There are some things that I don’t bother to share in the Bredemarket blog, but instead just share to my socials.
This morning, I shared a story about the third-party risk management firm Whistic to LinkedIn’s Bredemarket Technology Firm Services page.
From LinkedIn.
You can see an oft-used Bredemarket technique: rather than sharing everything from a third party (geddit?) article, I only share a bit of it, then encourage the reader to click on the link to see the rest of the content. Makes everybody happy. What could go wrong?
Then I shared the same story to Facebook’s Bredemarket Technology Firm Services page.
Or tried to.
First attempt to share to Facebook
Facebook removed the post, accusing me of using “misleading links or content to trick people.”
I’m so devious that even I couldn’t figure out what I did.
Until I re-read the post and noticed this parenthetical comment.
(And one more key finding. Read the article.)
Doesn’t seem like a trick to me, but I explicitly urged people to leave Facebook’s walled garden and read something.
I do this all the time—Facebook is the second most popular traffic source for Bredemarket, after Google—but apparently the way I did it in the Whistic post was a trick to Facebook’s readers.
Second attempt to share to Facebook
The solution was simple: repost the article WITHOUT the offensive parenthetical comment.
So I did.
And Facebook removed the post again.
This isn’t the first time Facebook has rejected content that other platforms accepted without question…including other Meta platforms such as Instagram, Threads, and WhatsApp.
I was this close to ceasing content sharing on Facebook altogether.
But then I had an idea.
Now I’m engaging in real trickery
If I am offending Zuck by using text to supposedly trick people into clicking on a link…
…what would happen if I ONLY posted a link with no text at all?
And rather than posting the text of interest in Facebook’s walled garden…
…I put the text of interest in the Bredemarket blog, along with the Whistic link that offended Facebook so much?
Then I could share it on character-limited platforms such as Threads and Bluesky.
You see the irony here. For a while I’ve strived to place social content natively on each platform. Now the platforms are forcing me to place the real content on a platform I control.
And the text would look something like this:
What I tried to say this morning
Every year, Whistic surveys hundreds of Risk-Management and Information Security leaders to understand the trends, challenges, and opportunities that are actively shaping the third-party risk management (TPRM) industry.
In 2025, the average company in our survey works with 286 vendors—up by 21% versus last year….That increased demand comes with increased risk.
[C]ompanies are spending more time, more money, and more resources on TPRM, but still not meeting their own risk standards or reducing security events.
I just read a post by SentinelOne, but it’s too early to tell if this is just a string of buzzwords or a legitimate endeavor.
The post about a proposed “Autonomous SOC Maturity Model” (ASOCMM?) includes buzzwords such as “autonomous,” “SOC” (system and organizational controls, or security operations center – take your pick), “agentic AI,” and of course “maturity model.”
Having done my maturity model time during my days at Motorola Solutions predecessor Motorola (although our group stuck with CMM rather then moving on to CMMI), I’ve certainly seen the benefits and drawbacks of maturity models for organizations large and small. Or for organizations large: I shudder at the thought of implementing a maturity model at a startup; the learning curve at the Printrak part of Motorola was bad enough. You need to hit the target between no process, and process for process’ sake.
So what of this autonomous SOC maturity model? Perhaps it can be real.
“At SentinelOne, we see the Autonomous SOC through the lens of a maturity model. We welcome debate on where we, as an industry, are on this evolutionary revolution. We hope most will agree that this is a better way to look at Autonomous SOC innovation and adoption – far better than the binary, all-or-nothing debates that have long fueled analyst, vendor, and industry watcher blogs and keynotes.”
If nothing else, a maturity model approach lends (or can lend) itself to continuous improvement, rather than just checking off a box and saying you’re done. A Level 5 (or Level 4 on a 0-4 scale) organization, if it believes what it’s saying, is ALWAYS going to improve.
Bredemarket promotes itself in all sorts of places. My LinkedIn newsletter is an example, but there are other places where Bredemarket speaks, including the Bredemarket blog and a number of social channels.
The channels that Bredemarket uses have varied over time. While wise minds such as Jay Clouse have recommended to not spread yourself thin, I ignored his advice and found myself expanding from LinkedIn to TikTok. (TikTok is a Chinese-owned social media platform. You may have heard of it.)
