The word “landscape” suggests a physical environment, not a digital environment. Merriam-Webster specifically cites “natural inland scenery,” which even rules out the shoreline, much less a bunch of smartphone apps or SDKs jumbled together.
And how does a DIGITAL landscape evolve, rapidly or otherwise?
Now I’m not suggesting that you AVOID references to the “rapidly evolving digital landscape.” After all, if aspiring influencers and thought leaders use the term, your content needs to sound exactly like theirs. And this applies whether your thought leader is a person or an AI bot. Trust me on this.
Or perhaps you shouldn’t take my advice. Maybe the overuse of hack phrases is NOT a best-of-breed approach.
So why did I write this…
Because a particular respectable vendor began a Facebook post with the words “In today’s rapidly evolving digital landscape.”
And it shook me.
Was this a one-time slip up, or are readers EXPECTING companies to talk like this?
(Digital landscape image AI-generated by Google Gemini)
Klarna CEO Sebastian Siemiatkowski has revealed a plan to eliminate his job and replace himself with an AI bot…
…wait, I misread that. Siemiatkowski has revealed a plan to replace OTHER people’s jobs at Klarna.
Funny how these rightsizing moves, with a few notable exceptions, always seem to spare the executives. The brunt will fall on others.
“With almost half the workforce at the company, Siemiatkowski plans to shift customer service and marketing duties to AI. ‘Not only can we do more with less, but we can do much more with less,’ he said…”
I bet customer service and marketing morale is REALLY high at Klarna right now. If it weren’t for the not-so-good job market at the moment, Siemiatkowski might realize his rightsizing goals via attrition before his bots are ready.
But let me ask my good buddy Google Gemini. The material below was not written by me.
= =
While AI has made significant strides in customer service and marketing, it’s unlikely that Klarna, or any company, could completely eliminate human involvement.
Here’s why:
Nuance and Empathy: Human agents are better equipped to handle complex customer inquiries, especially those involving emotional situations. AI, while improving, still struggles with understanding and responding to nuanced emotions.
Problem-Solving: Certain customer issues require creative problem-solving or judgment calls that AI may not be able to handle effectively.
Ethical Considerations: AI can perpetuate biases present in the data it’s trained on. Human oversight is essential to ensure ethical and fair treatment of customers.
Unforeseen Circumstances: AI may not be able to adapt to unexpected situations or rapidly changing circumstances. Human agents can often address these challenges more effectively.
Customer Preference: Many customers still prefer to interact with human agents, especially for complex or sensitive issues.
However, AI can be a valuable tool in these areas. It can automate routine tasks, provide 24/7 support, and offer personalized recommendations. The most effective approach is likely a hybrid model, combining AI with human agents to provide the best possible customer experience.
Never mind that the resulting generative AI content was wordy, crappy, and possibly incorrect. For some people the fact that the content was THERE was good enough.
Then I noted that sometimes I will HAVE to get that content out without proper reflection. I outlined two measures to do this:
Don’t sleep on the content.
Let full-grown ideas spring out of your head.
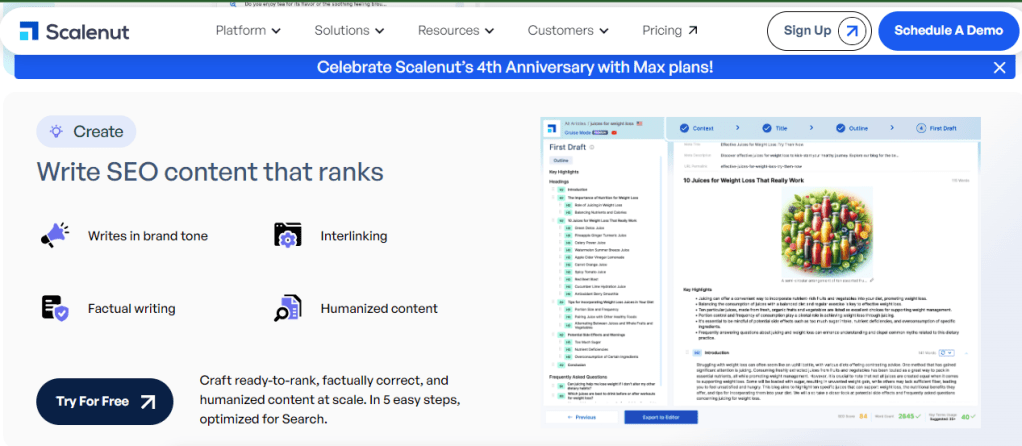
But I still prefer to take my time brewing my content. I’ve spent way more than five minutes on this post alone, and I don’t even know how I’m going to end it yet. And I still haven’t selected the critically important image to accompany the post.
