Sadly the question “why would a robot fish?” was shared in a private Facebook group, so I cannot share the entire question with you. But I can share my response.
“Some humans don’t fish for food, but for relaxation. But if robots need downtime, it doesn’t have to be at a stream with a pole.”
After thinking, I composed the prompt for the Google Gemini picture that illustrates this post.
“Create a realistic picture of a robot by a stream in the woods, fishing. The eyes and other parts of the robot’s head indicate that its internal controls are in maintenance mode, or that the robot is ‘relaxing.’”
My own content creation process with Bredemarket includes a “sleep on it” step which lets my brain reset before taking a fresh look at the content.
The generative AI equivalent is to take the output from the initial prompt, start a new independent chat, and write a second prompt to re-evaluate the output of the first prompt.
Another topic raised by Nadaa Taiyab during today’s SoCal Tech Forum meeting was ambient clinical intelligence. See her comments on how AI benefits diametrically opposing healthcare entities here.
There are three ways that a health professional can create records during, and/or after, a patient visit.
Typing. The professional has their hands on the keyboard during the meeting, which doesn’t make a good impression on the patient.
Structured dictation. The professional can actually look at the patient, but the dictation is unnatural. As Bredebot characterizes it: “where you have to speak specific commands like ‘Period’ or ‘New Paragraph.’”
“Ambient clinical intelligence, or ACI, is advanced, AI-powered voice recognizing technology that quietly listens in on clinical encounters and aids the medical documentation process by automating medical transcription and note taking. This all-encompassing technology has the ability to totally transform the lives of clinicians, and thus healthcare on every level.”
Like any generative AI model, ambient clinical intelligence has to provide my four standard benefits: accuracy, ease of use, security, and speed.
Accuracy is critically important in any health application, since inaccurate coding could literally affect life or death.
Ease of use is of course the whole point of ambient clinical intelligence, since it replaces harder-to-use methods.
Security and privacy are necessary when dealing with personal health information (PHI).
Speed is essential also. As Taiyab noted elsewhere in her talk, the work is increasing and the workforce not increasing as rapidly.
But if the medical professional and patient benefit from the accuracy, ease of use, security, and speed of ambient clinical intelligence, we all win.
This is definitely an experiment. When I started, I had no idea how it would turn out. In the end I’m fairly satisfied with how NotebookLM repurposed my blog post as a YouTube video, but there were definitely some lessons learned to apply in future repurposing.
Ahref’s best way to get your product listed on LLMs
As we all know, there has been a partial shift from search engine optimization to answer engine optimization. The short version is that content performs well when it answers a question that someone proposes to a large language model (LLM) such as Google Gemini or ChatGPT.
So how do we optimize our content for LLMs?
Yes, I know I could have asked an LLM that question, but I still do some old school things and attended a webinar instead.
I live-blogged Wednesday’s webinar, hosted by the Content Marketing Institute and sponsored by Ahrefs. The speaker was Ahref’s Ryan Law, the company’s Director of Content Marketing. As is usual with such affairs, the webinar provided some helpful information…which is even more helpful if you use Ahref’s tools. (Funny how that always happens. The same thing happens with Bredemarket’s white papers.)
One of the many topics Law addressed was the TYPE of content that resonates most with LLM inquirers. Law’s slide 20 answered this question.
“LLMs LOVE YOUTUBE”
Law then threw some statistics at us.
“YouTube has fast-become the most cited domain in AI search:
1 in AI Overviews
1 in AI Mode
2 in ChatGPT
2 in Gemini
2 in Copilot
2 in Perplexity”
So even if it isn’t number 1 on some of the engines themselves, it’s obviously high, and very attractive to inquirers.
But what of people like me who prefer the portability of text? It’s easier to quote from text than it is to take a short snippet of a video.
YouTube covers that also, since it automatically creates a transcript of every word spoken in a YouTube video.
But…
Bredemarket’s problem
…most of the videos that Bredemarket has created have zero or few spoken words, which kinda sorta makes it tough to create a transcript.
For example, the “Landscape (Biometric Product Marketing Expert)” video that I frequently share on the Bredemarket blog for some odd reason is not only on WordPress, but also on YouTube. However, it has zero spoken words, so therefore no transcript.
“Yo, I’m the outlaw of this country sound, dropping rhymes that shake the ground.”
But I do have some YouTube videos with more extensive transcripts. And one of them suggests a possible solution to my desire to provide YouTube videos to LLMs.
