

Ease of use, and speed.
Category Archives: Uncategorized
More On Presentation Attack Detection Level 3

If you needed any confirmation that Presentation Attack Detection Level 2 is so last year, you have it now.
Last month I talked about Yoti achieving confirmation of PAD Level 3 in iBeta testing.
But iBeta isn’t the only entity performing PAD Level 3 testing.
- FaceTec’s algorithm received PAD Level 3 confirmation from BixeLab in October.
- Aware received a similar confirmation in November.
Will PAD Level 3 become the new floor for liveness detection? It depends upon your needs. Here’s how Mantra explains the difference between levels 2 and 3.
Level 2 (L2):
More realistic spoofs-high-quality 3D masks, composite fingers, better materials. Harder to detect, but still lab-craft attacks.
Level 3 (L3):
Advanced adversary scenarios-custom molds, hyper-realistic masks, lab-grade fabrication. Represents attackers with serious resources.
The “serious resources” part is key. Fraudsters will only spend “serious resources” if the target is valuable enough.
But will consumers perceive that THEIR data is valuable enough to warrant Level 3 liveness detection? And avoid the solutions with “only” Level 2 conformance?
Three companies (so far) are betting on it.
(Actually four. See my update.)
(And yes, the three hands on the fraudster should have been a giveaway…)
Subject Matter Experts Ask Pesky Questions

Sometimes it may take LONGER to produce content when a subject matter expert is involved.
Because they know what questions need asking.
But the final content will be more rigorous as a result.
An Iris is Bidirectional

A human looks out from an iris to see things.
A biometric reader looks toward an iris to identify an individual.
Why Product Marketers Repeat Themselves

How many times have you seen a SINGLE advertisement for a product or service and IMMEDIATELY rushed out and bought it?
As Email Tool Tester notes, product marketing doesn’t work that way.
[O]ur research suggests that in 2025, the actual number of touchpoints before a sale varies between 1 and 50, depending on the prospect’s buying stage:
- Inactive customers only need 1–3 touches on average
- A warm inbound lead will need 5–12 touches
- A cold prospect can require 20–50 touches
So I came up with a bright idea: just repeat my message: “Identity, biometric, and technology marketing leaders should use Bredemarket’s marketing and writing services for their content, proposal, and analysis needs.”
And repeat it 50 times. (Preferably in a shorter form.)
But before applying my mad copy/paste skillz, I checked…and Email Tool Tester also notes that product marketing doesn’t work that way either. Specifically, you need multiple touchpoints, and multiple TYPES of touchpoints, to ensure your message resonates with your hungry people.
- Which means that Bredemarket needs to use multiple methods to communicate with my prospects.
- And it also means that my customers need to take advantage of the 22 types of internal and external content Bredemarket can create.
But you can repurpose.
- I recently completed a long piece of content for a client, and flagged six sections that the client can share as shorter pieces of content. That’s seven pieces for the price of one. (And two touchpoints. 48 to go.)
- But that’s nothing. Once I created 31 pieces of content from a single idea. (Only 19 to go that time.)
And if you’ve seen Bredemarket’s messaging 49 times in the past, now is the time to act and discuss your content, proposal, and/or analysis needs with Bredemarket.
A Little Help For Entry-Level Workers