Am I a nut for doing things manually?
You’ve gone from idea to 2500+ word articles in 10 minutes.
And if Scalenut explains WHY its technology is so great, the description is hidden behind an array of features, benefits, and statistics.
Maybe it’s me, but Scalenut could improve its differentiation here, as outlined in my video.
Differentiation, by Bredemarket.
What Scalenut does…and doesn’t do
I should clarify that copyrighting is but one part of Scalenut’s arsenal.
Scalenut is a one-stop-shop AI-powered SEO writing tool that will see you through keyword selection, research, and content production. Plus, you get full access to their copywriting tool, which can create more specific short-form content like product descriptions.
You optimize SEO content by adding NLP keywords, which are the words that Google uses to decide what an article is about.
MacRae cautions that it’s not for “individuals whose writing is their brand,” and Scalenut’s price point means that it’s not for people who only need a few pieces a month.
But if you need a lot of content, and you’re not Stephen King or Dave Barry or John Bredehoft (not in terms of popularity, but of distinctness), then perhaps Scalenut may help you.
I can’t tell you why, though.
(And an apology for those who watch the video; like “The Long Run” album itself, it takes forever to get to the song.)
I use both text generators (sparingly) and image generators (less sparingly) to artificially create text and images. But I encounter one image challenge that you’ve probably encountered also: bizarre misspellings.
This post includes an example, created in Google Gemini, that was created using the following prompt:
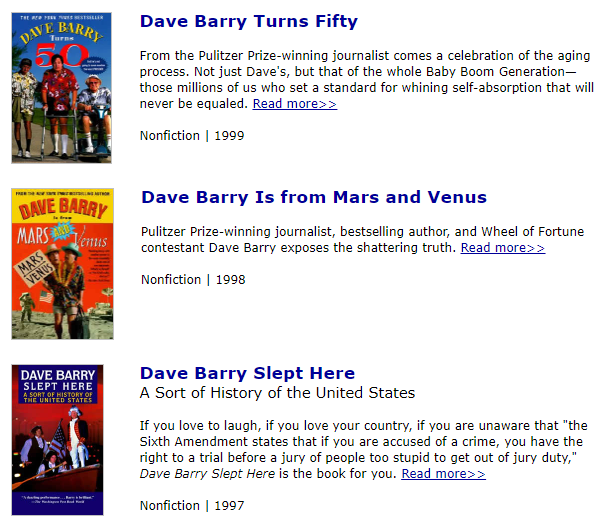
Create a square image of a library bookshelf devoted to the works authored by Dave Barry.
Now in the ideal world, my prompt would completely research Barry’s published titles, and the resulting image would include these book titles (such as Dave Barry Slept Here, one of the greatest history books of all time maybe or maybe not).
In the mediocre world, at least the book spines would include the words “Dave Barry.”
Why can’t your image generator spell words properly?
It always mystified me that AI-generated images had so many weird words, to the point where I wondered whether the AI was specifically programmed to misspell.
It wasn’t…but it wasn’t programmed to spell either.
TechCrunch recently published an article in which the title was so good you didn’t have to read the article itself. The title? “Why is AI so bad at spelling? Because image generators aren’t actually reading text.”
This is something that I pretty much forgot.
When I use an AI-powered text generator, it has been trained to respond to my textual prompts and create text.
When I use an AI-powered image generator, it has been trained to respond to my textual prompts and create images.
Two very different tasks, as noted by Asmelash Teka Hadgu, co-founder of Lesan and a fellow at the DAIR Institute.