Using Google’s NotebookLM to create videos from non-copyrighted material
A still from Bredemarket’s movie “Inside the EBTS.” Are you jealous, Stefan Gladbach?
The material wasn’t authored by me, but by the U.S. Federal Bureau of Investigation. (Which meant that it wasn’t copyrighted.)
What was it?
Version 11.3 of the Electronic Biometric Transmission Specification (EBTS).
A few of you are already laughing.
For those who aren’t, the EBTS is a fairly detailed standard dictating how biometric and biographic data is exchanged between the FBI’s Next Generation Identification (NGI) system and other federal, state, and local automated biometric identification systems.
As a standard, it’s not as riveting as a Stephen King novel.
And once I uploaded the movie to YouTube, YouTube created a transcript.
First 21 seconds of the YouTube transcript of the video above.
So this potentially helps Bredemarket to be visible.
And if I want to follow Ryan Law’s advice and repurpose my content for YouTube, NoteBookLM provides a method to do it.
Using Google’s NotebookLM to create videos from MY copyrighted material
Time for an experiment, the goal of which is to convert a Bredemarket blog post into a video with a minimum amount of effort.
NotebookLM can use either files or web links as source material for videos, so the easiest method to create my video is as follows:
Paste the web link to the blog post into NotebookLM.
Instruct NotebookLM to create a “Video Overview” from this single piece of content.
My blog post of choice is my post from earlier today, “Government Anti-Fraud Efforts: They’re Still Siloed.” The post contains a Gemini AI image of silos on the National Mall in Washington DC (inaccurately displaying the U.S. Capitol as NORTH of the Washington Monument). It also includes my text as well as links to outside sources such as the initial draft of H.R. 7270.
So let’s see what NotebookLM gives us.
The first thing that we get is Google’s summary of the content at the link.
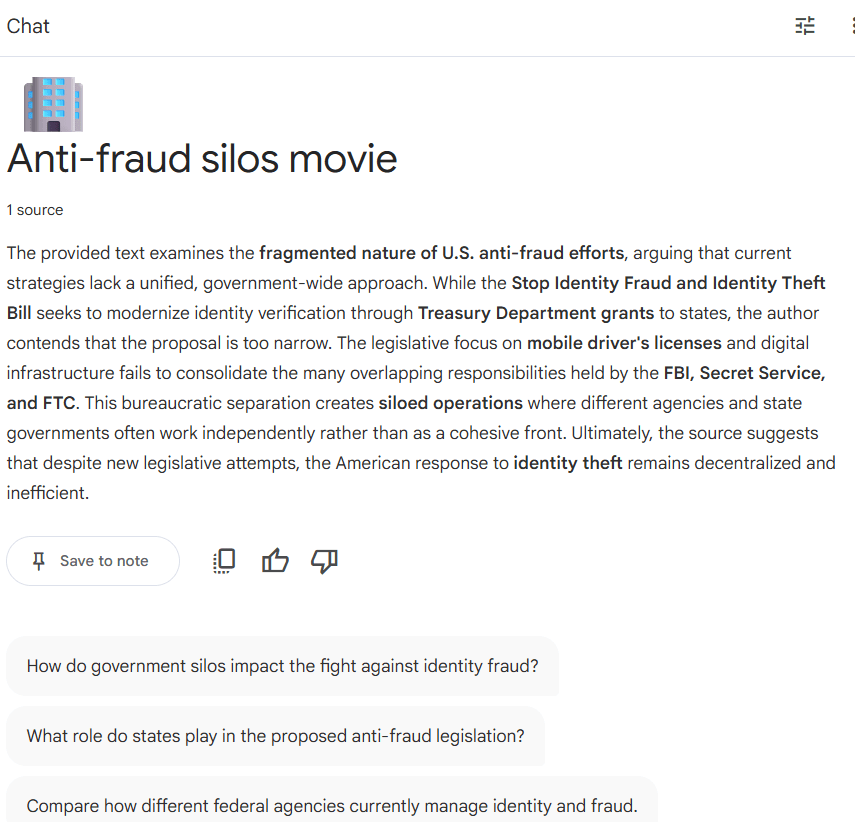
NotebookLM’s summary of the web link I provided.
