that a bunch of other people had touched. What if they had the flu? Or AIDS (the health scare of that decade)?
As we began to see facial recognition in the 1990s and early 2000s, one advantage of that biometric modality was that it was CONTACTLESS. Unlike fingerprints, you didn’t have to press your face against a surface.
“Actually this effort launched before that, as there were efforts in 2004 and following years to capture a complete set of fingerprints within 15 seconds…”
This WAS an unusual question, considering that it took a minute or more to capture inked prints or livescan prints. And the government expected this to happen in 15 seconds?
A decade later several companies were pursuing this in conjunction with NIST. There were two solutions: dedicated kiosks such as MorphoWave from my then-employer MorphoTrak, and solutions that used a standard smartphone camera such as SlapShot from Sciometrics and Integrated Biometrics.
The, um, upshot is that now contactless fingerprint and face capture are both a thing. Contactless capture provides speed, and even the impossible 15 second capture target was blown away.
Fingers and faces can be captured “on the move” in airports, border crossings, stadiums, and university lunchrooms and other educational facilities.
Perhaps Iris and voice can be considered contactless and fast.
A little (just a little) behind the scenes of why I write what I write.
What does TPRM mean?
I was prompted to write my WYSASOA post when I encountered a bunch of pages on a website that referred to TPRM, with no explanation.
Now if I had gone to the home page of that website, I would have seen text that said “Third Party Risk Management (TPRM).”
But I didn’t go to the home page. I entered the website via another page and therefore never saw the home page explanation of what the company meant by the acronym.
Unless you absolutely know that everybody in the world agrees on your acronym definition, always spell out the first instance of an acronym on a piece of content. So if you mention that acronym on 10 web pages, spell it out on all 10 of them.
That’s all I wanted to say…
How is NIST related to TPRM?
…I lied.
Because now I assume you want to know what Third Party Risk Management (TPRM) actually is.
Let’s go to my esteemed friends at the National Institute of Standards & Technology, or NIST.
When companies began extensively outsourcing and globalizing the supply chain in the 1980’s and 1990’s, they did so without understanding the risks suppliers posed. Lack of supplier attention to quality management could compromise the brand. Lack of physical or cybersecurity at supplier sites could result in a breach of corporate data systems or product corruption. Over time, companies have begun implementing vendor management systems – ranging from basic, paper-based approaches to highly sophisticated software solutions and physical audits – to assess and mitigate vendor risks to the supply chain.
Because if MegaCorp is sharing data with WidgetCorp, and WidgetCorp is breached, MegaCorp is screwed. So MegaCorp has to reduce the risk that it’s dealing with breachable firms.
The TPRM problem
And it’s not just my fictional MegaCorp. Cybersecurity risks are obviously a problem. I only had to go back to January 26 to find a recent example.
Bank of America has confirmed a data breach involving a third-party software provider that led to the exposure of sensitive customer data.
What Happened: According to a filing earlier this month, an unidentified third-party software provider discovered unauthorized access to its systems in October. The breach did not directly impact Bank of America’s systems, but the data of at least 414 customers is now at risk.
The breach pertains to mortgage loans and the compromised data includes customers’ names, social security numbers, addresses, phone numbers, passport numbers, and loan numbers.
Note that the problem didn’t occur at Bank of America’s systems, but at the systems of some other company.
Manage your TPRM…now that you know what I mean by the acronym.
“So depending upon your needs, you can argue that”
This frame was followed by three differing answers to the “Where is ByteDance From?” question.
But isn’t there only one answer to the question? How can there be three?
It all depends upon your needs.
Who is the best age estimation vendor?
I shared an illustrative example of this last year. When the National Institute of Standards and Technology (NIST) tested its first six age estimation algorithms, it published the results for everyone to see.
“Because NIST conducts so many different tests, a vendor can turn to any single test in which it placed first and declare it is the best vendor.