“The diffusion models, the latest kind of algorithms used for image generation, are reconstructing a given input,” Hagdu told TechCrunch. “We can assume writings on an image are a very, very tiny part, so the image generator learns the patterns that cover more of these pixels.”
The algorithms are incentivized to recreate something that looks like what it’s seen in its training data, but it doesn’t natively know the rules that we take for granted — that “hello” is not spelled “heeelllooo,” and that human hands usually have five fingers.
For a long time, each ML (machine learning) model operated in one data mode – text (translation, language modeling), image (object detection, image classification), or audio (speech recognition).
However, natural intelligence is not limited to just a single modality. Humans can read and write text. We can see images and watch videos. We listen to music to relax and watch out for strange noises to detect danger. Being able to work with multimodal data is essential for us or any AI to operate in the real world.
So if we ask an image generator to create an image of a library bookshelf with Dave Barry works, it would actually display book spines with Barry’s actual titles.
So why doesn’t my Google Gemini already provide this capability? It has a text generator and it has an image generator: why not provide both simultaneously?
Because that’s EXPENSIVE.
I don’t know whether Google’s Vertex AI provides the multimodal capabilties I seek, where text in images is spelled correctly.
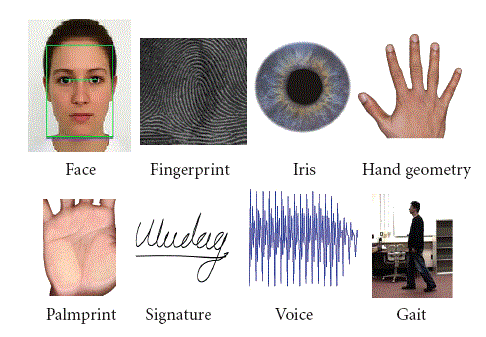
Something You Are. This is the factor that identifies people. It includes biometrics modalities (finger, face, iris, DNA, voice, vein, etc.). It also includes behavioral biometrics, provided that they are truly behavioral and relatively static.
Something You Have. While this is used to identify people, in truth this is the factor that identifies things. It includes driver’s licenses and hardware or software tokens.
Actually more than a decade, since my car’s picture was taken in Montclair, California a couple of decades ago doing something it shouldn’t have been doing. I ended up in traffic school for that one.
Now license plate recognition isn’t that reliable of an identifier, since within a minute I can remove a license plate from a vehicle and substitute another one in its place. However, it’s deemed to be reliable enough that it is used to identify who a car is.
Note my intentional use of the word “who” in the sentence above.
Because when my car made a left turn against a red light all those years ago, the police didn’t haul MY CAR into court.
Using then-current technology, it identified the car, looked up the registered owner, and hauled ME into court.
These days, it’s theoretically possible (where legally allowed) to identify the license plate of the car AND identify the face of the person driving the car.
But you still have this strange merger of who and what in which the non-human characteristics of an entity are used to identify the entity.
What you are.
But that’s nothing compared to what’s emerged over the past few years.
We Are The Robots
When the predecessors to today’s Internet were conceived in the 1960s, they were intended as a way for people to communicate with each other electronically.
And for decades the Internet continued to operate this way.
Until the Internet of Things (IoT) became more and more prominent.
Application programming interfaces (APIs) are the connective tissue behind digital modernization, helping applications and databases exchange data more effectively. The State of API Security in 2024 Report from Imperva, a Thales company, found that the majority of internet traffic (71%) in 2023 was API calls.
Couple this with the increasing use of chatbots and other artificial intelligence bots to generate content, and the result is that when you are communicating with someone on the Internet, there is often no “who.” There’s a “what.”
What you are.
Between the cars and the bots, there’s a lot going on.
What does this mean?
There are numerous legal and technical ramifications, but I want to concentrate on the higher meaning of all this. I’ve spent 29 years professionally devoted to the identification of who people are, but this focus on people is undergoing a seismic change.
The science fiction stories of the past, including TV shows such as Knight Rider and its car KITT, are becoming the present as we interact with automobiles, refrigerators, and other things. None of them have true sentience, but it doesn’t matter because they have the power to do things.