Over a year ago I shared this:
The mood at the time was that the world was changing and generative AI bots and non-person entities could replace people.
Yes, I am familiar with the party line that AI wouldn’t replace anyone, but would empower everyone to do their jobs more effectively.
The layoff trackers told a different story.
As did the AI gurus who proclaimed that many jobs would soon be obsolete.
Strangely enough, “AI guru” was not one of the jobs that was going away. Which is odd. It seems to me that giving inspirational talks would be the perfect job for a non-person entity.
One firm is (big) blue on people
But many people agreed that entry-level jobs were ripe for rightsizing, meaning that those at the beginnings of their careers would have a much harder time finding work.
“Hardware giant IBM plans to triple entry-level hiring in the U.S. in 2026, according to reporting from Bloomberg. Nickle LaMoreaux, IBM’s chief human resource officer, announced the initiative….’And yes, it’s for all these jobs that we’re being told AI can do,’ LaMoreaux said.”
Because IBM has separated what AI can do from what it can’t do. IBM’s new positions are “less focused on areas AI can actually automate — like coding — and more focused on people-forward areas like engaging with customers.”
Guess what? Bots are not engaging. Well, maybe they’re more engaging than AI gurus…
Can you use people?
But I will go one step further and claim that human product marketers and content writers are more engaging than bot product marketers and content writers.
Believe me, I’ve tested this. Bredebot can fake 30 years of experience, but it’s not genuine.
If you want to engage with your prospects, don’t assign the job to a bot. That’s human work.
Fingerprint Evidence in Court
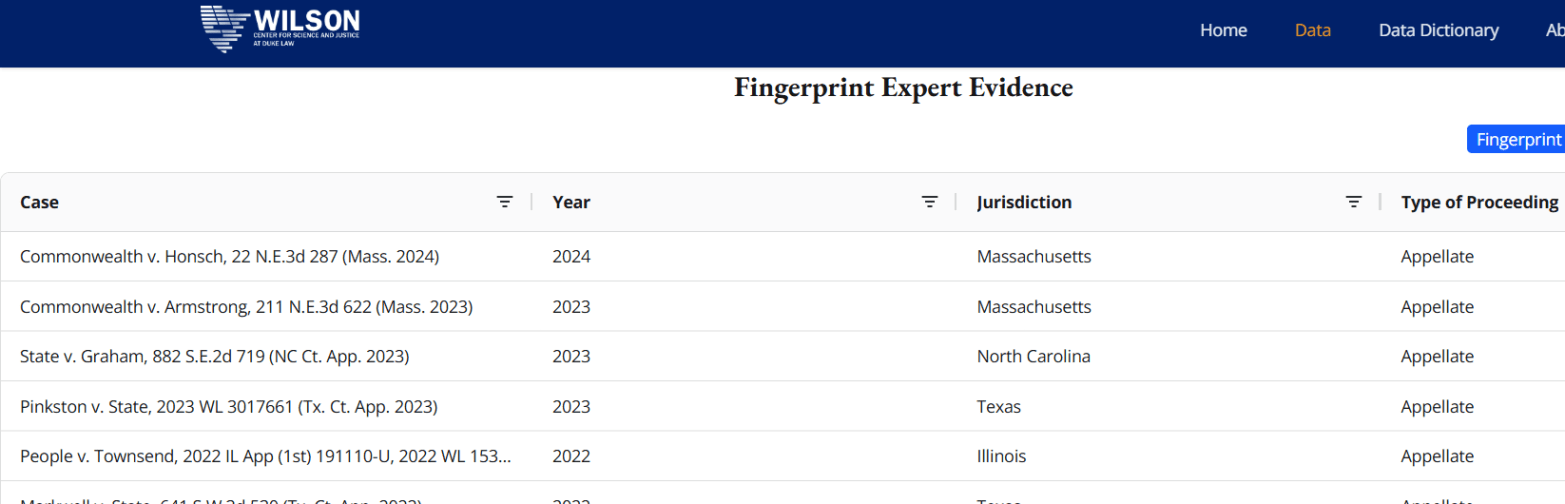
For…a long time I’ve been talking about whether fingerprint evidence is accepted in court. But until now I never had access to an easy-to-use database of court cases.
Mike Bowers shared a release from the Wilson Center for Science and Justice at Duke Law, “New Database Documents a Century of Court Decisions on Forensic Expert Evidence Testimony.”
The fingerprint database can be accessed here.

Here’s an example of the case details for the (current) most recent record:
Case
Commonwealth v. Honsch, 22 N.E.3d 287 (Mass. 2024)
Year
2024
Jurisdiction
Massachusetts
Type of Proceeding
Appellate
Other fields
CourtSupreme Judicial Court of Massachusetts, Hampden
Expert Evidence Ruling Reversing or Affirming on AppealAdmitted
RulingCorrect to admit
Type of EvidenceFingerprint
Defense or Prosecution ExpertProsecution
Summary of Reasons for Ruling