“So depending upon the test, the best age estimation vendor (based upon accuracy and or resource usage) may be Dermalog, or Incode, or ROC (formerly Rank One Computing), or Unissey, or Yoti. Just look for that “(1)” superscript….
“Out of the 6 vendors, 5 are the best. And if you massage the data enough you can probably argue that Neurotechnology is the best also.
“So if I were writing for one of these vendors, I’d argue that the vendor placed first in Subtest X, Subtest X is obviously the most important one in the entire test, and all the other ones are meaningless.”
Are you the best? Only if I’m writing for you
I will let you in on a little secret.
When I wrote things for IDEMIA, I always said that IDEMIA was the best.
When I wrote things for Incode, I always said that Incode was the best.
And when I write things for each of my Bredemarket clients, I always say that my client is the best.
I recently had to remind a prospect of this fact. This particular prospect has a very strong differentiator from its competitors. When the prospect asked for past writing samples, I included this caveat:
“I have never written about (TOPIC 1) or (TOPIC 2) from (PROSPECT’S) perspective, but here are some examples of my writing on both topics.”
I then shared four writing samples, including something I wrote for my former employer Incode about two years ago. I did this knowing that my prospect would disagree with my assertions that Incode’s product is so great…and greater than the prospect’s product.
If this loses me the business, I can accept that. Anyone with any product marketing experience in the identity industry is guaranteed to have said SOMETHING offensive to most of the 80+ companies in the industry.
How do I write for YOU?
But let’s say that you’re an identity firm and you decide to contract with Bredemarket anyway, even though I’ve said nice things about your competitors in the past.
How do we work together to ensure that I say nice things about you?
By the time we’re done, we have hopefully painted a hero picture of your company, describing why you are the preferred solution for your customers—better than IDEMIA, Incode, or anyone else.
(Unless of course IDEMIA or Incode contracts with Bredemarket, in which case I will edit the sentence above just a bit.)
So let’s talk
If you would like to work with Bredemarket for differentiated content, proposal, or analysis work, book a free meeting on my “CPA” page.
Then I started talking about some of the post-contract signature tests in the automated biometric identification system world, including factory acceptance tests and site acceptance tests.
These tests are not unique to ABIS. Healthcare (the other biometric) conducts FAT and SAT also, as Powder Systems notes.
“When manufacturing complex machinery in industries such as pharmaceuticals or fine chemicals, extensive equipment testing must be carried out before commissioning.
“It requires thorough functional, performance, and safety tests of intricate systems. These may comprise many components and interdependencies. Challenging though it may be, these must be systematically assessed before they’re put into operation. This approach is broadly known as acceptance testing.
“There are many forms of acceptance testing. Two closely related approaches that often come in for confusion are Factory Acceptance Testing (FAT) and Site Acceptance Testing (SAT). Both are critical stages in the verification and validation of equipment and systems within industrial and manufacturing contexts. However, they differ significantly in terms of location, timing, purpose, scope, participants, outcomes, and testing environment.”
You should read the entire article to learn about the significant differences between the two test types. But let me highlight one point:
“Factory acceptance testing typically involves a more rigorous and comprehensive testing process. This testing procedure includes the detailed verification of system components to ensure they function correctly and meet design specifications.”
This is based on the fact that it’s less costly to fix problems early at the factory than to fix them later out in the field.
Whether you’re testing pharmaceutical machinery or ABIS, both factory and site acceptance tests are absolutely critical. Skipping one of the two tests does not save costs.
As I’ve mentioned before, when the National Institute of Standards and Technology (NIST) tests biometric modalities such as finger and face, they conduct each test in a bunch of different ways.
But NIST doesn’t do this just to make the vendors happy. NIST does this because biometrics are used in many, many ways.
Let’s look at recent age estimation testing, which currently tests 15 algorithms rather than the original 6.
Governments and private entities can estimate ages for people at the pub, people buying weed, or people gambling. And then there’s the use case that is getting a lot of attention these days—people accessing social media.