Keeping the internet open is crucial, and part of being open means Reddit content needs to be accessible to those fostering human learning and researching ways to build community, belonging, and empowerment online. Reddit is a uniquely large and vibrant community that has long been an important space for conversation on the internet. Additionally, using LLMs, ML, and AI allow Reddit to improve the user experience for everyone.
In line with this, Reddit and OpenAI today announced a partnership to benefit both the Reddit and OpenAI user communities…
Perhaps some members of the Reddit user community may not feel the benefits when OpenAI is training on their data.
While people who joined Reddit presumably understood that anyone could view their data, they never imagined that a third party would then process its data for its own purposes.
Oh, but wait a minute. Reddit clarifies things:
This partnership…does not change Reddit’s Data API Terms or Developer Terms, which state content accessed through Reddit’s Data API cannot be used for commercial purposes without Reddit’s approval. API access remains free for non-commercial usage under our published threshold.
It discussed both large language models and large multimodal models. In this case “multimodal” is used in a way that I normally DON’T use it, namely to refer to the different modes in which humans interact (text, images, sounds, videos). Of course, I gravitated to a discussion in which an image of a person’s face was one of the modes.
In this post I will look at LMMs…and I will also look at LMMs. There’s a difference. And a ton of power when LMMs and LMMs work together for the common good.
When Google announced its Gemini series of AI models, it made a big deal about how they were “natively multimodal.” Instead of having different modules tacked on to give the appearance of multimodality, they were apparently trained from the start to be able to handle text, images, audio, video, and more.
Other AI models are starting to function in a TRULY multimodal way, rather than using separate models to handle the different modes.
So now that we know that LLMs are large multimodal models, we need to…
…um, wait a minute…
Introducing the Large Medical Model (LMM)
It turns out that the health people have a DIFFERENT definition of the acronym LMM. Rather than using it to refer to a large multimodal model, they refer to a large MEDICAL model.
Our first of a kind Large Medical Model or LMM for short is a type of machine learning model that is specifically designed for healthcare and medical purposes. It is trained on a large dataset of medical records, claims, and other healthcare information including ICD, CPT, RxNorm, Claim Approvals/Denials, price and cost information, etc.
I don’t think I’m stepping out on a limb if I state that medical records cannot be classified as “natural” language. So the GenHealth.AI model is trained specifically on those attributes found in medical records, and not on people hemming and hawing and asking what a Pekingese dog looks like.
But there is still more work to do.
What about the LMM that is also an LMM?
Unless I’m missing something, the Large Medical Model described above is designed to work with only one mode of data, textual data.
But what if the Large Medical Model were also a Large Multimodal Model?
Rather than converting a medical professional’s voice notes to text, the LMM-LMM would work directly with the voice data. This could lead to increased accuracy: compare the tone of voice of an offhand comment “This doesn’t look good” with the tone of voice of a shocked comment “This doesn’t look good.” They appear the same when reduced to text format, but the original voice data conveys significant differences.
Rather than just using the textual codes associated with an X-ray, the LMM-LMM would read the X-ray itself. If the image model has adequate training, it will again pick up subtleties in the X-ray data that are not present when the data is reduced to a single medical code.
In short, the LMM-LMM (large medical model-large multimodal model) would accept ALL the medical outputs: text, voice, image, video, biometric readings, and everything else. And the LMM-LMM would deal with all of it natively, increasing the speed and accuracy of healthcare by removing the need to convert everything to textual codes.
A tall order, but imagine how healthcare would be revolutionized if you didn’t have to convert everything into text format to get things done. And if you could use the actual image, video, audio, or other data rather than someone’s textual summation of it.
Obviously you’d need a ton of training data to develop an LMM-LMM that could perform all these tasks. And you’d have to obtain the training data in a way that conforms to privacy requirements: in this case protected health information (PHI) requirements such as HIPAA requirements.
But if someone successfully pulls this off, the benefits are enormous.
You’ve come a long way, baby.
Robert Young (“Marcus Welby”) and Jane Wyatt (“Margaret Anderson” on a different show). By ABC TelevisionUploaded by We hope at en.wikipedia – eBay itemphoto informationTransferred from en.wikipedia by SreeBot, Public Domain, https://commons.wikimedia.org/w/index.php?curid=16472486.