The Commonwealth here presented two latent print analysts as experts. One multiple times that it was his “scientific opinion” that there were three latent prints that were “identified to” the palms of the defendant. The term “scientific” to describe his opinion “arguably verged on suggesting that the ACE-V process is more scientific than warranted,” and there was one instance in which Dolan testified without using the term “opinion.” The court concludes that there was no error because, “viewed as a whole,” his testimony was largely expressed in terms of an “opinion” and his testimony did not claim that the ACE-V process was infallible or absolutely certain.
On the other hand, Pivovar testified that she (i) “identified [a palm print from one of the garbage bags and the print of the defendant’s left palm] as originating from the same source”; (ii) “identif[ied] [another latent print] and the right palm print of [the defendant] as being the same, they originated from the same source”; and (iii) “identif[ied] the [third latent print] as originating from the same source as the right palm of [the defendant] that [she] compared it to.” Pivovar did not frame her testimony in terms of an “opinion” and expressed the identification of the defendant with certainty. This was error. However, the court concluded that Pivovar’s testimony did not likely influence the jury’s conclusion. Defense counsel countered the notion that individualization under the ACE-V methodology is infallible by cross-examining Pivovar on the subjectivity of latent print analysis, the fact that two prints are never identical, and a recent incident in which the Federal Bureau of Investigation erroneously identified a suspect based on an incorrect latent print analysis. The defendant also presented an expert detailing the risks of cognitive bias in latent print analysis. Additionally, the Commonwealth’s other latent print examiner, Dolan, testified as to the same findings as Pivovar. If Pivovar’s testimony had been properly framed as an opinion, there still would have been strong evidence that the prints found at Elizabeth’s crime scene originated from the defendant. Thus, even though we determine that Pivovar’s testimony was erroneously presented as fact, the error did not create a substantial likelihood of a miscarriage of justice.
Admissibility StandardLanigan-Daubert
Lower Court HearingN
Discussion of 2009 NAS ReportY
Discussion of Error Rates or ReliabilityN
Frye RulingN
Limiting Testimony RulingN
Language Imposed by Court to Limit TestimonyN
Ruling Based in Prior PrecedentY
Daubert FactorsN
Ruling on Qualifications of ExpertN
Ruling on 702(a)N
Ruling on 702(b)N
Ruling on 702(c)N
Ruling on 702(d)N
Notes—
Good resource to keep in mind.
A Live Soul Performance

