On a Bredemarket Instagram story shared Friday afternoon (to disappear Saturday), I noted Meta’s AI advice NOT to call someone who flew a drone near firefighting equipment an “idiot.” I respectfully disagree. The term is appropriate.
Let me clarify that Meta is not trying to curtail free speech. Only governments can curtail free speech. Private entities cannot.
For example, if I still worked for IDEMIA, and used IDEMIA social media channels to declare the Thales ABIS the best ABIS ever, IDEMIA has every right to delete that post—and me.
In the same way, if Zuck insists that Meta users cannot refer to people threatening lives as “idiots,” that is Meta’s right.
When I was last a full-time Proposal Manager a decade ago (for MorphoTrak), a proposal due date extension did not necessitate an update to an Asana task end date. Asana existed (its iOS and Android apps were both released by 2015), but MorphoTrak wasn’t using them.
Things are different now.
My consulting firm Bredemarket has helped (at least) four identity/biometric companies with proposal work over the years, including RFI responses, RFP responses, proposal letters, and similar communications; proposal templates; and proposal standard text (what the machinists call “boilerplate”).
I signed non-disclosure agreements with all these companies, which is why I redacted my current client’s name and its prospective customer from the accompanying image. But if my client wins, I will celebrate. Quietly.
Incidentally, since my Asana is only accessible to me, it only includes minimal information. In Asana, this entire response is a single entry. I use other means to communicate the more detailed schedule to my clients.
Incidentally, if you were one of MY prospects and received a communication saying that I was wrapping up a project today…I’m not. But it’s almost wrapped up, bearing in mind that any gas fills up the available space.
Proposal work (the P) is just one of several services Bredemarket provides to identity, biometric, and technology clients. In fact, all 4 of the referenced Proposal clients have also used my Content services, my Analysis services, or both.
When I interact with the worldwide company NEC, I am usually dealing with automated biometric identification systems (ABIS).
Of course, ABIS is only a small part of what NEC does. It’s also involved in healthcare.
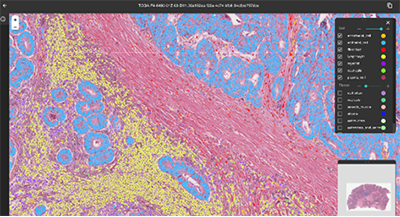
Consider…artificial intelligence and deep learning-powered digital pathology (“a field involving the digitization and computational analysis of pathology slides”).
“NEC Corporation (NEC; TSE: 6701) and Biomy, Inc. (Biomy) have signed a Memorandum of Understanding (MoU) for a joint marketing partnership to develop and expand artificial intelligence/deep learning (AI/DL)-based analytical platforms in the field of digital pathology. Through this partnership, the two companies aim to promote precision medicine for cancer patients and contribute to the advancement of the healthcare industry.”
So what is Biomy contributing?
“Biomy, which aims to realize personalized medicine through pathological AI technology, has developed DeepPathFinder™, a proprietary, cloud-based, AI/DL automated digital pathology analytical platform.”
And NEC?
“NEC has positioned healthcare and life sciences as a core pillar of its growth strategy. With a strong foundation in image analysis and other AI technologies, NEC has a long history of providing medical information systems such as electronic medical records to healthcare institutions.”
As I’ve said before, healthcare must deal with privacy concerns (protected health information, or PHI) similar to those NEC addresses in its other biometric product line (personally identifiable information, or PII). I personally can’t do nefarious things if I fraudulently acquire your digital pathology slide, but some bad actors could. Presumably the Biomy product is well protected.
As some of you know, AML stands for Anti-Money Laundering. It ensures that money given to Johnny Angel doesn’t end up in the hands of Vladimir Putin. This impacts financial institutions:
“Banks had to follow government regulations (know your customer, anti-money laundering, know your business), even in the midst of a worldwide pandemic.”
But AML goes far beyond banks because of its national security implications. Which means the military has to get involved.
Therefore DARPA has entered the picture, with its Program Announcement (posted on SAM as DARPA-SN-25-23) for something DARPA calls “Anticipatory and Adaptive Anti-Money Laundering,” or A3ML.
“The program seeks to develop sophisticated algorithmic methods that can analyze financial transaction graphs and detect suspicious patterns more effectively than existing manual processes. This initiative represents a significant shift towards proactive and predictive financial crime detection methodologies.”
Of course, the introduction of the word “predictive” raises alarm bells, based upon activities outside of banking. At best, police potentially waste a lot of time investigating every single broken tail light. At worst, Muslim lawyer Brandon Mayfield becomes a suspect for a crime he didn’t commit.
Hopefully the people pursuing A3ML can minimize bias.
When you obtain a government ID from one national government, you normally don’t get a second government ID from a different national government, unless you hold dual citizenship.
“President Lai Ching-te (賴清德) has cautioned Taiwanese citizens against China’s reported efforts to lure them into applying for Chinese ID cards and residency permits.”
Because Taiwan is a contested territory, acceptance of People’s Republic of China IDs could resulted in PRC claims to Taiwan…to protect its citizens there. Therefore Taiwan really discourages this.
“According to local regulations, citizens who receive a Chinese ID will have their Taiwanese household registration revoked.”