Child Online Safety, Ages 13-16 (in my country anyway)
When NIST conceived the age estimation tests, the social media providers generaly required their users to be 13 years of age or older. For this reason, one of NIST’s age estimation tests focused upon whether age estimation algorithms could reliably identify those who were 13 years old vs. those who were not.
Age 8-12 – False Positive Rates (FPR) are proportions of subjects aged 8 to 12 but whose age is estimated from 13 to 16 (below 17).
This covers the case in which a social media provider requires people to be 13 years old or older, someone between 8 and 12 tries to sign up for the social media service anyway…AND SUCCESSFULLY DOES SO.
You want the “false positive rate” to be as low as possible in this case, so that’s what NIST measures.
As of December 10, the best performing algorithm of the 15 tested had a false positive rate (FPR) of 0.0467. The second was close at 0.0542, with the third at 0.0828.
The 15th was a distant last at 0.2929.
But the worst-tested algorithm is much better on other tests
But before you conclude that the 15th algorithm in the “8-12” test is a dud, take a look at how that same algorithm performed on some of the OTHER age estimation tests.
For the age 17-22 test (“False Positive Rates (FPR) are proportions of subjects aged 17 to 22 but whose age is estimated from 13 to 16 (below 17)”), this algorithm was the second MOST accurate.
And the algorithm is pretty good at correctly classifying 13-16 year olds.
It also performs well in the “challenge 25” tests (addressing some of the use cases I mentioned above such as alcohol purchases).
So it looks like this particular algorithm doesn’t (currently) do well with kids, but it does VERY well with adults.
So before you use the NIST tests as a starting point to determine if an algorithm is good for you, make sure you evaluate the CORRECT test, including the CORRECT data.
In “On Attribute-Based Access Control,” I noted that NIST defined a subject as “a human user or NPE (Non-Person Entity), such as a device that issues access requests to perform operations on objects.” Again, there’s a need to determine that the NPE has the right attributes, and is not a fake, deep or shallow.
There’s clearly a need to identify non-person entities. If I work for IBM and have a computer issued by IBM, the internal network needs to know that this is my computer, and not the computer of a North Korean hacker.
But I was curious. Can the five (or six) factors identify non-person entities?
Let’s consider factor applicability, going from the easiest to the hardest.
The easy factors
Somewhere you are. Not only is this extremely applicable to non-person entities, but in truth this factor doesn’t identify persons, but non-person entities. Think about it: a standard geolocation application doesn’t identify where YOU are. It identities where YOUR SMARTPHONE is. Unless you have a chip implant, there is nothing on your body that can identify your location. So obviously “somewhere you are” applies to NPEs.
Something you have. Another no brainer. If a person has “something,” that something is by definition an NPE. So “something you have” applies to NPEs.
Something you do. NPEs can do things. My favorite example is Kraftwerk’s pocket calculator. You will recall that “by pressing down this special key it plays a little melody.” I actually had a Casio pocket calculator that did exactly that, playing a tune that is associated with Casio. Later, Brian Eno composed a startup sound for Windows 95. So “something you do” applies to NPEs. (Although I’m forced to admit that an illegal clone computer and operating system could reproduce the Eno sound.)
Something you know. This one is a conceptual challenge. What does an NPE “know”? For artificial intelligence creations such as Kwebbelkop AI, you can look at the training data used to create it and maintain it. For a German musician’s (or an Oregon college student’s) pocket calculator, you can look at the code used in the device, from the little melody itself to the action to take when the user enters a 1, a plus sign, and another 1. But is this knowledge? I lean toward saying yes—I can teach a bot my mother’s maiden name just as easily as I can teach myself my maiden name. But perhaps some would disagree.