“1 source
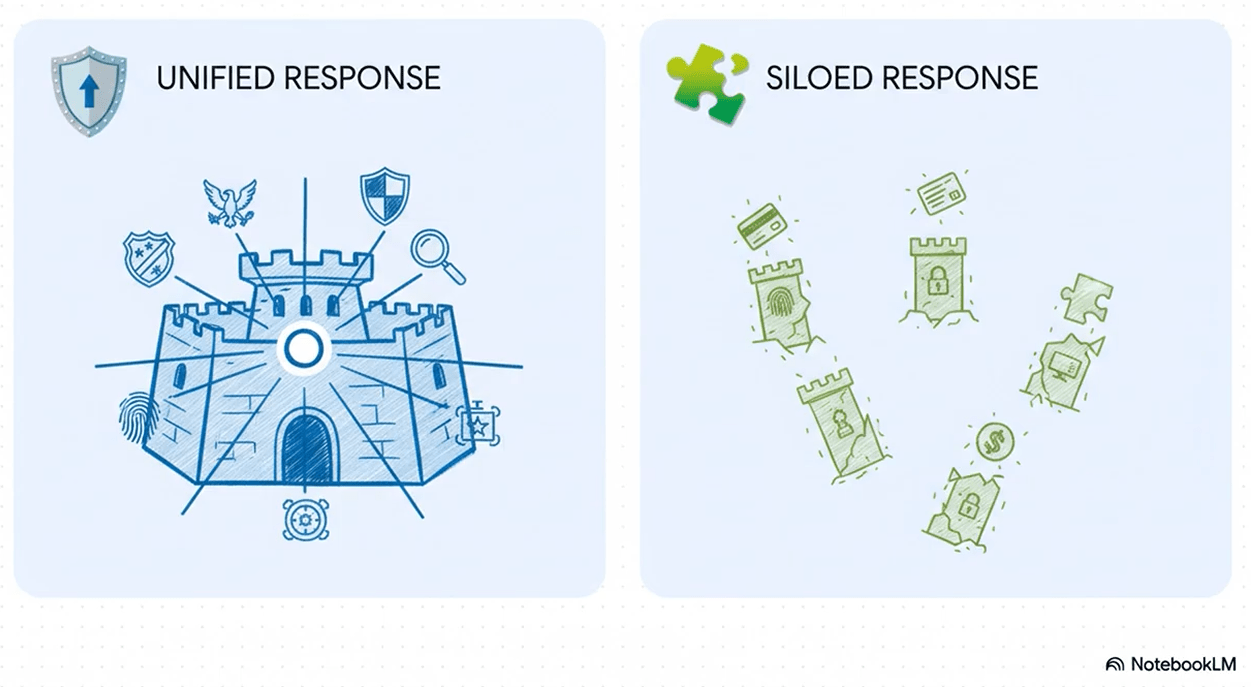
The provided text examines the fragmented nature of U.S. anti-fraud efforts, arguing that current strategies lack a unified, government-wide approach. While the Stop Identity Fraud and Identity Theft Bill seeks to modernize identity verification through Treasury Department grants to states, the author contends that the proposal is too narrow. The legislative focus on mobile driver’s licenses and digital infrastructure fails to consolidate the many overlapping responsibilities held by the FBI, Secret Service, and FTC. This bureaucratic separation creates siloed operations where different agencies and state governments often work independently rather than as a cohesive front. Ultimately, the source suggests that despite new legislative attempts, the American response to identity theft remains decentralized and inefficient.”
But that’s just text. Time to create the video overview.
After I cklicked the “Video Overview” button in the upper right.
A while later…
Even with relatively minimal content, video creation isn’t immediate. It has to shape the content into a narrative video, after all. Sadly I forgot to time the result, but I received this video, “A Tale of Two Threats,” within a half hour.
A Tale of Two Threats (WordPress version). Created by Google NotebookLM based upon “Government Anti-Fraud Efforts: They’re Still Siloed.”
As is par for the course with NotebookLM, the narration is self-generated in a viewer-friendly form (“let’s pop the hood”). And it used my source material as a basis to narrate the tale of the U.S. Government’s responses to the “two threats” of terrorism and fraud. As my original blog post noted, the two responses have been quite different.
The video then takes portions of the blog post, including the list of agencies that are NOT part of H.R. 7270, as well as my example of what could happen if the Secret Service’s mission is compromised because of what some other agency is doing.
But it DOESN’T take other portions of my blog post, such as the potential shuttering of the Consumer Financial Protection Bureau, my reference to “evil Commie Chinese facial recognition algorithms,” or my graphic of silos on the Mall. NotebookLM generated its own cartoon graphics instead.
This image didn’t make the video, even though Google created it.
The final step
The first place where I uploaded the video was WordPress, so I could include it in this blog post. I’ll probably upload it to other places, but the second target is YouTube.
