How can your technology business work with an outsourced content writer?
Perhaps you should first ask WHY your technology business needs an outsourced content writer.
The need for content
Do your technology business website and social media channels DESPERATELY need written content?
- Is your website a dreary collection of facts and awards that don’t address what your prospects REALLY care about?

- Have you NEVER posted to your company LinkedIn page?
- Is your online presence a ghost town?
There may be a variety of reasons for this. Perhaps your current employees are too busy doing other things. Or perhaps writing terrifies them so much that they think ChatGPT-generated content is actually a GOOD thing. (Read the content. It isn’t good.)
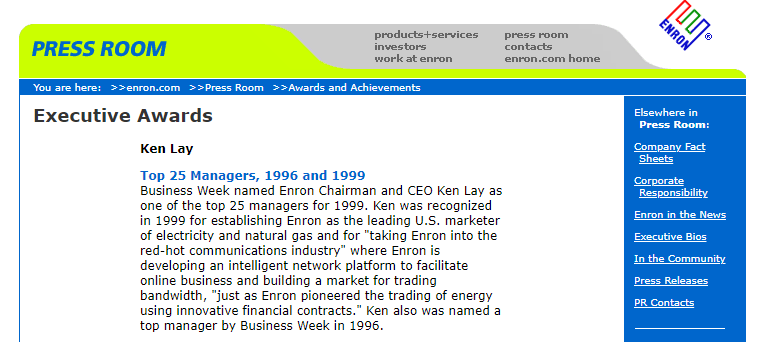
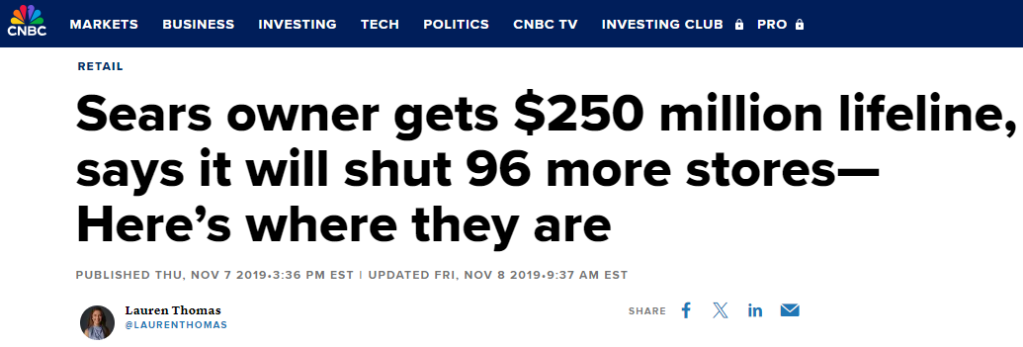
So you’re thinking about outsourcing the work to a content writer. One who has created content for multiple technology firms, including 9 returning clients. Here are four examples.
But how does outsourced content writing work?
How Bredemarket works with you to create content
Maybe you need an outsourced content writer because your current textual content is not compelling to your prospects, or perhaps it’s non-existent (for example, a LinkedIn company page with zero posts).
If you approach Bredemarket with your outsourced content writing request, here’s how we will work together:
For this example, let’s assume that you need between 400 to 600 words of text to post to your company blog or to your company LinkedIn account, and therefore are purchasing my Bredemarket 400 Short Writing Service.

Step 1: Kickoff
This is the most important step in the entire process, and I don’t write a word of text until you and I have some agreement on WHAT I am going to write.
I start by asking seven questions about the content, your product, and your company.

- Why?
- How?
- What?
- Goal?
- Benefits?
- Target Audience?
- Emotions?
I ask some additional questions which I won’t discuss in detail here. For example, you may specify the subject matter experts or articles I need to consult.
Once we’ve worked through ALL the questions, either in a synchronous meeting or asynchronously via email, I have a good idea of what the written content needs to say.
Step 2: First draft
Now I write the first draft.

I don’t ask a bot to write the first draft; I write it myself.
Why? Because I’m an opinionated, crotchety, temperamental writer, and a “you can pry my keyboard out of my cold dead hands” type.
This benefits you because I love doing this, communicating your benefits to your prospects using the framework upon which we agreed in the kickoff.
Unless we agree on a different schedule, I get that first draft to you in three days for the next important step.
Step 3: First draft review
This is where you come in. Your task is to review my draft within three days and provide comments. And if I don’t hear from you within three days, you’ll hear from me. Why?
- The first reason is my pure self-interest. The sooner I complete the project, the sooner I get paid. Those cold dead hands need some nice gloves.
- The second reason is of mutual interest. We want to complete the project while we’re focused on thinking about it, and while it is critically important to us.
- The third reason is for your own self-interest. You have a content gap, and it’s in your interest to fill that gap. If we get this draft reviewed and move forward, that gap will be filled quickly. If we don’t move forward, the gap will remain, your efforts to contract with Bredemarket will be for naught, and you’ll still have an uninteresting website and dead social media accounts.
Step 4: It depends
What happens after the first draft review varies from client to client.
- Some of my clients love the first draft and don’t want to change a thing.
- Some of my first drafts have embedded questions that you need to answer; once those questions are answered, the content is ready.
- Some of my first drafts may need minor changes. In one case, I was asked to remove a reference to a successful hack that occurred at a well-known company; unbeknownst to me, the company was a customer of another division of the client in question. Whoops.
- Occasionally more substantive changes are required, and I end up creating a second draft in three days, and you review it in three days.
In the end, we have a piece of content that is almost ready for publication.
Step 5: Finalize and publish
While the words may be ready, the entire piece is not.
I’m not a graphics person, and usually a written piece needs some accompanying images to drive the message home. I may suggest some images, or I may suggest that the client reuse an image from their website, or I may just ask the client to select an appropriate image.
Once the text and images are ready, you publish the piece. Normally I don’t have access to your website or social media accounts, so I can’t publish the piece for you. Only one client has given me such access, and even for that client I don’t have COMPLETE publishing permission.
For short projects such as a Bredemarket 400 project, I usually bill you when you publish the piece, although in certain circumstances I may bill you once the text is complete.
Are you ready to outsource your content marketing?
While other content marketers may work differently, we all have some type of process for our outsourced content writing.
If you’re ready to move forward with Bredemarket for outsourced content writing, contact me.