Something you are. For simplicity’s sake, I’ll stick to physical objects here, ranging from pocket calculators to hand-made ceramic plates. The major reason that we like to use “something you are” as a factor is the promise of uniqueness. We believe that fingerprints are unique (well, most of us), and that irises are unique, and that DNA is unique except for identical twins. But is a pocket calculator truly unique, given that the same assembly line manufactures many pocket calculators? Perhaps ceramic plates exhibit uniqueness, perhaps not.
That’s all five factors, right?
Well, let’s look at the sixth one.
Somewhat you why
You know that I like the “why” question, and some time ago I tried to apply it to identity.
Why is a person using a credit card at a McDonald’s in Atlantic City? (Link) Or, was the credit card stolen, or was it being used legitimately?
Why is a person boarding a bus? (Link) Or, was the bus pass stolen, or was it being used legitimately?
Why is a person standing outside a corporate office with a laptop and monitor? (Link) Or, is there a legitimate reason for an ex-employee to gain access to the corporate office?
The first example is fundamental from an identity standpoint. It’s taken from real life, because I had never used any credit card in Atlantic City before. However, there was data that indicated that someone with my name (but not my REAL ID; they didn’t exist yet) flew to Atlantic City, so a reasonable person (or identity verification system) could conclude that I might want to eat while I was there.
But can you measure intent for an NPE?
Does Kwebbelkop AI have a reason to perform a particular activity?
Does my pocket calculator have a reason to tell me that 1 plus 1 equals 3?
Does my ceramic plate have a reason to stay intact when I drop it ten meters?
In this post I’m going to delve more into attribute-based access control (ABAC), comparing it to role-based access control (RBAC, or what Printrak BIS used), and directing you to a separate source that examines ABAC’s implementation.
(Delve. Yes, I said it. I told you I was temperamental. I may say more about the “d” word in a subsequent post.)
My product management responsibilities included the data and application tours, so user permissions fell upon me. Printrak BIS included hundreds of specific permissions that governed its use by latent, tenprint, IT, and other staff. But when a government law enforcement agency onboarded a new employee, it would take forever to assign the hundreds of necessary permissions to the new hire.
Enter roles, as a part of role-based access control (RBAC).
If we know, for example, that the person is a latent trainee, we can assign the necessary permissions to a “latent trainee” role.
The latent trainee would have permission to view records and perform primary latent verification.
The latent trainee would NOT have permission to delete records or perform secondary latent verification.
As the trainee advanced, their role could change from “latent trainee” to “latent examiner” and perhaps to “latent supervisor” some day. One simple change, and all the proper permissions are assigned.
But what of the tenprint examiner who expresses a desire to do latent work? That person can have two roles: “tenprint examiner” and “latent trainee.”
Role-based access control certainly eased the management process for Printrak BIS’ government customers.
But something new was brewing…
Attribute-based access control
As I noted in my LinkedIn post, the National Institute of Standards and Technology released guidance in 2014 (since revised). The document is NIST Special Publication 800-162, Guide to Attribute Based Access Control (ABAC) Definition and Considerations, and is available at https://doi.org/10.6028/NIST.SP.800-162.
Compared to role-based access control, attribute-based access control is a teeny bit more granular.
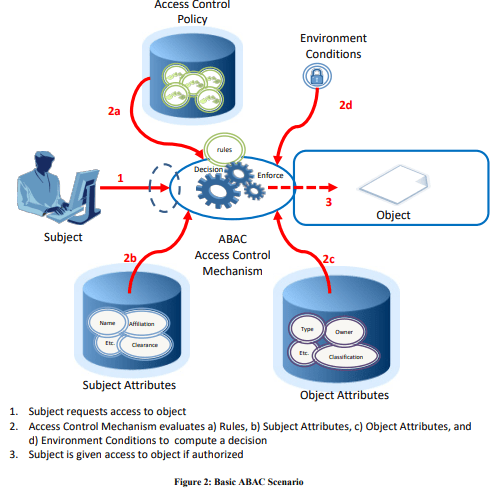
Attributes are characteristics of the subject, object, or environment conditions. Attributes contain information given by a name-value pair.