A Tale of Two Threats (YouTube version). Created by Google NotebookLM based upon “Government Anti-Fraud Efforts: They’re Still Siloed.”
And yes, there is a transcript. Although it took a few minutes to generate. So now the bot’s text is out there for the LLMs to find.
First 24 seconds of the YouTube transcript of the video above.
Grading the experiment
I’ll give the experiment a B. It’s not really MY video, but it encapsulates some of my views.
NotebookLM users need to remember that when it creates audio and video content, it doesn’t simply parrot the source, but reshapes it. You may remember the NotebookLM 20-minute “Career Detective” podcast of my resume, in which a male and female bot talked about how great I am. My blog post was processed similarly.
If I want something that better promotes Bredemarket to LLM users, I need to shape the blog post to do the following:
Address some question that the LLM user asks.
Include text that promotes Bredemarket as the solution to the inquirer’s problems.
Anyway, I’ll keep these tips in mind when writing…and repurposing…future blog posts.
“Global consulting giant Deloitte has agreed to refund a part of its $440,000 fee to the Australian government after admitting to using generative AI tools in a report assessing the government’s “Future Made in Australia” initiative….The final report, released in July, was found to contain several significant errors — including academic citations referencing individuals who do not exist and a fabricated quote from a Federal Court judgment…”
So how does Bredemarket ensure that MY consulting projects deliver what you need?
By regular feedback cycles after I have asked my initial questions.
The Seven Questions I Ask.
After I’ve scoped the project and created my first draft, it’s your turn to provide input.
When properly scoped, almost all projects only need minor redirection at worst, or perhaps only a few tweaks.
In a very few instances clients have accepted my first drafts as the final copy. Sometimes this relieves me, sometimes it worries me. (Did the client read it?)
But a quick turnaround is the desired goal. You need to get this content out to your prospects, and I need to rescue you (or someone else) in another project.
One of my clients has scheduled a meeting with me at 9:30 via Zoom.
And Zoom, like anything else, is now AI-powered.
Which means nothing.
Zoom AI helps me prepare for the meeting with buttons such as “What are some meeting icebreakers?”
I had to see this. And after reading the material below, I will never trust Zoom AI again. My client and I have work to do.
Here are some meeting icebreaker ideas: 1. Two Truths and a Lie: Each person shares two true statements about themselves and one false statement. The others have to guess which one is the lie. 2. Human Bingo: Create bingo cards with different traits, characteristics, or interests (e.g., “has traveled to another country”). Each person needs to find someone who fits each description and get them to sign the corresponding square. 3. Word Association Game: Have each person say a word related to a specific topic (e.g., “teamwork”). The next person has to say a word associated with the previous word. 4. Scavenger Hunt: Create a list of items or challenges that people need to complete during the meeting (e.g., “find someone wearing the same color shirt as you”). 5. Would You Rather: Present two difficult choices and ask each person which one they prefer (e.g., “would you rather have the ability to fly or be invisible?”). 6. One-Word Introduction: Ask each person to come up with a word that describes themselves, such as “creative” or “adventurous.” 7. The Name Game: Have each person introduce themselves and share a unique fact or interest that starts with the same letter as their name. 8. Team Trivia: Prepare a short quiz with questions related to the team or company. 9. Creative Show and Tell: Ask each person to bring an object that represents something about themselves or their work, and have them explain why they chose it.
You know what the problem is with these AI medical bots? They hallucinate and do inaccurate stuff. When you use humans for your medical needs, they’re gonna get it right.
The company that replaced a steel mill with a hospital is in a bit of trouble with the U.S. Department of Justice, in an action started under the Biden Administration and concluded under the Trump Administration.
“Affiliates of Kaiser Permanente, an integrated healthcare consortium headquartered in Oakland, California, have agreed to pay $556 million to resolve allegations that they violated the False Claims Act by submitting invalid diagnosis codes for their Medicare Advantage Plan enrollees in order to receive higher payments from the government….
“Specifically, the United States alleged that Kaiser systematically pressured its physicians to alter medical records after patient visits to add diagnoses that the physicians had not considered or addressed at those visits, in violation of [Centers for Medicare & Medicaid Services (CMS)] rules.”
Now of course you can code a bot to perform fraud, but it’s easier to induce a human to do it.
If your security software enforces a “no bots” policy, you’re only hurting yourself.
Bad bots
Yes, there are some bots you want to keep out.
“Scrapers” that obtain your proprietary data without your consent.
“Ad clickers” from your competitors that drain your budgets.
