I debated whether or not I should publish this because it touches upon two controversial topics: U.S. politics, and my proposed sixth factor of authentication.
I eventually decided to share it on the Bredemarket blog but NOT link to it or quote it on my socials.
Although I could change my mind later.
Are deepfakes bad?
When I first discussed deepfakes in June 2023, I detailed two deepfake applications.
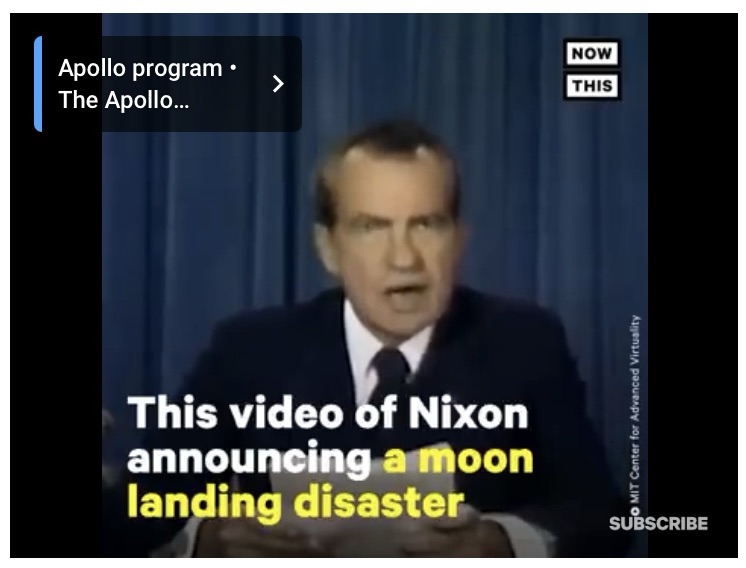
One deepfake was an audio-video creation purportedly showing Richard Nixon paying homage to the Apollo 11 astronauts who were stranded on the surface of the moon.
- Of course, no Apollo 11 astronauts were ever stranded on the surface of the moon; Neil Armstrong and Buzz Aldrin returned to Earth safely.
- So Nixon never had to pay homage to them, although William Safire wrote a speech as a contingency.
- This deepfake is not in itself bad, unless it is taught in a history course as true history about “the failure of the U.S. moon program.” (The Apollo program had a fatal catastrophe, but not involving Apollo 11.)
The other deepfake was more sinister.
In early 2020, a branch manager of a Japanese company in Hong Kong received a call from a man whose voice he recognized—the director of his parent business. The director had good news: the company was about to make an acquisition, so he needed to authorize some transfers to the tune of $35 million….The manager, believing everything appeared legitimate, began making the transfers.
Except that the director wasn’t the director, and the company had just been swindled to the tune of $35 million.
I think everyone knows now that deepfakes can be used for bad things. So we establish standards to determine “content provenance and authenticity,” which is a fancy way to say whether content is real or a deepfake.
In addition to establishing standards, we do a lot of research to counter deepfakes, because they are bad.
Or are they?
What the National Science Foundation won’t do
Multiple sources, including both Nextgov and Biometric Update, are reporting on the cancellation of approximately 430 grants from the National Science Foundation. Among these grants are ones for deepfake research.
Around 430 federally-funded research grants covering topics like deepfake detection, artificial intelligence advancement and the empowerment of marginalized groups in scientific fields were among several projects terminated in recent days following a major realignment in research priorities at the National Science Foundation.
As you can probably guess, the cancellation of these grants is driven by the Trump Administration and the so-called Department of Government Efficiency (DOGE).
Why?
Because freedom:
Per the Presidential Action announced January 20, 2025, NSF will not prioritize research proposals that engage in or facilitate any conduct that would unconstitutionally abridge the free speech of any American citizen. NSF will not support research with the goal of combating “misinformation,” “disinformation,” and “malinformation” that could be used to infringe on the constitutionally protected speech rights of American citizens across the United States in a manner that advances a preferred narrative about significant matters of public debate.
The NSF argues that a person’s First Amendment rights permit them, I mean permit him, to share content without having the government prevent its dissemination by tagging it as misinformation, disinformation, or malinformation.
And it’s not the responsibility of the U.S. Government to research creation of so-called misinformation content. Hence the end of funding for deepfake research.
So deepfakes are good because they’re protected by the First Amendment.
But wait a minute…
Just because the U.S. Government doesn’t like it when patriotic citizens are censored from distributing deepfake videos for political purposes, that doesn’t necessarily mean that the U.S. Government objects to ALL deepfakes.
For example, let’s say that a Palm Beach, Florida golf course receives a video message from Tiger Woods reserving a tee time and paying a lot of money to reserve the tee time. The golf course doesn’t allow anyone to book a tee time and waits for Tiger’s wire transfer to clear. After the fact, the golf course discovers that (a) the money was wired from a non-existent account, and (b) the person making the video call was not Tiger Woods, but a faked version of him.
I don’t think anyone in the U.S. Government or DOGE thinks that ripping off a Palm Beach, Florida golf course is a legitimate use of First Amendment free speech rights.
So deepfakes are bad because they lead to banking fraud and other forms of fraud.
This is not unique to deepfakes, but is also true of many other technologies. Nuclear technology can provide energy to homes, or it can kill people. Facial recognition (of real people) can find missing and abducted persons, or it can send Chinese Muslims to re-education camps.
Let’s go back to factors of authentication and liveness detection
Now let’s say that Tiger Woods’ face shows up on YOUR screen. You can use liveness detection and other technologies to determine whether it is truly Tiger Woods, and take action accordingly.
- If the interaction with Woods is trivial, you may NOT want to spend time and resources to perform a robust authentication.
- If the interaction with Woods is critical, you WILL want to perform a robust authentication.
It all boils down to something that I’ve previously called “somewhat you why.”
Why is Tiger Woods speaking?
- If Tiger Woods is performing First Amendment-protected activity such as political talk, then “somewhat you why” asserts that whether this is REALLY Woods or not doesn’t matter.
- If Tiger Woods is making a financial transaction with a Palm Beach, Florida golf course, then “somewhat you why” asserts that you MUST determine if this is really Woods.
It’s simple…right?
What about your deepfake solution?
Regardless of federal funding, companies are still going to offer deepfake detection products. Perhaps yours is one of them.
How will you market that product?
Do you have the resources to market your product, or are your resources already stretched thin?
If you need help with your facial recognition product marketing, Bredemarket has an opening for a facial recognition client. I can offer
- compelling content creation
- winning proposal development
- actionable analysis
If Bredemarket can help your stretched staff, book a free meeting with me: https://bredemarket.com/cpa/
(Lincoln’s laptop from Imagen 3)