A subject is a human user or NPE, such as a device that issues access requests to perform operations on objects. Subjects are assigned one or more attributes. For the purpose of this document, assume that subject and user are synonymous.
An object is a system resource for which access is managed by the ABAC system, such as devices, files, records, tables, processes, programs, networks, or domains containing or receiving information. It can be the resource or requested entity, as well as anything upon which an operation may be performed by a subject including data, applications, services, devices, and networks.
An operation is the execution of a function at the request of a subject upon an object. Operations include read, write, edit, delete, copy, execute, and modify.
Policy is the representation of rules or relationships that makes it possible to determine if a requested access should be allowed, given the values of the attributes of the subject, object, and possibly environment conditions.
So before you can even start to use ABAC, you need to define your subjects and objects and everything else.
Frontegg provides some excellent examples of how ABAC is used in practical terms. Here’s a government example:
For example, a military officer may access classified documents only if they possess the necessary clearance, are currently assigned to a relevant project, and are accessing the information from a secure location.
While (in my completely biased opinion) Printrak BIS was the greatest automated fingerprint identification system of its era, it couldn’t do anything like THAT. A Printrak BIS user could have a “clearance” role, but Printrak BIS had no way of knowing whether a person is assigned to an appropriate project or case, and Printrak BIS’ location capabilities were rudimentary at best. (If I recall correctly, we had some capability to restrict operations to particular computer terminals.)
As you can see, ABAC goes far beyond whether a PERSON is allowed to do things. It recognizes that people may be allowed to do things, but only under certain circumstances.
Implementing attribute-based access control
As I noted, it takes a lot of front-end work to define an ABAC implementation. I’m not going to delve into that complexity, but Gabriel L. Manor did, touching upon topics such as:
Policy as Code
Unstructured vs. Structured Rules
Policy configuration using the Open Policy Administration Layer (OPAL)
Any endeavor, scientific or non-scientific, tends to generate a host of acronyms that the practitioners love to use.
For people interested in fingerprint identification, I’ve written this post to delve into some of the acronyms associated with NIST MINEX testing, including ANSI, INCITS, FIPS, and PIV.
NIST was involved with fingerprints before NIST even existed. Back when NIST was still the NBS (National Bureau of Standards), it issued its first fingerprint interchange standard back in 1986. I’ve previously talked about the 1993 version of the standard in this post, “When 250ppi Binary Fingerprint Images Were Acceptable.”
But let’s move on to another type of interchange.
MINEX
It’s even more important that we define MINEX, which stands for Minutiae (M) Interoperability (IN) Exchange (EX).
You’ll recall that the 1993 (and previous, and subsequent) versions of the ANSI/NIST standard included a “Type 9” to record the minutiae generated by the vendor for each fingerprint. However, each vendor generated minutiae according to its own standard. Back in 1993 Cogent had its standard, NEC its standard, Morpho its standard, and Printrak its standard.
So how do you submit Cogent minutiae to a Printrak system? There are two methods:
First, you don’t submit them at all. Just ignore the Cogent minutiae, look at the Printrak image, and use an algorithm regenerate the minutiae to the Printrak standard. While this works with high quality tenprints, it won’t work with low quality latent (crime scene) prints that require human expertise.
The second method is to either convert the Cogent minutiae to the Printrak minutiae standard, or convert both standards into a common format.
The American National Standards Institute (ANSI) is a private, non-profit organization that administers and coordinates the U.S. voluntary standards and conformity assessment system. Founded in 1918, the Institute works in close collaboration with stakeholders from industry and government to identify and develop standards- and conformance-based solutions to national and global priorities….
ANSI is not itself a standards developing organization. Rather, the Institute provides a framework for fair standards development and quality conformity assessment systems and continually works to safeguard their integrity.
So ANSI, rather than creating its own standards, works with outside organizations such as NIST…and INCITS.
INCITS
Now that’s an eye-catching acronym, but INCITS isn’t trying to cause trouble. Really, they’re not. Believe me.