I’m going to describe one example of how Bredemarket has helped its customers, based upon one of my client projects from several years ago.
Stupid Word Tricks. Tell your brother, your sister and your mama too. See below.
I’ve told this story before, but I wanted to take a fresh look at the problem the firm had, and the solution Bredemarket provided. I’m not identifying the firm, but perhaps YOUR firm has a similar problem that I can solve for you. And your firm is the one that matters.
The problem
This happened several years ago, but was one of Bredemarket’s first successes.
The firm that asked for my help is one that focuses on one particular biometric modality, and provides a high-end solution for biometric identification.
In addition, the firm’s solution has multiple applications, crime solving and disaster victim identification being two of them.
The firm needed a way to perform initial prospect outreach via budgetary quotations, targeted to the application that mattered to the prospect. A simple proposal problem to be solved…or so it seemed.
Why the obvious proposal solution didn’t work
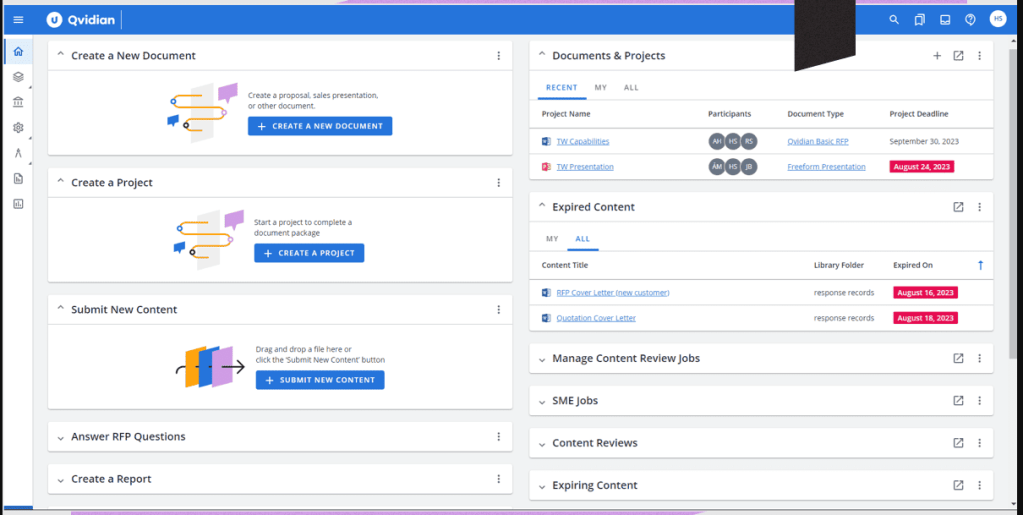
I had encountered similar problems while employed at Printrak and MorphoTrak and while consulting here at Bredemarket, so the solution was painfully obvious.
Qvidian, one proposal automation software package that I have used. But there are a LOT of proposal automation software packages out there, including some new ones that incorporate artificial intelligence. From https://uplandsoftware.com/qvidian/.
Have your proposal writers create relevant material in their proposal automation software that could target each of the audiences.
So when your salesperson wants to approach a medical examiner involved in disaster victim identification, the proposal writer could just run the proposal automation software, create the targeted budgetary quotation, populate it with the prospect’s contact information, and give the completed quotation to the salesperson.
Unfortuntely for the firm, the painfully obvious solution was truly painful, for two reasons:
This firm had no proposal automation software. Well, maybe some other division of the firm had such software, but this division didn’t have access to it. So the whole idea of adding proposal text to an existing software solution, and programming the solution to generate the appropriate budgetary quotation, wasn’t going to fly.
In addition, this firm had no proposal writers. The salespeople were doing this on their own. The only proposal writer they had was the contractor from Bredemarket. And they weren’t going to want to pay for me to generate every budgetary quotation they needed.
In this case, the firm needed a way for the salespeople to generate the necessary budgetary quotations as easily as possible, WITHOUT relying on proposal automation software or proposal writers.
Bredemarket’s solution
To solve the firm’s problem, I resorted to Stupid Word Tricks.