Some of you knew these deepfake thoughts were coming. Might as well finish side one.

When we last met, I had discussed the other two tracks from side one of Elton John’s “Goodbye Yellow Brick Road.” Of course albums no longer have sides, but these three tracks/four songs give an idea of the breadth of Elton John’s first double album.
But this isn’t merely a music review. It also has to satisfy an Important Purpose. So this post about “Bennie and the Jets” will talk about…deepfakes.
Is it live?
After all the negativity that started the album, it was time for a little joy.
A happy song about a band.
About fans who read things in magazines.
All topped off by Elton’s charged performance in front of a live, cheering audience.
Um…no.
While Elton John has given many live performances, the recording of “Bennie and the Jets” is not one of them.
“Elton’s producer Gus Dudgeon wanted a live feel on this recording, so he mixed in crowd noise from a show Elton played in 1972 at Royal Festival Hall. He also included a series of whistles from a live concert in Vancouver B.C., and added hand claps and various shouts.”
But in retrospect, I can’t imagine the song as a straight studio recording. Dudgeon was right: it HAD to sound live.
And that “live” performance yielded a bigger surprise…and Reginald Dwight was most surprised of all.
Reginald Dwight, soul god
For those who don’t know who Reginald Dwight is, he was born in 1947 in an English town. A shy boy whose parents divorced in his teens, the most notable aspect of his life was his piano talent. He obviously wasn’t going to become a banker as his father originally intended.
Oh, and one more thing. Dwight was Caucasian. And all of his reinventions, including his adoption of the stage name Elton John, wasn’t going to alter that.
But Elton was pretty fly for a white guy. Worked his way up to musical ladder until he achieved success on his own. First with some notable performances, then some hit albums, then some number ones.
Reg could not have predicted what happened next. But first, let’s examine the relationship between “Bennie” and its album predecessor.
“When Elton recorded “Bennie And The Jets,” MCA, his label, wanted to make the song a single. Elton disagreed vociferously. His pick was “Candle In The Wind”…”
What persuaded Elton to change his mind…at least in the North American market?
“But Elton was swayed when “Bennie And The Jets” started doing well on Detroit R&B radio.”
Yes, R&B. “Bennie and the Jets” reached #15 on Billboard’s R&B charts. Which both pleased and amused Elton.
“What am I going to do on my next American tour? Play the Apollo for a week, open with ‘Bennie,’ and then say, ‘Thanks, you can all go home now.'”
If only there were a forum where he could play a single song for a large black audience…
Don Cornelius was all too happy to provide the forum.
Elton John wasn’t the first white artist to perform on Soul Train, but he was one of the few.
Technically this wasn’t a deepfake; Elton John didn’t pretend to be black. But he clearly absorbed some distinct musical influences: Little Richard, Ray Charles, Aretha Franklin, Fats Domino, Otis Redding, Nina Simone, Marvin Gaye, Wilson Pickett, James Brown, Stevie Wonder, The Temptations, Martha Reeves, Clyde McPhatter, and Sam Cooke. (Google Gemini helped me assemble this list.)
And he wasn’t a one hit wonder. Subsequent Philadelphia-influenced songs “Philadelphia Freedom” and “Mama Can’t Buy You Love” also made the R&B top 40.
Compare with Mick Jagger, who rarely made the R&B charts either as a Rolling Stone or as a solo artist. “Miss You” did, but Jagger’s highest placement was when he guested on the Jacksons’ “State of Shock.”
Repurposing Track 2 (Song 3)
I previously posted an unedited rumination on Elton John’s “Funeral For A Friend”/“Love Lies Bleeding” that also discussed digital asset taxonomies.
This post looks at the following song on the album “Goodbye Yellow Brick Road” and will also discuss identity and repurposing.
And I promise it will be shorter.
Who was “Candle in the Wind” REALLY about?
After the early death of Janis Joplin, Clive Davis referred to her as a “candle in the wind.”
And the phrase stuck with lyricist Bernie Taupin.
Because the phrase applied to so many troubled live fast die young types. Joplin’s own death was popularly linked with the deaths of Jimi Hendrix and Jim Morrison. And the phrase fit many others.
Including Norma Jeane Mortenson.
By the time lyricist Taupin was done with Mortenson, and his songwriting partner Elton John had added music to create “Candle in the Wind,” millions were convinced that Taupin was a Marilyn Monroe fanatic.
He wasn’t, but lines like “the young man in the 22nd row” certainly gave that impression.
But then came Farm Aid IV.
Ryan White
Farm Aid emerged from a desire to do for American farmers what prior efforts had done for people in Bangladesh and Ethiopia. And it wasn’t only for the Willie Nelsons, John Mellencamps, and Neil Youngs of the world. Elton John showed up by surprise at Farm Aid 4, with a special dedication.
“This one’s for Ryan.”
While Ryan White’s battle with AIDS was not haunted by demons like Monroe and the others, his death the next day was also untimely.
And one more repurposing
A few years later, for a grieving United Kingdom, Bernie Taupin altered the lyrics to the original song, and Elton John performed a tribute to his deceased friend Princess Diana.
And you thought “Funeral For A Friend”/“Love Lies Bleeding” was dark. “Candle in the Wind” is directly linked to four deaths—Janis Joplin, Marilyn Monroe, Ryan White, and Princess Diana—and indirectly linked to others.
I need something more cheerful…
A Lengthy Musical Digital Asset Taxonomy Discussion