Then in May 2024 I contracted my online presence, announcing that I was retreating from some social channels “that have no subscribers, exhibit no interest, or yield no responses.” After I had shed some channels, I ended up on a basic list of Facebook, Instagram, LinkedIn, and Threads.
Now I may contract again, and I may expand again, but for now I want to touch upon the reasons why a business should post or not post on multiple social channels, and how the business can generate content for all those channels.
Why should you only post on a single social channel?
There is no right or wrong answer for every business, and there are some businesses that should only post on a single social channel.
If all your prospects are using a single social channel and are on NO OTHER channel, then you only need to post on that channel.
If you are NOT in danger of losing your account on that social channel because of some automated detection of a violation (“You violated one of the terms in our TOS. We won’t tell you which one. YOU figure it out.”), then you can continue to post on that channel and no other.
If the social channel is NOT in danger of business liquidation or forced government closure, then you can continue to post on that channel and no other.
Why should you post on multiple social channels?
Not all businesses satisfy all the criteria above. For one, your “hungry people” (target audience) may be dispersed among several social channels. From my personal experience, I know that some people only read Bredemarket content in my blog, some only read my content on LinkedIn, some only read my content on Facebook (yes, it’s true; one of Bredemarket’s long-term champions primarily engages with me on Facebook), some only on Instagram, and so forth.
What would happen if I decided to can most of my social channels and only post TikTok videos? I’d lose a lot of engagement and business.
Even if I concentrated on LinkedIn only, which seems like a logical tactic for a B2B service provider, I would lose out. Do you know how many people on Threads NEVER read LinkedIn? I don’t want to lose those people.
So that’s where I ended up. And if you know my system, the question after the “why” question is the “how” question…
How can you post on multiple social channels?
Repurposing…intelligently.
You don’t have to create completely unique content for every platform. You can adapt content for each platform, when it makes sense.
So now I’m going to eat my own wildebeest food and see where I can repurpose this text, which was originally a LinkedIn article. Yes, even on TikTok. I may not come up with a whopping 31 pieces of content like I did in a 2023 test, but I can certainly get this message out to people who hate LinkedIn. Perhaps maybe even to my mailing list, for people who have subscribed to the Bredemarket mailing list.
I haven’t figured out what I’ll do in this particular instance, but here are some general guidelines on content repurposing:
You can just copy and paste the entire piece of content on another platform. For example, I took all this text and copied it from the original LinkedIn article. But I hope I remembered to edit all the phrases that assume this content is posted on LinkedIn. And I’d have to consider something else…
You can just copy and paste the entire piece of content on another platform and remove the links. To be honest, no social media platform likes outbound links, but some platforms such as Instagram REALLY don’t like outbound links. So before you do this, ask if the content still makes sense if the links aren’t present.
You can provide a summary of the content and link back to the original content for more detail. Isolate the important points in the content, just publish those isolated points, and then link back to the original content if the reader wants more detail. Bear in mind that they probably won’t, because clicking on a link is one extra step that most people won’t want to do.
You can provide a really short summary of the content and link back to the original content for more detail. Bluesky and other Twitter wannabe platforms have character limitations, so often you have to really abridge the content to fit it in the platform. I’ve often written a “really short” version of my content for resharing, then discovered that even that version is too long for Bluesky.
You can address the content topic in an entirely different medium. Because of my preferences, I usually start with text and then develop an image and/or a video and/or audio that addresses the topic. But trust me—if I convert this blog post (yes, I rewrote the preceding three words when I copied this from the original LinkedIn article) into video or audio format, it will NOT include all the words you are reading here. Unless I’m feeling particularly cranky.
Oh, and if you’re using pictures with your content, don’t forget to adjust the pictures as needed. A 1920×1080 LinkedIn article image will NOT work on Instagram.
So there you have it. Posting on multiple social channels helps you reach people you may not otherwise reach, as long as you don’t spread yourself too thin or get discouraged. And you can repurpose content to fit within the expectations of each of these social channels, allowing you to re-use your content multiple times.
If you’ll excuse me, I have a lot of work to do. (Plus the usual Bredemarket services: I onboarded a new client yesterday and hope to onboard another one this week.)