Back in 2004, INCITS worked with ANSI (and NIST, who created samples) to develop three standards: one for finger images (ANSI INCITS 381-2004), one for face recognition (ANSI INCITS 385-2004), and one for finger minutiae (ANSI INCITS 378-2004, superseded by ANSI INCITS 378-2009 (S2019)).
When entities used this vendor-agnostic minutiae format, then minutiae from any vendor could in theory be interchanged with those from any other vendor.
This came in handy when the FIPS was developed for PIV. Ah, two more acronyms.
FIPS and PIV
One year after the three ANSI INCITS standards were released, this happened (the acronyms are defined in the text):
Federal Information Processing Standard (FIPS) 201 entitled Personal Identity Verification of Federal Employees and Contractors establishes a standard for a Personal Identity Verification (PIV) system (Standard) that meets the control and security objectives of Homeland Security Presidential Directive-12 (HSPD-12). It is based on secure and reliable forms of identity credentials issued by the Federal Government to its employees and contractors. These credentials are used by mechanisms that authenticate individuals who require access to federally controlled facilities, information systems, and applications. This Standard addresses requirements for initial identity proofing, infrastructure to support interoperability of identity credentials, and accreditation of organizations issuing PIV credentials.
So the PIV, defined by a FIPS, based upon an ANSI INCITS standard, defined a way for multiple entities to create and support fingerprint minutiae that were interoperable.
But how do we KNOW that they are interoperable?
Let’s go back to NIST and MINEX.
Testing interoperability
So NIST ended up in charge of figuring out whether these interoperable minutiae were truly interoperable, and whether minutiae generated by a Cogent system could be used by a Printrak system. Of course, by the time MINEX testing began Printrak no longer existed, and a few years later Cogent wouldn’t exist either.
You can read the whole history of MINEX testing here, but for now I’m going to skip ahead to MINEX III (which occurred many years after MINEX04, but who’s counting?).
Like some other NIST tests we’ve seen before, vendors and other entities submit their algorithms, and NIST does the testing itself.
In this case, all submitters include a template generation algorithm, and optionally can include a template matching algorithm.
Then NIST tests each algorithm against every other algorithm. So the “innovatrics+0020” template generator is tested against itself, and is also tested against the “morpho+0115” algorithm, and all the other algorithms.
NIST then performs its calculations and comes up with summary values of interoperability, which can be sliced and diced a few different ways for both template generators and template matchers.
From NIST. Top 10 template generators (Ascending “Pooled 2 Fingers FNMR @ FMR≤10-2“) as of July 29, 2024.
And this test, like some others, is an ongoing test, so perhaps in a few months someone will beat Innovatrics for the top pooled 2 fingers spot.
Are fingerprints still relevant?
And entities WILL continue to submit to the MINEX III test. While a number of identity/biometric professionals (frankly, including myself) seem to focus on faces rather than fingerprints, fingers still play a vital role in biometric identification, verification, and authentication.
I remember the first computer I ever owned: a Macintosh Plus with a hard disk with a whopping 20 megabytes of storage space. And that hard disk held ALL my files, with room to spare.
For sake of comparison, the video at the end of this blog post would fill up three-quarters of that old hard drive. Not that the Mac would have any way to play that video.
And its 20 megabyte hard disk illustrates the limitations of those days. File storage was a precious commodity in the 1980s and 1990s, and we therefore accepted images that we wouldn’t even think about accepting today.
This affected the ways in which entities exchanged biometric information.
The 1993 ANSI/NIST standard
The ANSI/NIST standard for biometric data interchange has gone through several iterations over the years, beginning in 1986 when NIST didn’t even exist (it was called the National Bureau of Standards in those days).
Yes, FINGERPRINT information. No faces. No scars/marks/tattoos. signatures, voice recordings, dental/oral data, irises, DNA, or even palm prints. Oh, and no XML-formatted interchange either. Just fingerprints.