And, of course, non-human identities that fraudulently crack legitimate human and non-human accounts (ATO, or account takeover).
Good bots
But there are some bots you want to welcome with open arms.
Such as the indexers, either web crawlers or AI search assistants, that ensure your company and its products are known to search engines and large language models. If you nobot these agents, your prospects may never hear about you.
Buybots
And what about the buybots—those AI agents designed to make legitimate purchases?
Perhaps a human wants to buy a Beanie Baby, Bitcoin, or airline ticket, but only if the price dips below a certain point. It is physically impossible for a human to monitor prices 24 hours a day, 7 days a week, so the human empowers an AI agent to make the purchase.
Do you want to keep legitimate buyers from buying just because they’re non-human identities?
(Maybe…but that’s another topic. If you’re interested, see what Vish Nandlall said in November about Amazon blocking Perplexity agents.)
Nobots
According to click fraud fighter Anura in October 2025, 51% of web traffic is non-human bots, and 37% of the total traffic is “bad bots.” Obviously you want to deny the 37%, but you want to allow the 14% “good bots.”
Nobot policies hurt. If your verification, authentication, and authorization solutions are unable to allow good bots, your business will suffer.
As you may know, I’ve often used Grok to convert static images to 6-second videos. But I’ve never tried to do this with an occluded face, because I feared I’d probably fail. Grok isn’t perfect, after all.
Facia’s 2024 definition of occlusion is “an extraneous object that hinders the view of a face, for example, a beard, a scarf, sunglasses, or a mustache covering lips.” Facia also mentions the COVID practice of wearing masks.
Occlusion limits the data available to facial recognition algorithms, which has an adverse effect on accuracy. At the time, “lower chin and mouth occlusions caused an inaccuracy rate increase of 8.2%.” Occlusion of the eyes naturally caused greater inaccuracies.
So how do we account for occlusions? Facia offers three tactics:
But those acronyms aren’t enough, so we’ll add one more.
At the 2025 Computer Vision and Pattern Recognition conference, a group of researchers led by Pratheba Selvaraju presented a paper entitled “OFER: Occluded Face Expression Reconstruction.” This gives us one more acronym to play around with.
Here’s the abstract of the paper:
“Reconstructing 3D face models from a single image is an inherently ill-posed problem, which becomes even more challenging in the presence of occlusions. In addition to fewer available observations, occlusions introduce an extra source of ambiguity where multiple reconstructions can be equally valid. Despite the ubiquity of the problem, very few methods address its multi-hypothesis nature. In this paper we introduce OFER, a novel approach for singleimage 3D face reconstruction that can generate plausible, diverse, and expressive 3D faces, even under strong occlusions. Specifically, we train two diffusion models to generate a shape and expression coefficients of face parametric model, conditioned on the input image. This approach captures the multi-modal nature of the problem, generating a distribution of solutions as output. However, to maintain consistency across diverse expressions, the challenge is to select the best matching shape. To achieve this, we propose a novel ranking mechanism that sorts the outputs of the shape diffusion network based on predicted shape accuracy scores. We evaluate our method using standard benchmarks and introduce CO-545, a new protocol and dataset designed to assess the accuracy of expressive faces under occlusion. Our results show improved performance over occlusion-based methods, while also enabling the generation of diverse expressions for a given image.
Cool. I was just writing about multimodal for a biometric client project, but this is a different meaning altogether.
In my non-advanced brain, the process of creating multiple options and choosing the one with the “best” fit (however that is defined) seems promising.
Although Grok didn’t do too badly with this one. Not perfect, but pretty good.
The U.S. National Institute of Standards and Technology (NIST) says that we should…drumroll…adopt standards.
Which is what you’d expect a standards-based government agency to say.
But since I happen to like NIST, I’ll listen to its argument.
“One way AI can prove its trustworthiness is by demonstrating its correctness. If you’ve ever had a generative AI tool confidently give you the wrong answer to a question, you probably appreciate why this is important. If an AI tool says a patient has cancer, the doctor and patient need to know the odds that the AI is right or wrong.
“Another issue is reliability, particularly of the datasets AI tools rely on for information. Just as a hacker can inject a virus into a computer network, someone could intentionally infect an AI dataset to make it work nefariously.”
So we know the risks, but how do we mitigate them?
“Like all technology, AI comes with risks that should be considered and managed. Learn about how NIST is helping to manage those risks with our AI Risk Management Framework. This free tool is recommended for use by AI users, including doctors and hospitals, to help them reap the benefits of AI while also managing the risks.”