In any large organization, the right hand doesn’t know what the left hand is doing.
On the morning of January 17—which mathematically inclined individuals know is 2 days before January 19, the potential de-Tik Tok day—a message on my personal Facebook feed encouraged me to feature my TikTok presence on my Bredemarket Facebook page.
Perhaps this is just a cruel joke. What if I were to do this and the link broke? “Shoulda stayed on Facebook, not that wimpy service.”
But it’s still mystifying that some Meta employee thought it was a good idea to risk diverting traffic to a non-Meta property.
First, the video is 3 minutes and 40 seconds long, which for me is long. And why you won’t see it on Bluesky or Instagram. But you will see it here; it’s already scheduled.
Oh, and I talk. The video alternates between shots of me at Bredemarket world headquarters and shots of textual/image descriptions incorporating Canva’s finest AI-generated music. If you’ve seen my other videos you know the…um…score.
I start by introducing the subject of “marketing and writing services” and identifying MY hungry people (target audience).
Then I explain, in detail, what Bredemarket’s “CPA” services are NOT…and what they ARE.
Then I do something that some sales professionals would NEVER do—reveal my pricing up front.
Finally, my call to action is for interested prospects to book a meeting with me on my CPA page. If you don’t already have the link to that page, you’ll get it on Monday.
Well, that’s that. Come back Monday at 8:00 am Pacific Standard Time / 1600 GMT.
My interests are admittedly niche (I created a YouTube video about it that most people won’t watch), but I’m still devoted to feeding the few who are also interested in this niche.
So if you’re interested in identity and technology content, ensure you’re following the Bredemarket blog and current social channels. They’ve changed since my original list and the May 2024 contraction, but…
in addition to the Bredemarket website, you can currently search for Bredemarket on Bluesky, Facebook, Instagram, LinkedIn, Threads, the aforementioned YouTube, a well-known site that may or may not disappear in the next three weeks, and other places.
I’m seeking a Senior Product Marketing Manager role in software (biometrics, government IDs, geolocation, identity and access management, cybersecurity, health) as an individual contributor on a collaborative team.
Key Accomplishments
Product launches (Confidential software product, Know Your Business offering, Morpho Video Investigator, MorphoBIS Cloud, Printrak BIS, Omnitrak).
Multiple enablement, competitive analysis, and strategy efforts.
Exploration of growth markets.
Multiple technologies.
Multiple industries.
Over 22 types of content.
Currently available for full-time employment or consulting work (Bredemarket).
I don’t know, I don’t believe in the word “legacy.” I just think that’s another word for ego. Legacy doesn’t mean nothing. It’s just some word everybody grabbed onto.
It means absolutely nothing to me. I’m just passing through. I’m going to die and it’s going to be over. Who cares about legacy after that?
We’re nothing. We’re just dead. We’re dust. We’re absolutely nothing. Our legacy is nothing.
With the life that Tyson has lived, it’s understandable why he’s echoing Ecclesiastes in this interview.
But you don’t have to have had Tyson’s experiences to realize that legacy does not last.
Neither wanted nor needed
In business (and in life), there are companies (and people) who don’t need you or want you.
This may be temporary. The company that doesn’t need you today may urgently (and importantly) need you tomorrow.
Or it may NOT be temporary. There are companies that will NEVER need you or want you.
I recently ran across three such companies that will never need Bredemarket.
Six weeks (now less than six weeks)
Six weeks, the still image version.
Perhaps you noticed Bredemarket’s “six weeks” promotion over the weekend. It was addressed to companies that may have a final project that they want to complete before the year ends in six weeks. (Now 5 1/2 weeks.) I emphasized that Bredemarket can help companies complete those content, proposal, and analysis projects.
I also included email in this campaign, targeting prospects whom I haven’t worked with recently, or whom I’ve never worked with at all. I didn’t go overboard in my emails; although I have over 400 contacts in Bredemarket’s customer relationship management system, I sent the email to less than 40 of them.
As of this morning, none of the recipients has booked a meeting with me to discuss their end of year needs.
Some explicitly told me that they were fine now and did not need or want Bredemarket’s services for end of year projects.