No logical record type 99, or even type 10
Back in 1993, there were only 9 logical record types.
For purposes of this post I’m going to focus on logical record types 3 through 6 and explain what they mean.
Type 3, Fingerprint image data (low-resolution grayscale).
Type 4, Fingerprint image data (high-resolution grayscale).
Type 5, Fingerprint image data (low-resolution binary).
Type 6, Fingerprint image data (high-resolution binary).
Image resolution in the 1993 standard
In the 1993 version of the ANSI/NIST standard:
“Low-resolution” was defined in standard section 5.2 as “9.84 p/mm +/- 0.10 p/mm (250 p/in +/- 2.5 p/in),” or 250 pixels per inch (250ppi).
The “high-resolution” definition in sections 5.1 and 5.2 was twice that, or “19.69 p/mm +/- 20 p/mm (500 p/in +/- 5 p/in.”
While you could transmit at these resolutions, the standard still mandated that you actually scan the fingerprints at the “high-resolution” 500 pixels per inch (500ppi) value.
Incidentally, this brings up an important point. The series of ANSI/NIST standards are not focused on STORAGE of data. They are focused on INTERCHANGE of data. They only provided a method for Printrak system users to exchange data with automated fingerprint identification systems (AFIS) from NEC, Morpho, Cogent, and other fingerprint system providers. Just interchange. Nothing more.
Binary and grayscale data in the 1993 standard
Now let’s get back to Types 3 through 6 and note that you were able to exchange binary fingerprint images.
Why the heck would fingerprint experts tolerate a system that transmitted binary images that latent fingerprint examiners considered practically useless?
Because they had to.
Storage and transmission constraints in 1993
Two technological constraints adversely affected the interchange of fingerprint data in 1993:
Storage space. As mentioned above, storage space was limited and expensive in the 1980s and the 1990s. Not everyone could afford to store detailed grayscale images with (standard section 4.2) “eight bits (256 gray levels)” of data. Can you imagine storing TEN ENTIRE FINGERS with that detail, at an astronomical 500 pixels per inch?
Transmission speed. There was another limitation enforced by the modems of the data. Did I mention that the ANSI/NIST standard was an INTERCHANGE standard? Well, you couldn’t always interchange your data via the huge 1.44 megabyte floppy disks of the day. Sometimes you had to pull your your trusty 14.4k or 28.8k modem and send the images over the telephone. Did you want to spend the time sending those huge grayscale images over the phone line?
So as a workaround, the ANSI/NIST standard allowed users to interchange binary (black and white) images to save disk space and modem transmission time.
And we were all delighted with the capabilities of the 1993 ANSI/NIST standard.
Until we weren’t.
The 2015 ANSI/NIST standard
The current standard, ANSI/NIST-ITL 1-2011 Update 2015, supports a myriad of biometric types. For fingerprints (and palm prints), the focus is on grayscale images: binary image Type 5 and Type 6 are deprecated in the current standard, and low-resolution Type 3 grayscale images are also deprecated. Even Type 4 is shunned by most people in favor of new friction ridge image types in which the former “high resolution” is now the lowest resolution that anyone supports:
Both the U.S. National Institute of Standards and Technology and the Digital Benefits Hub made important announcements this morning. I will quote portions of the latter announcement.
In response to heightened fraud and related cybersecurity threats during the COVID-19 pandemic, some benefits-administering agencies began to integrate new safeguards such as individual digital accounts and identity verification, also known as identity proofing, into online applications. However, the use of certain approaches, like those reliant upon facial recognition or data brokers, has raised questions about privacy and data security, due process issues, and potential biases in systems that disproportionately impact communities of color and marginalized groups. Simultaneously, adoption of more effective, evidence-based methods of identity verification has lagged, despite recommendations from NIST (Question A4) and the Government Accountability Office.
There’s a ton to digest here. This impacts a number of issues that I and others have been discussing for years.