I created two similar budgetary quotation templates: one for crime solving, and one for disaster victim identification. (Actually I created more than two.) That way the salesperson could simply choose the budgetary quotation they wanted.
The letters were similar in format, but had little tweaks depending upon the audience.
Using document properties to create easy-to-use budgetary quotations.
The Stupid Word Tricks came into play when I used Word document property features to allow the salesperson to enter the specific information for each prospect, which then rippled throughout the document, providing a customized budgetary quotation to the prospect.
The result
The firms’ salespeople used Bredemarket’s templates to generate initial outreach budgetary quotations to their clients.
And the salespeople were happy.
I’ve used this testimonial quote before, but it doesn’t hurt to use it again.
“I just wanted to truly say thank you for putting these templates together. I worked on this…last week and it was extremely simple to use and I thought really provided a professional advantage and tool to give the customer….TRULY THANK YOU!”
Comment from one of the client’s employees who used the standard proposal text
While I actively consulted for the firm I maintained the templates, updating as needed as the firm achieved additional certifications.
Why am I telling this story again?
I just want to remind people that Bredemarket doesn’t just write posts, articles, and other collateral. I can also create collateral such as these proposal templates that you can re-use.
(T)here were 7,887 nurses who recently ended their healthcare careers between 2018 and 2021….39% of respondents said their decision to leave healthcare was due to a planned retirement. However, 26% of respondents cited burnout or emotional exhaustion, and 21% cited insufficient staffing.
And this is ALL nurses. Not just the forensic nurses who have to deal with upsetting examinations that (literally) probe into sexual assault and child abuse. All nurses have it tough.
At Artisight we are committed to reversing this trend through AI-driven technology that is bringing the joy back to medicine!!
Can artificial intelligence bots truly relieve the exhaustion of overworked health professionals? Let’s look at two AI solutions from 3M and Artisight and see whether they truly benefit medical staff.
3M, a former competitor to MorphoTrak until 3M sold its biometric offerings (as did MorphoTrak’s parent Safran), has invested heavily into healthcare artificial intelligence solutions. This includes a solution that addresses the bane of medical professionals everywhere—keeping up with the paperwork (and checking for potentially catastrophic errors).
Our solutions use artificial intelligence (AI) to alleviate administrative burden and proactively identify gaps and inconsistencies within clinical documentation. Supporting completeness and accuracy every step of the way, from capture to code, means rework doesn’t end up on the physician’s plate before or even after discharge. That enables you to keep your focus where it needs to be – on the patient right in front of you.
But what about Artisight, whose assertion inspired this post in the first place?
A recent PYMNTS article interviewed Artisight President Stephanie Lahr to uncover Artight’s approach.
The Artisight platform marries IoT sensors with machine learning and large language models. The overall goal in a hospital setting is to streamline safe patient care, including virtual nursing. Compliance with HIPAA, according to Lahr, has been an important part of the platform’s development, which includes computer vision, voice recognition, vital sign monitoring, indoor positioning capabilities and actionable analytics reports.
In more detail, a hospital patient room is equipped with Al-powered devices such as high-quality, two-way audio and video with multiple participants for virtual care. Ultra-wideband technology tracks the movement and flow of assets throughout the hospital. Remote nurses and observers monitor patient room activity off-site and interact virtually with patients and clinicians.
At a minimum, this reduces the need for nurses to run down the hall just to check things. At a maximum, tracking of asset flows and actionable analytics reports make the job of everyone in the hospital easier.
So how can 3M’s and Artisight’s artificial intelligence offerings benefit medical facilities?
Allow medical professionals to concentrate on care. Patients don’t need medical professionals who are buried in paperwork. Patients need medical professionals who are spending time with them. The circumstances that land a patient in a hospital are bad enough, and to have people who are forced to ignore patient needs makes it worse. Maybe some day we’ll even get back to Welbycare.
Free medical professionals from routine tasks. Assuming the solutions work as advertised, they eliminate the need to double-check a report for errors, or the need to walk down the hall to capture vital signs.
Save lives. Yeah, medical professionals do that. If the Marcus Welby AI bot spots an error in a report, or if the bot detects a negative change in vital signs while a nurse is occupied with another patient, the technology could very well save a life.