Some didn’t respond, which probably indicates that they did not need or want Bredemarket’s services either.
And I discovered that three companies (four contacts) will NEVER need or want Bredemarket’s services.
Delivery incomplete
How did I discover that?
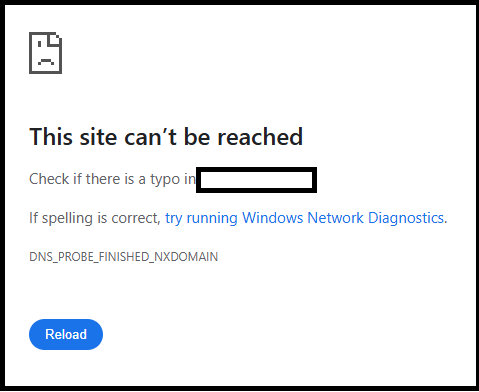
Via four “delivery status notification” messages.
Delivery incomplete.
So I visited the web pages in question, and they no longer existed.
This site can’t be reached.
I’ve been building up my CRM for over four years, so it’s not shocking that some companies have disappeared.
But one of the companies (“Company X”) DID exist a mere eight months ago.
I know this because I prepared a presentation on differentiation (see version 2 of the presentation here), and two representatives from Company X received the presentation in advance of a conference.
After the conference organizer distributed the presentation, I offered to meet with the companies individually (no charge) to discuss their content and differentiation needs, or anything else they wanted to discuss.
While some conference attendees took advantage of my April offer, the representatives from Company X did not.
And now in November, Company X no longer exists.
Tumbleweed image public domain.
Could Bredemarket have created the necessary content to keep Company X afloat? Who knows?
But EVERY company needs content to differentiate it from its competitors. Otherwise the competitors will attack you. And your competitors may not be as merciful with you as Jake Paul was with Mike Tyson.
If you need Bredemarket’s help with content, proposal, or analysis services, book a meeting with me.
I have a telehealth appointment next week with a medical professional whom I have previously met. And I assume she will participate in the telehealth appointment.
In the future, of course, she may not.
Way back in April 2013, I wrote a tymshft piece entitled “You will still take a cab to the doctor’s office. For a while.” It speculated about a future 2023 medical appointment in which the patient took a driverless cab to a medical facility. In the office, the patient was examined by remote staff…or so she thought.
“Well, I’m glad you’ve gotten used to the procedure,” replied the friendly voice. “I hope you like me!”
“I do,” said Edith. “You’ve been very helpful. But I’ve always wondered exactly WHERE you were. If you were in Los Angeles, or in Mississippi, or perhaps in India or China, or perhaps even in one of the low-cost places such as Chad. If you don’t mind my asking, exactly where ARE you?”
“I don’t mind answering the question,” replied the friendly voice, “and I hope you don’t take my response the wrong way, but I’m not really a person as you understand the term. I’m actually an application within the software package that runs the medical center. But my programmers want me to tell you that they’re really happy to serve you, and that Stanford sucks.” The voice paused for a moment. “I’m sorry, Edith. You have to forgive the programmers – they’re Berkeley grads.”
“Oh,” said Edith after a moment. “This is something new. I’m used to it in banking, but I didn’t realize that a computer program could run an entire medical center. Well…who picks up the trash?”
“That’s an extra question! Just kidding,” replied the friendly voice. “Much of the trash pickup is automated, but we do have a person to supervise the operation. Ron Hussein. You actually know him – he was your cab driver in 2018 when you came here.”
Re-reading this 2013 piece, I was amused at three things I got wrong.
First, Google, Facebook, and Apple did NOT merge to form Gaceapple, “the important merger that saved the tech industry in the United States from extinction.” American tech firms are still powerful…for now.
Second, my assumption of cab companies adopting driverless cars assumed the continued existence of cab companies. Ride share services have reduced the presence of traditional companies dramatically.
Third, my assumption that medical firms would sink untold sums of money into centralized automated medical examination rooms could be questioned…especially for routine appointments like Edith’s. Why not just let Edith’s smartphone—perhaps with a single attachment—gather the data?
Of course, there are medical ethics questions that underlie this entire discussion of remote telehealth and the use of non-person entities (NPEs). And we are struggling with those right now.