Sometimes I write pieces that cover multiple topics, in this case both a technical analysis of digital asset taxonomies and classifications in a multi-faceted sense, and a musical analysis of the multi-faceted genres present in a single song. Whoops, two songs. (One track.)
And it all started with a single question.
Why does my Google Lyria-generated “biometric product marketing expert” song include a reference to “digital taxonomy”?
Because the source picture used to generate the song is not exclusively biometric in nature.

If you look in the lower right corner of the picture you can see a reference to digital asset taxonomy, a reference to a Bredemarket client that specializes in Adobe Experience Manager implementations.
Which brings us to Spotify.
Building the perfect Spotify playlists
Every month without fail I build at least one Spotify playlist for my listening pleasure. Normally these are a mixture of different decades and genres, all thrown together.
Saturday (February 21) I thought I’d be more thematic and create multiple playlists sorted by genre. So far I’ve created four:
- Dance, including the Andrea True Connection and Britney Spears.
- Electronic, including Kraftwerk and Röyksopp.
- Folk, including the Brothers Four and R.E.M.
- Punk, including Public Image Ltd. and Hole.
I tried to stay away from traditional categories such as country and disco, and didn’t try to distinguish between punk and hardcore, or genre and NEO-genre.
And I recognize that artists can span multiple genres. Some Devo songs are in my electronic playlist, others are in my punk playlist, and when I get to “Disco Dancer” it won’t go in either.
Which brings us to Elton John.
Building the imperfect digital asset taxonomy
Elton John’s career has spanned multiple genres. The bespectacled piano player has covered simple love songs, energetic power trios (17-11-70), bombastic orchestral episodes, crocodile rock, an island girl, and everything else. And that’s just in his first decade, before he became Disney soundtrack guy.
However, in most cases Elton, Bernie Taupin, and his other collaborators would stick with a particular genre for an entire song. Because that’s what good product marketers do: stick to a single message. Bad product marketers like me tend toward multiple message overload…I seem to have strayed from my point. *** EDIT THIS LATER
But perhaps you noticed the music I incorporated here.
How do you taxonomize THIS digital asset?
1973 in music
Before I describe the problem, let me set the scene.
- “Goodbye Yellow Brick Road” was the second of two albums that Elton John released in 1973. It was a sprawling double album.
- Elton’s predecessor album, “Don’t Shoot Me I’m The Only Piano Player,” was a number one album with a number one single, the aforementioned “Crocodile Rock.” The album also included the popular song “Daniel” and a character piece (in the Randy Newman tradition) “Texan Love Song.” (Lyricist Bernie Taupin often courted controversy.)
- But much was going on outside the pop star world that Elton John seemingly occupied. Progressive music was reaching its peak. While Elton’s first 1973 album rhapsodized on elderberry wine and backed away from the Paul Buckmaster arrangements, 1973 saw releases from Emerson Lake and Palmer, Genesis, Jethro Tull, King Crimson, and Yes. Oh, and an album by Pink Floyd entitled “Dark Side Of The Moon.” When I asked Google Gemini about 1973 progressive albums, it replied in part, “If you enjoy odd time signatures and 20-minute compositions, 1973 is your playground.”
- However, music is governed by Newton’s Third Law of Motion, and some definitely anti-progressive works were just starting to appear. The New York Dolls released an album, and underground recordings were circulating of a band called The Modern Lovers.
- A significant portion of American teenagers didn’t care about any of this. For them, the ONLY album of importance was Led Zeppelin’s “Houses of the Holy.”
Side one of four, track one, songs one and two
Which brings us to “Funeral For A Friend”/“Love Lies Bleeding.” Technically a two-song medley, but distributed (both physically and electronically) as a single asset.
Elton had tons of fans who were all too happy to rush out, slap $9.98 on the counter to buy “Goodbye Yellow Brick Road” upon its release, and plunk side one of the first record on their turntables.
Time to listen
I suspect that the “WTF” acronym was invented in November 1973.
Because the listeners weren’t hearing “the only piano player.”
And they weren’t hearing a Paul Buckmaster-conducted orchestra.
They were hearing an ARP 2500 synthesizer programmed and performed by David Hentschel.
You couldn’t hear a recognizable piano until the 1:40 mark of the song. Slowly you hear Dee, Nigel, and Davey, and the song slowly (but not completely) transitions away from the Hall of the Progressive Masterpiece in the Court of the Multi-Coloured Bespectacled Lunatic on the Top of the Charts. (And no, “lunatic” is not too strong here, since this song falls between Elton John’s known suicide attempts in 1968 and 1975.)
Then, after the band (augmented by Hentschel) brings “Funeral for a Friend” to an energetic conclusion, the piano player transitions to the second song at the 5:22 mark. And Elton, who has been silent all this time, finally sings.
And time to reflect
Let’s review, shall we?
- Although the tone is dark with themes of breakup and demise, portions of this sound like a typical Elton John pop song.
- But before that it begins with sounds that made American teenagers wondered if they had picked up a Yes album by mistake.
- And while few portions of the songs are minimal like Mr. Richman, or include towering solos like Mr. Page, parts would have fit well into a New York studio performance three years earlier. And Elton at his best could outdress the Dolls.
That was fun. Now comes the challenge.
How do you classify THIS?
I’ve already implicitly noted that music classification is a tricky affair.
Take “MacArthur Park,” a song recorded by everyone from Richard Harris to Waylon Jennings to Donna Summer. There are over 200 versions of the song spanning multiple genres. And composer Jimmy Webb is challenging to classify.
Now look at Elton’s song and my four playlists.
The track isn’t folk, dance, or punk.
But is it electronic? Portions are decidedly NOT.
Multi-faceted
You could cheat and place it in two (or more) classifications. Heather Hedden addresses faceted classification:
“The idea of faceted classification as a superior alternative to traditional hierarchical classification, whereby an item (such as book or article) can be classified in multiple different ways instead of in just a single classification class/category, is not new. The first such faceted classification was developed and published by mathematician/librarian S.R. Ranganathan in 1933, as an alternative to the Dewey Decimal System for classifying books, called Colon Classification (since the colon punctuation was originally used to separate the multiple facets).”
A taxonomy, however, is different—ideally:
“[F]aceted taxonomies should…ideally be mutually exclusive, in contrast to the principle of faceted classification…”
My solution
Returning to my Spotify playlist problem:
- I could simply place the song in multiple playlists: for example, an electronic playlist and some type of guitar/rock/whatever playlist.
- Or I could create a single hyphenated playlist, such as an electronic-guitar playlist. (Many Depeche Mode songs, beginning with “Route 66,” would be ideal here.)
For now I followed neither option, but added “Funeral for a Friend”/“Love Lies Bleeding” into my existing electronic playlist (because it starts electronically) and nowhere else.
Although I could change my mind later.
And there are other songs on the album…
